
在云原生数据仓库AnalyticDB PostgreSQL自定义函数资源代码包,如果用python写,代码结构是哪种呢?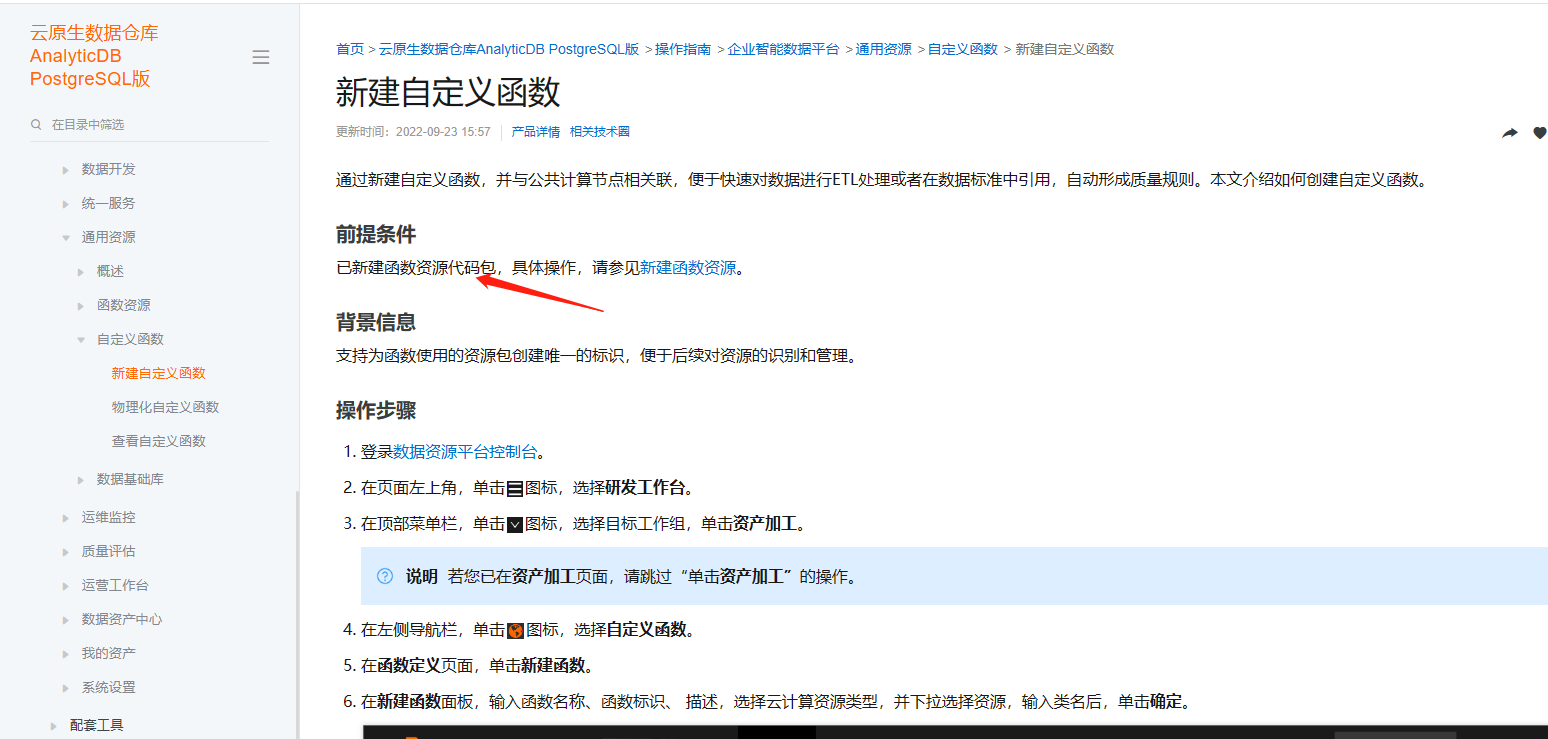
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在云原生数据仓库 AnalyticDB PostgreSQL 中使用 Python 编写代码时,可以采用不同的代码结构,具体取决于您的需求和项目的规模。以下是一种常见的代码结构示例:
导入必要的模块和库:
import psycopg2
建立数据库连接:
conn = psycopg2.connect(
host="your_host",
port="your_port",
database="your_database",
user="your_username",
password="your_password"
)
创建游标对象:
cursor = conn.cursor()
执行 SQL 语句或调用存储过程:
sql_query = "SELECT * FROM your_table"
cursor.execute(sql_query)
处理结果集(如果需要):
result = cursor.fetchall()
for row in result:
# 处理每行数据
提交事务(如果适用):
conn.commit()
关闭游标和数据库连接:
cursor.close()
conn.close()
这只是一个简单的代码结构示例,您可以根据实际需求进行进一步扩展和优化。例如,您可以编写函数或类来封装重复使用的代码块,或者使用 ORM(对象关系映射)工具来管理数据库交互。
此外,还可以考虑使用异常处理机制来捕获和处理可能出现的错误。此外,根据项目需求,您还可以引入其他库和框架,例如 SQLAlchemy 或 Django,以简化数据库操作和提高代码的可维护性。
代码结构可以按照以下方式进行组织:
在资源代码包中创建一个名为 "sql" 的文件夹,用于存放 SQL 脚本文件。
在 "sql" 文件夹中创建一个名为 "function.sql" 的文件,用于存放自定义函数的 SQL 脚本。
在 "sql" 文件夹中创建一个名为 "setup.sql" 的文件,用于存放自定义函数的安装脚本。
在资源代码包根目录下创建一个名为 "python" 的文件夹,用于存放 Python 脚本文件。
将 Python 脚本文件和所需的依赖库文件放入 "python" 文件夹中。
在自定义函数的 SQL 脚本中,使用 "plpython3u" 语句来声明自定义函数的执行语言。
在自定义函数的 SQL 脚本中,使用 "plpython3u" 语句来调用 Python 脚本文件,并传递参数。
例如,下面是一个用 Python 编写的自定义函数的代码结构示例:
basic
Copy
my_function/
├── sql/
│ ├── function.sql
│ └── setup.sql
└── python/
├── my_script.py
└── requirements.txt
其中,function.sql 文件中包含自定义函数的 SQL 脚本,setup.sql 文件中包含自定义函数的安装脚本,my_script.py 文件中包含 Python 脚本,requirements.txt 文件中包含 Python 脚本所需的依赖库。
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。


