
 4000积分,双肩包*5
4000积分,双肩包*5
大模型的风潮还未停歇,国内大模型的研发也正如火如荼地开展着。你试用过哪些大模型呢?你觉得哪一款产品最适合开发者呢?你有想过训练出自己的大模型吗?这不就来了!
通义千问开源!阿里云开源通义千问70亿参数模型,包括通用模型Qwen-7B和对话模型Qwen-7B-Chat,两款模型均已上线ModelScope魔搭社区,开源、免费、可商用。点击链接,立即开启模型开源之旅:https://modelscope.cn/models/qwen/Qwen-7B/summary
本期话题:
1、您是否已经体验了通义千问开源模型?您是如何使用它的?
2、开发者如何看待大模型开源呢?你会如何改造它?
3、通义千问开源,你有什么想要聊的呢?
本期奖励:
截止8月13日24时,本话题下将选取5个幸运讨论用户,奖励双肩背包*1。

获奖规则:中奖楼层百分比为3%,13%,33%,63%,83%的有效留言用户可获得互动幸运奖。 如:活动结束后,回复为100层,则获奖楼层为100 3%=3,依此类推,即第3、13、33、63、83位回答用户获奖。如遇非整数,则向后取整。如:回复楼层为80层,则80 3%=2.4,则第3楼获奖。
注:楼层需为有效回答(符合互动主题),灌水/复制回答将自动顺延至下一层。话题讨论要求原创,如有参考,一律注明出处,否则视为抄袭不予发奖。获奖名单将于5个工作日内公布,礼品7个工作日内发放,节假日顺延。
本期有效活动时间内共收到81个回答,根据抽奖计算,获奖名单是:小七天、小周sir、Star时光、六月暴雪飞梨花、玥轩
我已经体验了通义千问开源模型。
直接在通义千问官网申请体验,收到邀请后可以在钉钉上接入通义千问模型。使用方法也很简单,只需要在聊天对话框中输入问题,通义千问就会对输入的问题进行回答。
开发者对大模型开源的态度是多样的,有些开发者认为开源可以促进模型的研究和应用,有些开发者则认为开源会导致模型的安全性和隐私受到威胁。
如果开发者想要改造大模型,首先需要对模型的结构和算法有深入的理解,以便能够针对特定的任务进行模型的调整和优化。此外,开发者还需要具备数据科学和机器学习的技能,以便能够处理大量的数据和进行模型的训练。最后,开发者还需要具备良好的编程技能,以便能够高效地实现和测试模型的修改。
总之,改造大模型需要开发者具备广泛的技能和知识,但是通过开源,开发者可以获得更多的资源和工具来帮助他们实现这一目标。
通义千问是一个非常有前景的开源人工智能项目,它的目标是构建一个更加智能、高效、可靠的应用系统,为人类带来更好的服务和体验。
首先,通义千问的开源将会促进人工智能技术的发展和应用。通过开源,通义千问可以将自己的技术成果分享给更多的开发者,让更多的开发者参与到这个项目中来,共同推动人工智能技术的发展和应用。这将有助于提高人工智能技术的水平和效率,为人类带来更多的便利和效益。
其次,通义千问的开源将会促进人工智能产业的创新和发展。通过开源,通义千问可以将自己的技术成果转化为商业应用,推动人工智能产业的发展和创新。这将有助于提高人工智能产业的竞争力和创造力,为人类带来更多的惊喜和福利。
最后,通义千问的开源将会促进人工智能技术的普及和应用。通过开源,通义千问可以将自己的技术成果普及到更多的领域和行业,推动人工智能技术的普及和应用。这将有助于提高人工智能技术的认知度和应用范围,为人类带来更多的智慧和力量。
总之,通义千问的开源是一个非常有前景的发展方向,它将为人工智能技术的发展和应用带来更多的机遇和挑战。相信在未来的日子里,通义千问将会在人工智能领域中发挥更加重要的作用,为人类带来更多的惊喜和福利。
通义千问是阿里巴巴达摩院开发的一款超大规模语言模型。
在通义千问的体验界面,罗列着一些建议指令,比如“写一段电影脚本,讲一个北漂草根创业逆袭的故事”、“作为手机斗地主游戏的产品经理,该如何做成国内爆款”、“团队开发了一个对话机器人,给老板写邮件介绍”……
更细分的小学生作文、提纲、写诗等细分功能,其角色定义应该是一个‘AI改进工作效率的工具或助理’。
2021年,阿里先后发布国内首个超百亿参数的多模态大模型“通义-M6”以及号称“中文版GPT-3”的语言模型PLUG,为推动中国大模型研发和应用,阿里在“魔搭”社区上开源了超10个百亿参数的核心大模型。
本次推出的通义千问仍然是仅限于文字交互的单模态,并不支持ChatGPT和文心一言可以操作的图文转换。
相较于GPT-4最长2.4万单词的输入,通义千问的指令字数上限为1000字,通义千问对一些谐音梗等深度中文理解还有待进步。
8月3日周四,阿里云将70亿参数的通义千问模型开源,包括通用模型Qwen-7B和对话模型Qwen-7B-Chat。这两款模型均已上线国内首个“模型即服务”开放平台魔搭社区,开源、免费、可商用。
开源代码支持对Qwen-7B和Qwen-7B-Chat的量化,支持用户在消费级显卡上部署和运行模型。用户既可从魔搭社区直接下载模型,也可通过阿里云灵积平台访问和调用Qwen-7B和Qwen-7B-Chat,阿里云为用户提供包括模型训练、推理、部署、精调等在内的服务。
