
Flink CDC这个问题有没有大神指导下?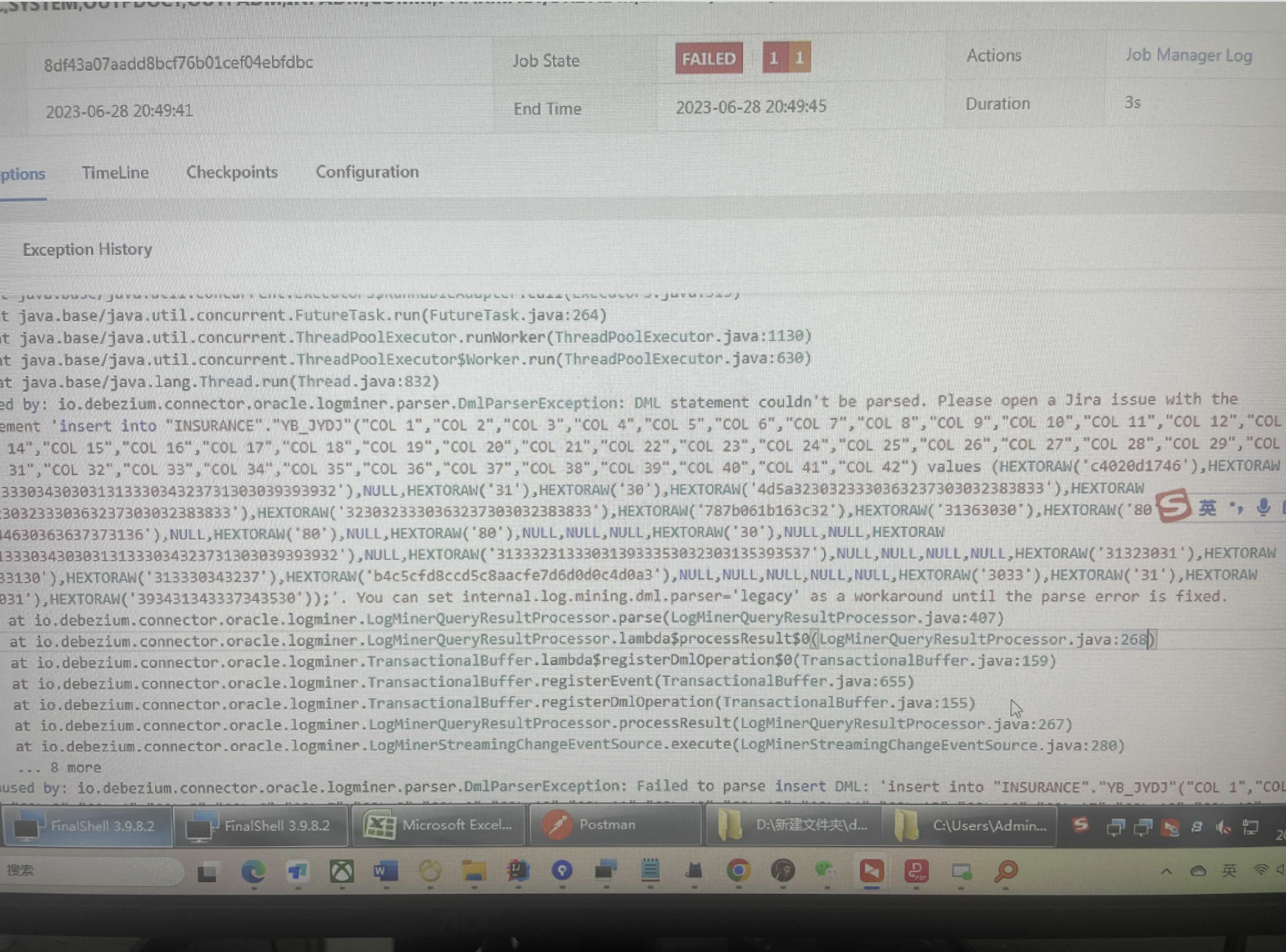
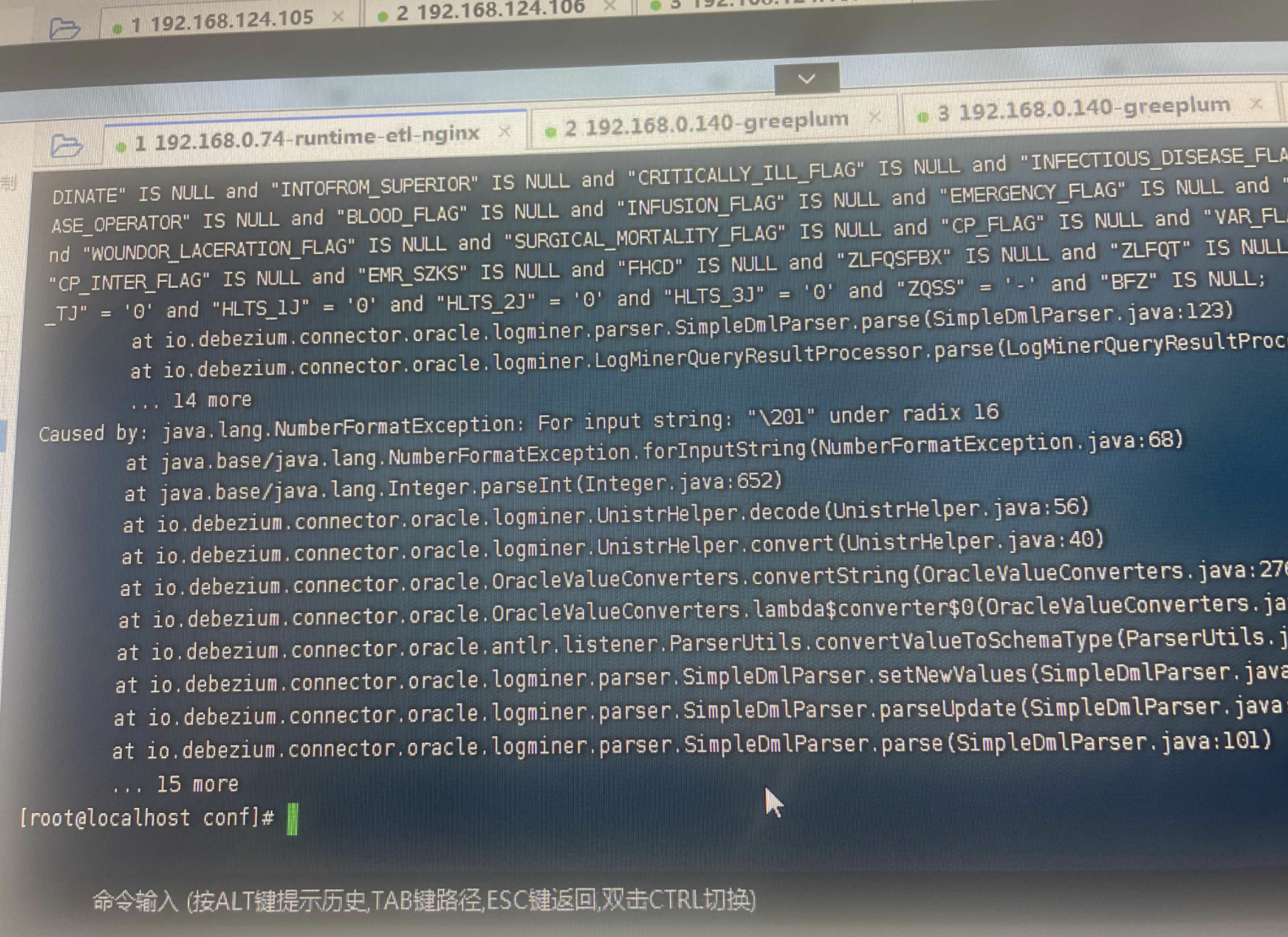 加了参数是这样,我是先增量 然后完了savepoint 保存了5个保存点 然后过了一两天就使用保存点启动 没一会就报错了,我一共3个任务 其他两个启动了运行很好,第一次全量抽完全没问题 过两天就出错了 而且前后代码配置一样的
加了参数是这样,我是先增量 然后完了savepoint 保存了5个保存点 然后过了一两天就使用保存点启动 没一会就报错了,我一共3个任务 其他两个启动了运行很好,第一次全量抽完全没问题 过两天就出错了 而且前后代码配置一样的
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
对于Flink CDC报错的问题,可以尝试以下几个解决方案:
1. 检查使用的参数是否正确。确保在启动任务时传递的参数是正确的,并且与代码配置一致。
2. 确认保存点(savepoint)的使用方式和频率。保存点是用来恢复任务状态的,确保在合适的时机使用保存点进行任务的恢复。可以检查保存点生成的过程是否出现了异常或错误。
