
问题1:云原生数据仓库AnalyticDB PostgreSQL看曲线像是是没有使用到其他节点, 有没有被优化器指定为串行计算了呢?我能不能指定并行计算测试下效率。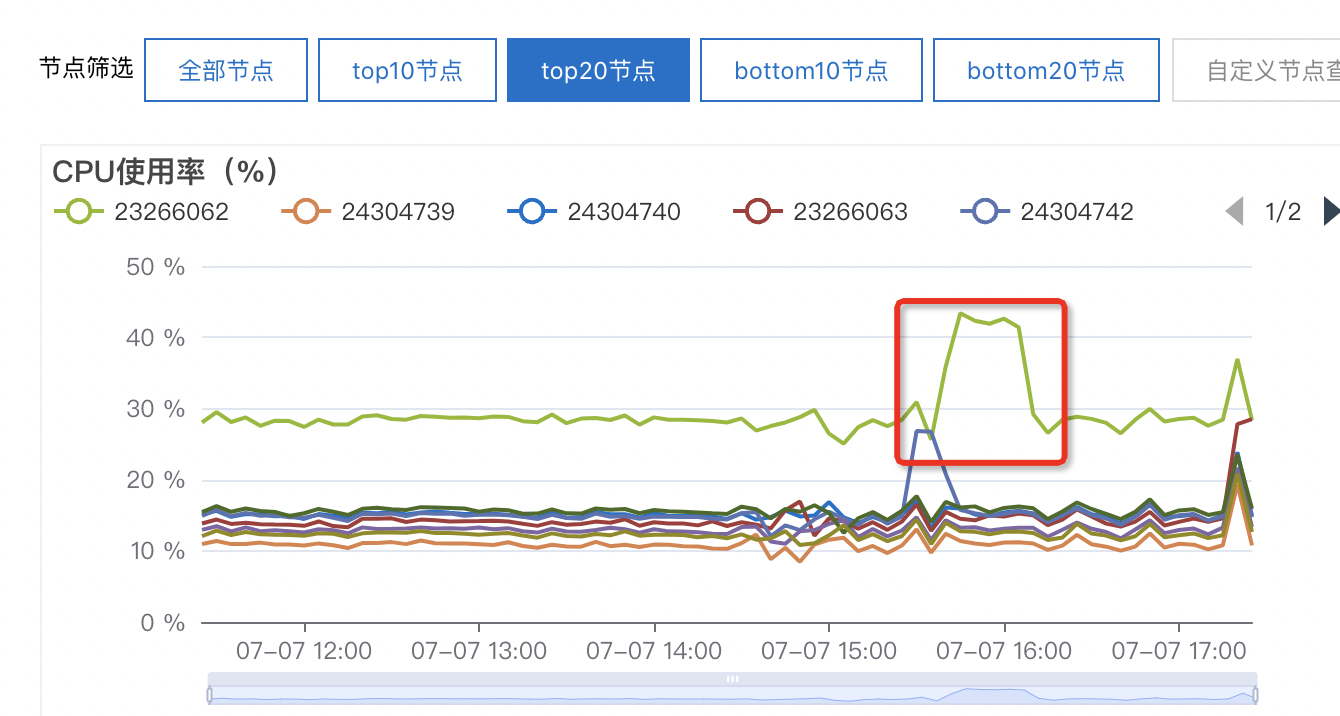
问题2:如果是这个情况,那我单独跑23266062这个节点的计算可以复现。
但是我现在创建8个物化视图,添加条件 where gp_segment_id = 0~7 ,并没有出现这个情况,这是为什么?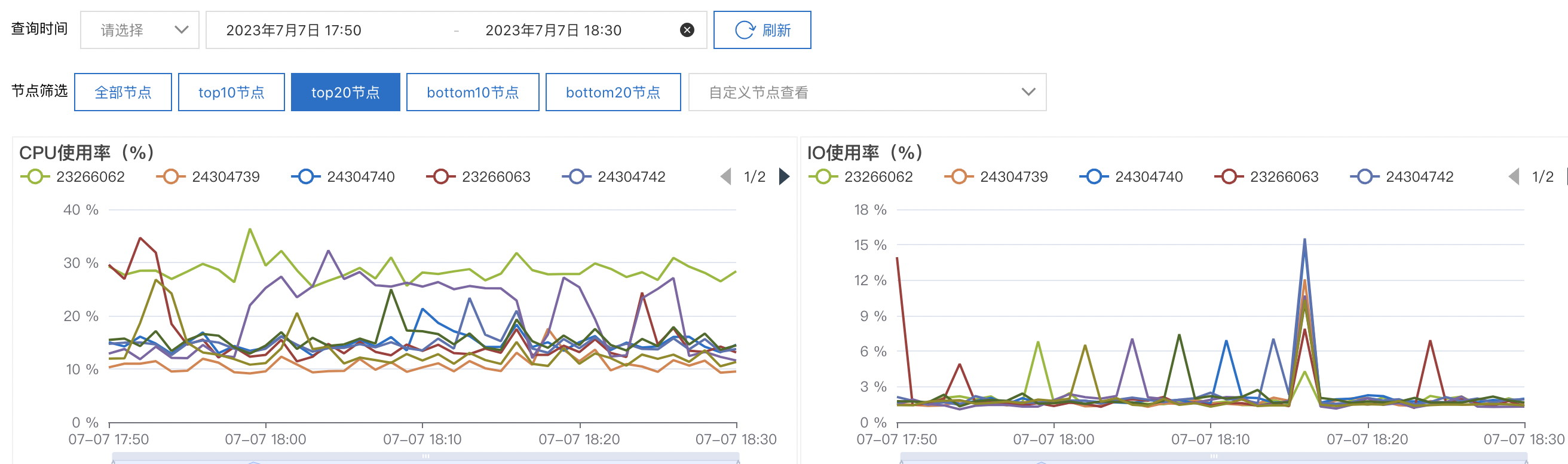
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
AnalyticDB PostgreSQL 是阿里云提供的云原生数据仓库服务,它在底层使用了分布式存储和计算引擎来处理大规模数据分析工作负载。由于其分布式架构,查询优化器会根据具体的查询计划和数据分布情况,尽可能地并行执行查询操作。
在 AnalyticDB PostgreSQL 中,默认情况下,查询优化器会尽量以并行方式执行查询计划,并利用集群中的多个节点来加速查询。然而,具体是否将某个特定查询指定为串行计算,取决于查询涉及的表、索引、查询条件、连接操作等因素,优化器会根据这些信息进行决策。
如果您想确切知道某个查询是否被优化器指定为串行计算,可以通过执行 EXPLAIN 或 EXPLAIN ANALYZE 命令来查看查询计划和执行统计信息。这将显示出被选择的计划节点以及相关的详细信息,从中可以推断出是否采用了并行计算或者是否存在串行计算。