Qwen-7B是支持中、英等多种语言的基座模型,在超过2万亿token数据集上训练,上下文窗口长度达到8k。
Qwen-7B-Chat是基于基座模型的中英文对话模型,已实现与人类认知对齐。
如果开发者想开箱即用地调用Qwen-7b和Qwen-7b-chat,可通过阿里云模型API平台灵积来测试调用通义千问API。阿里云为用户提供包括模型下载、训练、部署、推理等在内的全方位服务。
无论是在C-Eval验证集上,还是在MMLU评测集上,Qwen-7B-Chat模型的zero-shot准确率均在同类对齐模型中表现较优。
通义千问7B预训练模型在多个权威基准测评中表现出色,中英文能力远超国内外同等规模开源模型,部分能力甚至“跃级”赶超12B、13B尺寸开源模型。
通义千问的开源后,阿里云成为国内首个加入大模型开源行列的大型科技企业。
今年4月的2023阿里云峰会上,阿里巴巴宣布向企业开放通义千问,企业可以调用通义千问的能力训练自己的大模型。
未来企业在阿里云上既可以调用通义千问的全部能力,也可以结合企业自身的行业知识和应用场景,训练自己的企业大模型。比如,每个企业都可以有自己的智能客服、智能导购、智能语音助手、文案助手、AI设计师、自动驾驶模型等。
众所周知,自然语言处理是人工智能领域的一个重要分支,也是近年来备受瞩目的领域之一。而通义千问开源模型作为自然语言处理领域的重要成就之一,近年来也引起了广泛的关注和讨论,那么接下来就来简单聊聊通义千问开源模型。
通义千问,是阿里云推出的一个超大规模的语言模型,功能包括多轮对话、文案创作、逻辑推理、多模态理解、多语言支持。能够跟人类进行多轮的交互,也融入了多模态的知识理解,且有文案创作能力,能够续写小说,编写邮件等。
2023年4月7日,“通义千问”开始邀请测试;4月11日,“通义千问”在2023阿里云峰会上揭晓;4月18日,钉钉正式接入阿里巴巴“通义千问”大模型。
其实,通义千问开源模型是近年来自然语言处理领域的一项重要成果,它是一个开源的中文问答系统,基于深度学习模型使用了大规模的语料库进行训练,它可以实现中文问答和智能客服等功能,相信很多人都已经在某些智能客服机器人上体验过它的威力了。
我也在自己的一个测试项目中集成智能客服的时候体验过这个模型,它有着非常优秀的问答能力,可以准确解答用户提出的问题。
此外,我在一些搜索引擎上也发现了通义千问开源模型的身影,当我输入某个关键词并提问时,它能够基本上给出准确的答案,这无疑大大提高了搜索的效率。
作为一名开发者,我非常欣赏大模型开源的形式。大模型开源是指将一些以往需要巨额计算成本才能训练出来的深度学习模型以开源的形式共享给开发者们,为他们提供了许多便利。相比于自己从头开始训练一个深度学习模型,使用大模型开源更为高效和省时,通过改进和调整这些模型,我们可以更快地实现自己的目标。
对于通义千问开源模型,我认为如果有机会改造它,我会尝试在文本生成方面进行一些改进。例如,翻译功能,这个模型也是可以实现的。通过将其应用于机器翻译,可以缩短翻译的时间,并大大提高翻译的准确率。
对于通义千问开源模型,我认为它不仅仅实现了在自然语言处理领域的突破,还为人工智能提供了更广阔的应用前景。它可以帮助企业建立更加智能化的客服系统和搜索引擎,也可以用于智能语音助手的开发。
但是作为一种技术,通义千问开源模型仍然存在一些问题。首先,这个模型的训练成本非常高,需要巨大的算力和时间。其次,模型的效果虽然已经十分优秀,但仍存在一定的误差率。以及对于一些复杂的问题,模型仍然难以给出准确答案。这些问题都需要我们不断努力和改进。
最后再来总结一下,通义千问开源模型是自然语言处理领域的一项重要成果,也为人工智能的应用提供了更广阔的前景。作为开发者,我们应该不断探索和改进这个模型,让它更加智能化和高效。同时,也让我们期待一下通义千问再创巅峰时刻!
1、您是否已经体验了通义千问开源模型?您是如何使用它的?
体验了Qwen-7B-Chat-Demo,整体速度和准确度还是非常高的。我会将其替代部分使用浏览器查询的场景,毕竟对话的方式,非常的便捷和高效。
2、开发者如何看待大模型开源呢?你会如何改造它?
开源大模型是机遇也是挑战。首先各大厂都在猛推自己的AI产品,从ChatGPT到文心一言,再到华为盘古,使用体验越来越好,作为后来者,开源必然是一条引流的好策略,能吸引更多开发者加入,丰富它。
3、通义千问开源,你有什么想要聊的呢?
开源大模型?所闻的国内第一家。OpenAI并不Open,很多开源的大模型都是国外的,所以我觉得通义千问开源,对国内的大模型环境意义非凡。特别是对开发者,门槛再次被拉低,这也就意味着可能加速全智能时代的到来!
开通了通义千问大模型, 用它来训练了 会议的语音识别, 发现针对 中英文混讲,很多英文的单词和学科术语 转换的错误率很高!
大模型开源可以让全球开发者参与模型的训练和使用, 有助于模型的精准度提升, 探索更多的技术可能, 我要根据我自己的需求来训练小范围专业的模型!
希望将来人人都可以参与模型训练, 构建自己的模型需求! 成本更低!
首先可以参考modelScope社区给出的使用文档,已经足够全面
https://modelscope.cn/models/qwen/Qwen-7B-Chat/quickstart
但在按照文档中步骤部署时,还是有些错误问题发生,可以搜索参考的解决方式不多,所以记录下来
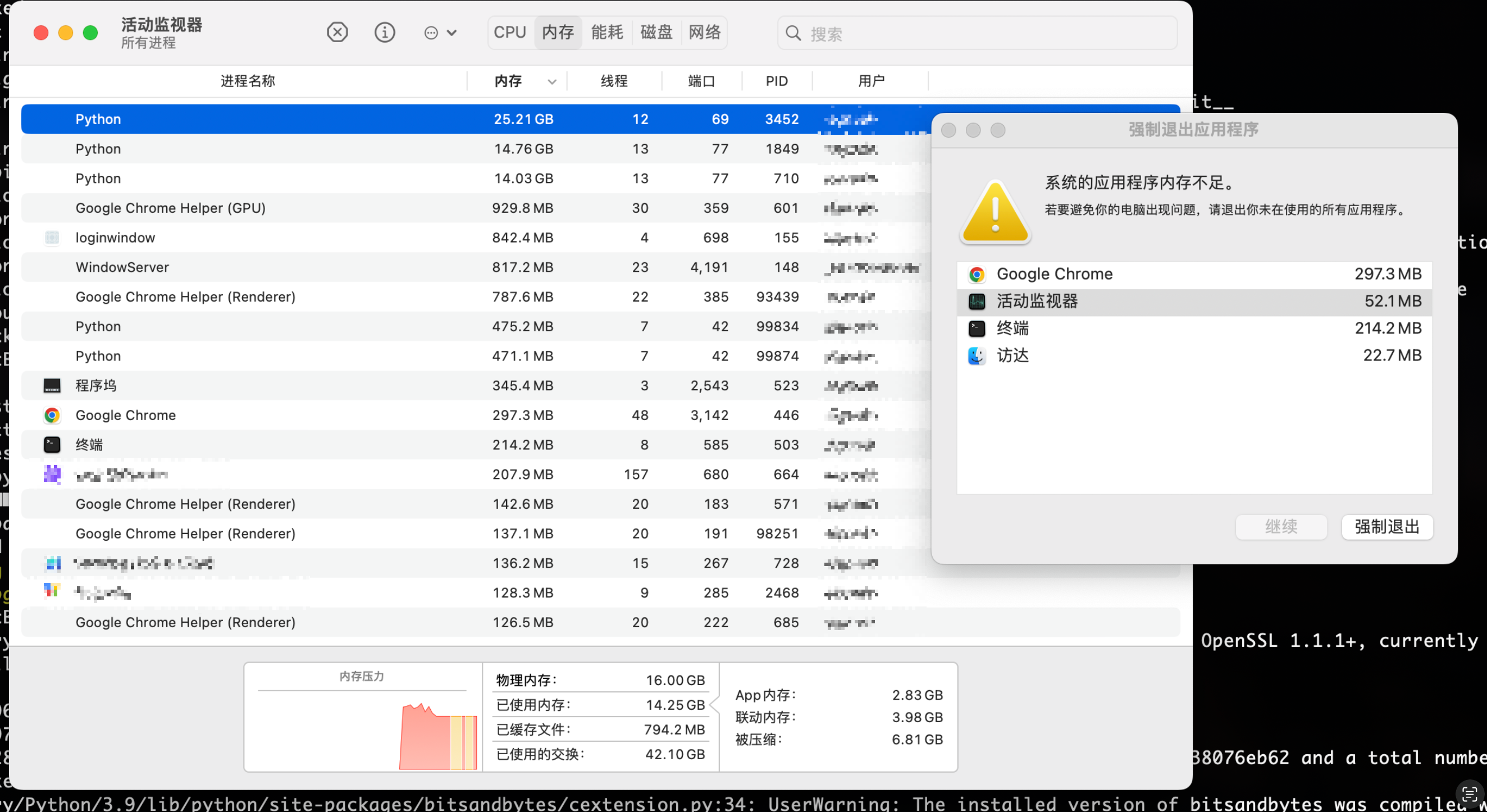
这里不太建议使用自己的笔记本部署通义千问模型,因为实在是太耗资源,我使用的M2芯片的MacBook Pro即使运行起来了,但模型回答一个问题都需要四五分钟的时间,内存全部占满,其他应用程序也都强制退出了。所以还是使用社区提供的免费资源,或者有更高配置的服务器来部署模型。而且期间还有各种问题,搜了很多github上的问答才解决,耗时耗力,这里就不记录了,很不推荐这种方式。
打开modelScope社区后,点击登录注册可以看到免费赠送算力的活动

注册完成后在对应模型里可以看到,随时都能启用的服务器

这里CPU环境的服务器勉强可以跑起来模型,但运行效果感人,而且配置过程中有各种问题需要修改,而GPU环境启动模型可以说是非常流畅,体验效果也很好
社区提供的服务器配置已经很高了,8核32G,但因为是纯CPU环境,启动过程中还是有些问题
第一行命令不需要运行,服务器已经自带了modelscope包

只需要新建一个Terminal窗口来执行第二条命令

直接运行文档提供的代码会报错,这里是因为纯CPU环境导致的

RuntimeError: "addmm_implcpu" not implemented for 'Half'Hide Error Details
RuntimeError: "addmm_impl_cpu_" not implemented for 'Half'
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[1], line 8
5 model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',device_map="auto", trust_remote_code=True,fp16 = True).eval()
6 model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat",revision = 'v1.0.5', trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
----> 8 response, history = model.chat(tokenizer, "你好", history=None)
9 print(response)
10 response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history)
File ~/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat/modeling_qwen.py:1010, in QWenLMHeadModel.chat(self, tokenizer, query, history, system, append_history, stream, stop_words_ids, **kwargs)
1006 stop_words_ids.extend(get_stop_words_ids(
1007 self.generation_config.chat_format, tokenizer
1008 ))
1009 input_ids = torch.tensor([context_tokens]).to(self.device)
-> 1010 outputs = self.generate(
1011 input_ids,
1012 stop_words_ids = stop_words_ids,
1013 return_dict_in_generate = False,
1014 **kwargs,
1015 )
1017 response = decode_tokens(
1018 outputs[0],
1019 tokenizer,
(...)