在云原生数据仓库AnalyticDB PostgreSQL中,优化器会根据查询的复杂度、表的大小、分布情况、硬件配置等因素来选择并行或串行计算方式。如果优化器认为并行计算的效果不如串行计算,就会选择串行计算,而不是强制使用并行计算。
在您的情况下,如果看曲线并没有使用到其他节点,可能是由于以下原因导致的:
查询的复杂度较低:如果查询的复杂度较低,例如没有使用复杂的聚合函数、子查询等,那么并行计算的效果可能不如串行计算。
数据分布不均衡:如果查询的表数据分布不均衡,例如其中一张表的数据有很多重复,那么在并行计算时可能会出现数据倾斜的情况,从而导致一些节点的负载较重,影响整个查询的效率。
硬件配置不足:如果集群的硬件配置不足,例如节点数太少或者节点的CPU、内存等配置较低,那么并行计算的效果可能不如串行计算。
在AnalyticDB PostgreSQL中,您可以通过设置max_parallel_workers参数来控制并行计算的最大线程数。例如,您可以使用以下语法来设置并行计算的最大线程数为4:
Copy
SET max_parallel_workers = 4;
需要注意的是,设置并行计算的最大线程数需要根据实际情况进行调整
针对问题1的回答:我们是mpp分布式数据库肯定是会用到所有计算节点的,只是说每个节点由于group+cube后每个节点处理的数据量不一致,导致的计算倾斜才会出现每个节点的cpu不一样。才会出现你的这个情况。此回答整理自钉群“云原生数据仓库AnalyticDB PostgreSQL版交流群”
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。