1024 errors='replace'
1025 )
1027 if append_history:
ValueError: The current device_map had weights offloaded to the disk. Please provide an offload_folder for them. Alternatively, make sure you have safetensors installed if the model you are using offers the weights in this format.Hide Error Details
ValueError: The current `device_map` had weights offloaded to the disk. Please provide an `offload_folder` for them. Alternatively, make sure you have `safetensors` installed if the model you are using offers the weights in this format.
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[2], line 5
2 from modelscope import GenerationConfig
4 tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',trust_remote_code=True)
----> 5 model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',device_map="auto", trust_remote_code=True,fp16 = True).eval()
6 model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat",revision = 'v1.0.5', trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
7 model.float()
File /opt/conda/lib/python3.8/site-packages/modelscope/utils/hf_util.py:98, in get_wrapped_class.<locals>.ClassWrapper.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
95 else:
96 model_dir = pretrained_model_name_or_path
---> 98 model = module_class.from_pretrained(model_dir, *model_args,
99 **kwargs)
100 model.model_dir = model_dir
101 return model
首先确保torch 2.0.1版本,然后在代码中添加这两行,即可运行
model.float()
offload_folder="offload_folder",
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
import datetime
print("启动时间:" + str(datetime.datetime.now()))
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',device_map="auto",offload_folder="offload_folder", trust_remote_code=True,fp16 = True).eval()
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat",revision = 'v1.0.5', trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
model.float()
print("开始执行:" + str(datetime.datetime.now()))
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
print("第一个问题处理完毕:" + str(datetime.datetime.now()))
response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history)
print(response)
print("第二个问题处理完毕:" + str(datetime.datetime.now()))
response, history = model.chat(tokenizer, "它有什么好玩的景点", history=history)
print(response)
print("第三个问题处理完毕:" + str(datetime.datetime.now()))
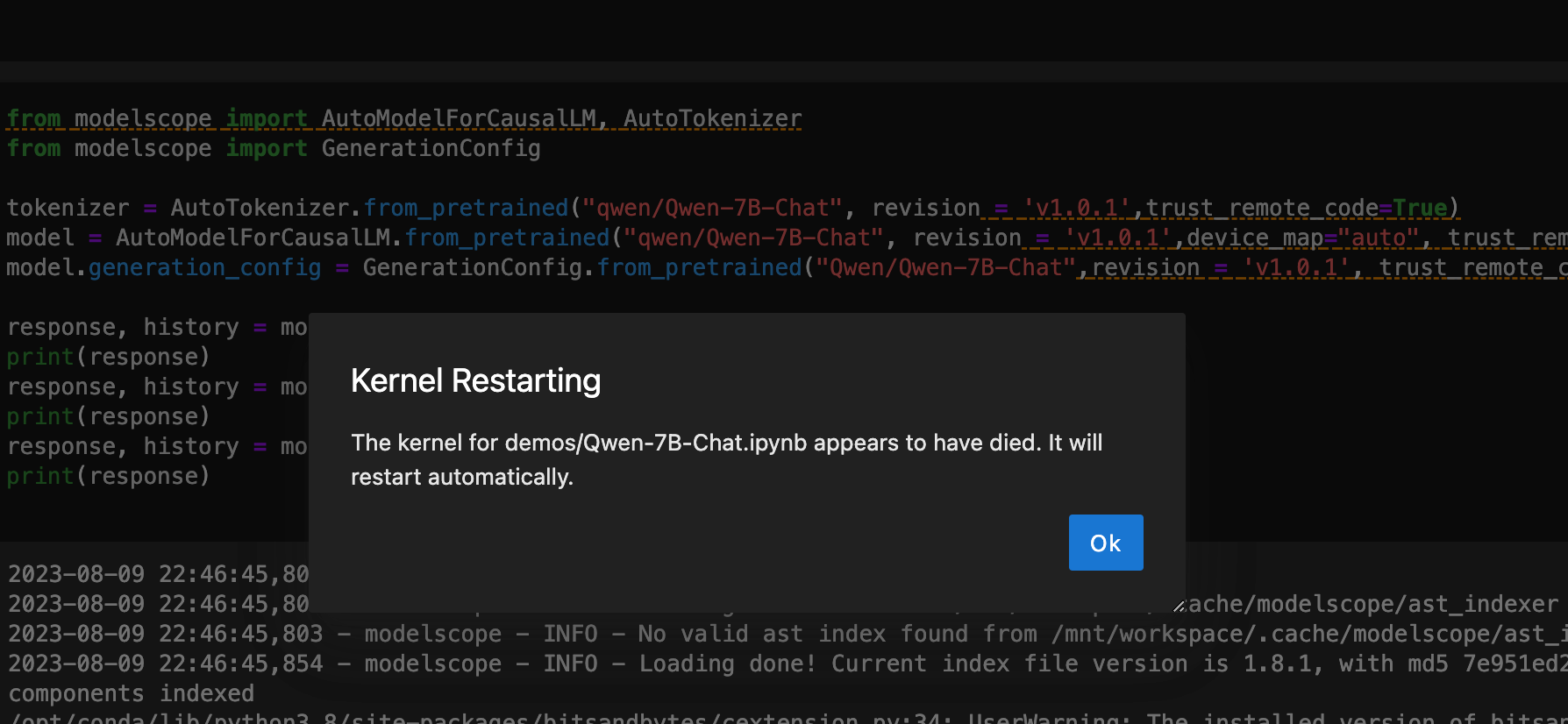
运行起来之后速度实在感人,没回答一个问题都需要 5 分钟左右,还有一定概率直接启动失败

启动模型过程中会出现这种报错,点击OK重新执行就好了,可能是服务器负载太高

1、您是否已经体验了通义千问开源模型?您是如何使用它的?
经过体验,通义千问开源模型总体对中文语义的理解较好,对话有逻辑。
主要用来按主题写文档提供思路和内容;查询一些通用知识等等。
2、开发者如何看待大模型开源呢?你会如何改造它?
大模型开源是一个多赢的局面,对于开源方能获取更多的反馈,防止闭门造车;还可以共同探索商业化应用的落地;对于使用方能越过技术和资源的壁垒,亲自探索和研究等等。
根据自己需要,准备专业性的语料进行训练微调用于一个具有专业知识的对话机器人。
3、通义千问开源,你有什么想要聊的呢?
感谢通义千问开源,支持开源,拥抱开源。另外,希望提供更详细的文档。
通义千问开源模型体验感受
看到这个话题就比较有兴趣,最初使用的是翻墙的ChatGPT,后来有了阿里云通义千问,立马转场,翻墙太费劲,完全没有通义千问用的舒畅。现在ModelScope魔搭社区居然上线公布了开源的Qwen-7B-Chat,于是立刻到魔塔社区感受一下训练版的通义千问,整体使用感觉发现Qwen-7B-Chat对于问题的理解似乎更透彻,Qwen-7B-Chat示例图
通义千问示例图
开发者如何看待大模型开源
对于大模型开源,个人作为开发者来说,更有利于开发者理解大模型内部的训练机理,同时开源产品也可以更方便的接入具体的业务中去,减少改造周期。另一方面,大模型开源之后可以吸引更多的开发者来加入到大模型的丰富中去,对大模型本身的发展也有很大的促进作用。
通义千问开源,你有什么想要聊的呢?
可以说,对于大模型开源,来自各行各业的开发者不断的加入到开源队伍中,对于大模型训练的程度也会不断提升,也许后续的大模型的训练程度真的可以知你心中所想,答你心中所问,也不是不可能的。一直有一句话,叫做从开源中来,到开源中去。其实说的就是开发者和开源互补的一个过程。
很高兴在这里分享我对本次话题的看法,作为一名Java后端开发者,对此次通义千问开源模型的讨论,我有以下想法:
1.虽然我还没有体验过通义千问开源模型,但是我对它很感兴趣。我打算利用它来进行一些自然语言处理任务,例如文本分类和问答等。
2.大模型开源对于开发者来说是非常有意义的,因为它可以让我们更快地进行任务开发,而不需要从头开始训练模型。我认为大模型开源可以促进更多的创新和应用,让更多的人受益。
3.我认为通义千问开源是一个很好的举措,它可以让更多的人使用到这个优秀的模型。我希望未来能够看到更多的大模型被开源,这样可以促进更多的创新和应用。同时,我也希望通义千问能够不断优化和升级,为用户提供更好的服务。
总之,开源模型对于开发者来说是一个强大的资源。无论是使用现有的开源模型还是训练自己的大模型,都需要仔细考虑项目需求、数据隐私和知识产权等因素。与其他开发者一起讨论和分享经验可以帮助你更好地理解和应用这些开源模型。
作为一个Java后端开发者,对此次通义千问开源模型的讨论,我有以下想法:
1、我已经在ModelScope上试用了通义千问开源的7亿参数通用语义模型Qwen-7B。我主要通过ModelScope提供的在线体验接口进行测试,评估了模型在通用语义理解上的效果。总体感觉模型效果不错,可以处理比较广泛的问题,理解语义较好。
2、我认为大模型开源对开发者来说是非常正面的进步。我们可以基于这些预训练模型进行二次开发,如对模型进行压缩、 Knowledge Distillation来部署到边缘设备上,或在特定领域进行fine-tune以提升鲁棒性。开源可以降低获取高质量NLP模型的门槛,让更多开发者参与到模型创新中来。
3、如果可以开源更多垂直领域的预训练语义模型,如IT领域、医疗领域等,会进一步帮助开发者快速建立高质量的行业问答机器人或语义分析应用。此外,开源一些多语言的跨语言模型也很有帮助,期待后续可以看到更多领域和语种的模型开源! (edi
要训练属于自己的“通义千问”,可以按照以下步骤进行:
收集问题:首先,收集各种与特定领域相关的问题。可以从书籍、网络、论坛、问答平台等渠道获取问题。
分类问题:对收集到的问题进行分类,可以按照主题、难度、类型等进行分类,以便更好地组织和管理问题。
答案准备:为每个问题准备相应的答案。可以通过查阅相关资料、调查研究、请教专家等方式获取答案。
答案整理:将准备好的答案整理成简洁明了的语言,确保答案易于理解和使用。
测试和修订:将问题和答案组成问答对,进行测试。可以通过模拟对话、实际应用等方式测试问答对的有效性和可用性。根据测试结果,对问答对进行修订和改进。
增量训练:随着时间的推移,不断收集新的问题并添加到问答对中,同时修订和改进已有的问答对。这样可以逐渐完善和丰富自己的“通义千问”。
持续学习:要保持对特定领域的学习和了解,以便及时更新和补充问答对。可以参加培训课程、阅读相关书籍和论文、跟踪最新研究等方式进行学习。
通过以上步骤,可以逐渐训练出属于自己的“通义千问”,并不断完善和扩展。
1、通义千问开源模型如何使用它的?
通义千问是一个开源的中文问答系统,它基于深度学习模型,使用了大规模的语料库进行训练。下面是使用通义千问开源模型的基本步骤:
安装依赖:首先需要安装Python环境和相关的依赖库,如TensorFlow等。
下载模型:从通义千问的官方GitHub仓库下载模型文件。可以选择下载预训练好的模型,也可以选择自己训练模型。
加载模型:使用Python代码加载下载的模型文件,创建一个模型对象。
输入问题:通过代码将需要回答的问题输入到模型中。
获取答案:调用模型的推理方法,获取模型对于输入问题的答案。
演示如何使用通义千问开源模型:
import tensorflow as tf
from tokenization import FullTokenizer
from modeling import BertConfig, BertModel
# 加载模型配置
config = BertConfig.from_json_file("model/bert_config.json")
# 创建模型对象
model = BertModel(config=config)
# 加载模型参数
checkpoint = tf.train.Checkpoint(model=model)
checkpoint.restore(tf.train.latest_checkpoint("model/"))
# 加载词汇表
tokenizer = FullTokenizer(vocab_file="model/vocab.txt")
# 输入问题
question = "你想吃什么?"
# 将问题转换为输入特征
input_ids = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(question))
input_ids = tf.constant([input_ids])
# 推理获取答案
outputs = model(input_ids)
answer = tokenizer.convert_ids_to_tokens(outputs[0][0].numpy().tolist())
print("答案:", answer)
2、如何看待大模型开源呢?你会如何改造它?
大模型开源的好处是可以促进模型的共享和合作,加速科学研究和技术进步。同时,大模型开源也能够提供更多的机会给开发者和研究人员,让他们能够基于已有的模型进行改进和创新。
要改造大模型,可以考虑以下几个方面:
1、Fine-tuning(微调):可以在已有的大模型基础上进行微调,以适应特定的任务或数据集。通过调整模型的参数,如学习率、优化器等,可以进一步提升模型的性能和适应性。
2、网络结构改进:对于大模型,可以通过改进网络结构来提升性能。例如,可以尝试添加更多的层或调整层的连接方式,以提高模型的表达能力和学习能力。
3、数据增强:通过增加训练数据的多样性,可以提高模型的泛化能力。可以采用数据增强的方法,如旋转、缩放、剪裁等,来生成更多的训练样本,以增加模型的鲁棒性。
4、模型融合:可以将多个大模型进行融合,以取长补短。通过集成多个模型的预测结果,可以提高模型的准确性和稳定性。
3、通义千问开源,你有什么想要聊的呢?
通义千问开源,可以让开发者分享想法、协作解决问题,可以更快速推进AIGC方面的应用落地。
1、通义千问开源模型是阿里云开源的一个70亿参数的模型,包括通用模型Qwen-7B和对话模型Qwen-7B-Chat。该模型可以在ModelScope魔搭社区上使用,它是一个开源、免费和可商用的平台。用户可以使用该模型进行自然语言处理任务,例如文本分类、情感分析、文本生成等。
2、开发者对于大模型开源可能持有不同的观点。对于一些开发者来说,大模型的开源意味着更多的机会和资源可供使用。开源模型可以提供一个基础框架,开发者可以在此基础上进行定制、改进和优化,以适应自己的应用场景和需求。不同开发者可能会采取不同的方法来改造开源模型,例如迁移学习、微调、特征提取等,以使模型更好地适应特定的任务和数据集。
3、关于通义千问开源模型,我目前没有特定的聊天话题。然而,这是一个让开发者有机会使用和定制大型模型的开放资源,如果您对该模型有任何疑问或想要深入讨论的话题,欢迎提出。我将尽力为您提供帮助和信息。
我作为一名前端开发者,我对通义千问开源模型的体验让我感到非常兴奋。这款模型的开源、免费和可商用的特性,为我们提供了一个非常方便和强大的工具,可以用于开发智能对话系统和其他相关应用。下面我将结合前端开发者的身份,分享一下我如何使用通义千问开源模型。
首先,我希望可以利用通义千问开源模型构建一个智能对话系统。作为前端开发者,我们经常需要与用户进行交互,提供实时的问题解答或者导航服务。使用通义千问开源模型,我可以通过输入用户的问题,利用模型的强大语义理解和推理能力,生成准确且具有逻辑连贯性的回答。这样,用户与系统的对话体验将会更加自然和智能,提高了用户满意度。
其次,我可以将通义千问开源模型应用于智能搜索功能的开发。在前端开发中,搜索功能是一个非常重要的组件,用户可以通过搜索来查找需要的信息。利用通义千问开源模型,我可以将用户的搜索查询转化为语义理解的问题,然后通过模型生成与查询相关的回答。这样,用户可以获得更准确和相关的搜索结果,提高了搜索的效果和用户体验。
另外,通义千问开源模型也可以用于自然语言处理领域的开发。作为前端开发者,我们经常需要处理和分析用户的文本输入,例如情感分析、关键词提取等。利用通义千问开源模型,我可以通过输入文本,利用模型的文本理解和推断能力,得到文本的语义信息。这样,我可以更好地理解和分析用户的文本输入,为后续的处理和展示提供更精准和有针对性的结果。
最后,通义千问开源模型也为我们提供了一个学习和研究的平台。作为前端开发者,我们对人工智能和自然语言处理等领域的发展非常感兴趣。通过使用通义千问开源模型,我们可以了解到最新的模型架构和技术,探索其中的原理和应用。同时,我们也可以参与到模型的改进和优化中,提供反馈和建议,共同推动模型的发展和进步。
作为一名前端开发者,我可以通过通义千问开源模型构建智能对话系统、应用于智能搜索功能、进行自然语言处理等方面的开发。同时,我也可以利用该模型作为学习和研究的平台,探索人工智能和自然语言处理领域的前沿技术。通过充分利用通义千问开源模型的功能和特性,我相信我可以为用户提供更智能、更高效和更便捷的前端应用体验。
作为前端开发者,我认为大模型开源对开发者来说是一个非常有价值的资源。开源大模型的意义在于为开发者提供了一个开放、透明和可定制的平台,使我们能够更好地理解和利用这些模型的能力,同时也可以进行二次开发和改造,以满足不同场景和需求的应用。
大模型开源使得开发者能够更好地理解模型的工作原理和技术细节。通过研究开源模型的代码和文档,我们可以深入了解模型的架构、训练方法和推理过程等关键要素。这对于我们理解和应用模型的能力有着重要的意义,可以帮助我们更好地优化和调整模型的参数和配置,以适应具体的业务需求。
大模型开源为开发者提供了一个定制化的平台,可以进行个性化的改造和适配。作为前端开发者,我们可以结合自己的项目需求和技术特点,对开源模型进行改造和扩展,以满足特定的前端应用场景。例如,可以将模型与前端框架或者其他工具进行集成,以实现更好的交互和用户体验。同时,我们还可以根据具体应用的需求,对模型进行性能优化和资源管理,以提高系统的效率和稳定性。
大模型开源也为开发者提供了一个学习和探索的平台。通过参与大模型的开源社区,我们可以与其他开发者进行交流和分享,互相学习和借鉴经验。同时,我们也可以通过参与开源模型的改进和优化,提供反馈和建议,为模型的进一步发展做出贡献。这对于我们个人的技术成长和职业发展都具有积极的影响。
在改造大模型时,作为前端开发者,我们可以从以下几个方面进行思考和实践。
总结来说,大模型开源对于前端开发者来说是一个宝贵的资源和机会。通过研究和改造大模型,我们可以更好地理解和应用模型的能力,同时也可以根据自己的项目需求进行个性化的改造和适配。通过参与开源社区和贡献代码,我们还可以与其他开发者进行交流和学习,共同推动模型的发展和进步。通过充分利用大模型开源的机会,我相信我们可以为用户提供更丰富、更智能和更优质的前端应用体验。
作为前端开发者,我对开源有以下几个方面的兴趣和关注:
1. 如何选择适合前端开发的开源项目?
作为前端开发者,我们需要考虑项目的需求和技术栈,以选择适合的开源项目。那么,我想问如何评估一个开源项目是否适合前端开发?有哪些指标或者标准可以参考?
2. 开源项目如何保持活跃和稳定?
在选择开源项目时,一个重要的考虑因素是项目的活跃度和稳定性。作为前端开发者,我们希望使用的开源项目能够持续得到维护和更新。那么,我想了解一下如何评估一个开源项目的活跃度?还有什么方法可以帮助我们判断一个项目是否稳定可靠?
3. 如何参与开源项目的贡献?
作为前端开发者,我们也可以积极参与到开源项目的贡献中,为项目的发展做出自己的贡献。那么,我想问如何开始参与开源项目的贡献?有哪些途径可以获取相关项目的信息和文档?如何与项目的维护者和其他贡献者进行有效的沟通和合作?
4. 如何利用开源项目提升前端开发的技术能力?
开源项目不仅是我们使用的工具,也是我们学习和提升技术能力的重要资源。那么,我想了解一下如何利用开源项目来提升前端开发的技术能力?有哪些学习和实践的方法可以推荐?
5. 如何避免开源项目的安全风险?
尽管开源项目有很多好处,但也可能存在安全风险。作为前端开发者,我们需要注意避免使用潜在的有安全隐患的开源项目。那么,我想问一下如何评估一个开源项目的安全性?有哪些措施可以帮助我们减少潜在的安全风险?
1、您是否已经体验了通义千问开源模型?您是如何使用它的?
体验过了,点击链接:https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary?spm=a2c6h.12873639.article-detail.4.417c26273o8yNM/,即可立马体验
有一说一,讲笑话的能力,有点差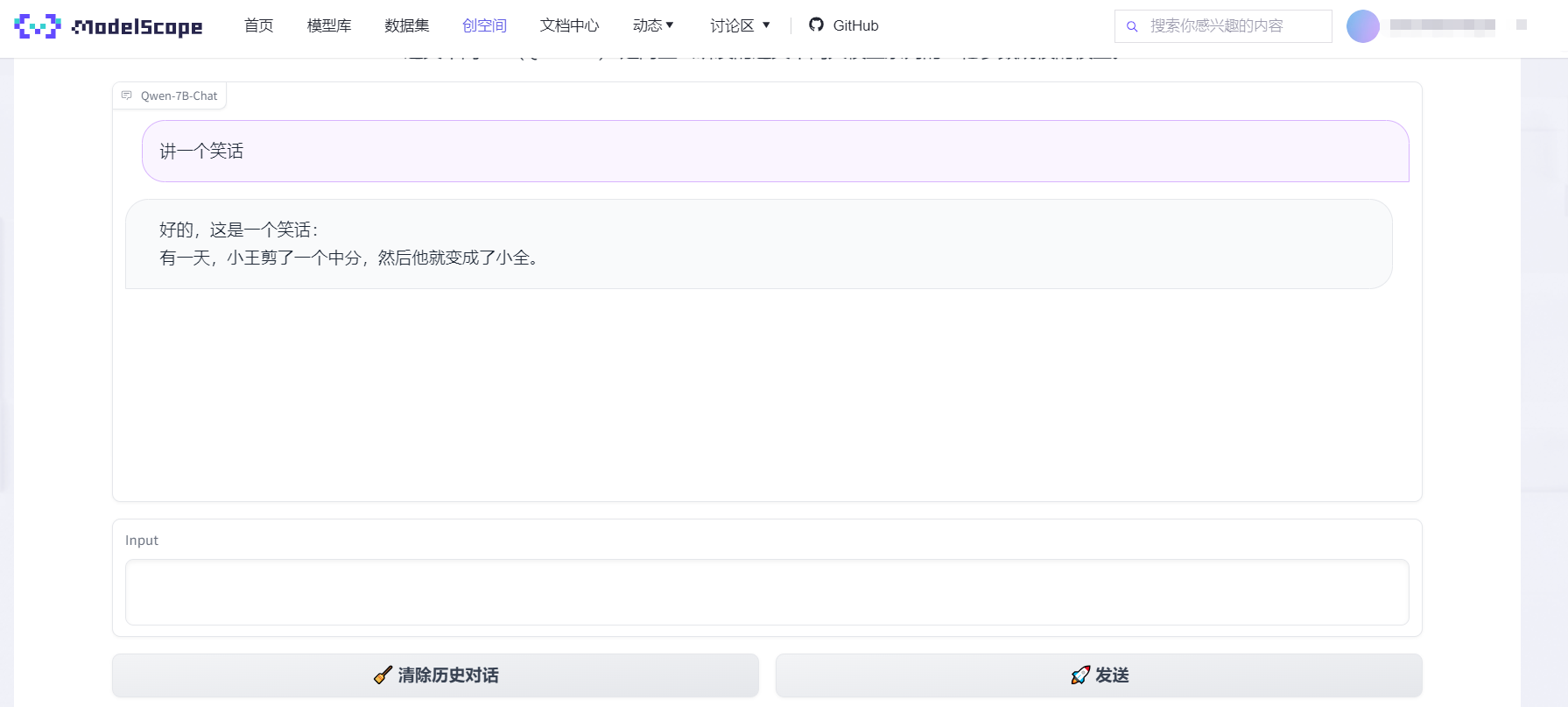
2、开发者如何看待大模型开源呢?你会如何改造它?
大模型开源为我们开发者提供了学习和实践机会,拓宽技术能力,加深知识深度。通过研究开源的大模型,我们可以深入了解其内部原理和算法。同时,我们还可以参与开源社区,与其他开发者交流经验,分享最佳实践。这种开源文化激发创新思维,提升解决问题的能力,推动技术进步。总之,大模型开源扩展了我们的技术视野,帮助我们不断提高技术水平,适应快速变化的技术环境。
我会使用自己感兴趣的数据喂养大模型开源,经过训练和微调,将其转化为一款专属AI。通过选择合适的数据集,对大模型进行训练和优化,使其具备对特定领域或任务的专业知识和能力。这样的专属AI将能够提供个性化的服务和解决方案,并具备更高的可定制性和适应性。
3、通义千问开源,你有什么想要聊的呢?
通义千问开源,我认为这将是一个非常令人振奋的事情。通义千问将使更多的开发者和研究者能够深入了解其工作原理和算法,并有机会对其进行改进、优化和定制。开源将激发创新思维和合作精神,促进AI技术的共同发展。此外,开源还将带来更多的透明度和审查机制,提高AI系统的可信度和可靠性。我期待看到更多开源项目的推出,以促进全球AI技术的快速进步和应用。
我个人对大模型的一些个人见解或看法:
开发者看待大模型开源:大模型开源对开发者来说是一个积极的趋势。通过开源,开发者可以获得先进的模型结构和预训练参数,从而加快他们在各种任务上的研发和应用进程。大模型的开源也有助于促进开发者之间的知识共享和合作。
改造大模型:开发者可以根据自己的需求和场景对开源的大模型进行改造和定制化。这可能包括微调模型参数、增加领域特定的数据进行进一步训练,或是将模型集成到自己的应用中以满足特定需求。改造大模型可以使其更适应个人或组织的实际应用场景。
自从年初的chat推广以来,个厂商的大数据模型已经刷遍全网,第一波靠着大数据模型概念圈资金的潮流已经过去,接下来的时刻是时候沉淀下来,好好的想想大模型能够带来的生产价值跟利益点了。数据模型在客服,医疗特别是精神心理方面都有着自身的优势,甚至之前的奶奶漏洞也帮我们揭示了在部分领域也有自己的实现价值。目前的时代,不是获取信息的时代了,因为信息太多,我们反而要做的,是筛选信息,之前人形水母的进化,就给我们人类提了个醒,再不注重信息的筛选,后期我们的下一代,将以机器人的形式活下去,地球上可能最后一个非电力种族是电力种族蓄养的生物了
开发者如何看待大模型开源呢?我认为大模型开源对于开发者来说是非常有价值的。它可以让开发者获得到高质量的模型,从而更快地开发出高效率的应用程序。同时,大模型开源也可以促进模型的共享和创新,从而推动整个行业的发展。开发者可以通过大模型开源来学习和借鉴大模型的设计和实现思路,从而提高自己的开发水平和创新能力。
通义千问开源,我认为这是一个非常有意义的举措。它可以让更多的开发者获得到这个高质量的模型,并基于此开发出更多有价值的应用程序。同时,通义千问开源也可以促进AI技术的普及和应用,从而为人类带来更多的便利和福利。我认为,通义千问开源可以让更多的开发者了解和学习AI技术,从而推动AI技术的发展和应用。同时,通义千问开源也可以让更多的开发者参与到AI技术的创新和改进中来,从而促进AI技术的进步和发展。
大模型的开源对于开发者来说是一个非常有价值的资源。它们为开发者提供了在各种自然语言处理任务上取得卓越性能的机会,同时也可以帮助开发者节省大量的研发时间和资源。开源大模型还可以促进创新和合作,让更多的开发者参与到模型的改进和优化中来。
如果我要改造大模型,我可能会考虑以下几个方面:
改进预训练数据:通过增加更多的多样化、高质量的数据来提升模型的表现。
针对特定任务微调:根据特定任务的需求,对模型进行微调,使其更好地适应特定领域或场景。
改进模型架构:尝试不同的模型架构、层数或其他参数的组合,以达到更好的性能。
优化推理速度:对模型进行优化,以提高推理速度,适用于实时应用场景。
大模型的开源对开发者来说是一个宝贵的资源,它们可以作为构建更复杂、更智能应用的基础。开源大模型提供了一个学习和探索最新自然语言处理技术的机会,也为开发者提供了定制化、优化以及创新的空间。改造大模型可以根据特定需求进行,比如微调以适应特定领域,添加定制功能,优化性能等。但需要注意的是,改造大模型可能需要一定的领域知识和技术专长。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352