3. 检查任务的状态是否正确保存。确认保存点文件是否存在、完整,并且能够被正确加载。可以尝试重新生成保存点并验证其有效性。
4. 检查日志文件以获取更多错误信息和异常堆栈。详细的错误信息能够帮助定位报错的原因。将日志文件中的相关错误信息提供给社区或相关讨论群组,以获得更准确的支持。
5. 如果使用的参数或配置中包含特殊字符,请确保在设置参数时进行正确的转义或处理。特殊字符可能导致参数解析错误或引发其他问题。
此外,在使用 Flink CDC 进行增量抽取时,需要确认设置的 scan.startup.mode 参数是否为 "initial",以确保首次全量抽取完成后继续进行增量抽取。请注意,具体的参数设置可能会因版本和环境而有所不同,请参考相关文档或社区讨论以获取更准确的参数配置。
如果问题仍然存在,建议您提供更多详细的错误信息、日志文件以及相关代码和配置,这样可以帮助社区或相关讨论群组更好地理解问题并给出具体的解决方案。
在使用 Flink CDC 时,可以使用 FlinkCDCSource 读取 MySQL 数据库的数据,并将数据写入到 Flink DataStream 中进行处理。在处理完数据后,可以使用 Flink 的 savepoint 机制,将任务的状态保存到指定的文件系统中,以便在后续需要恢复任务时使用。
具体来说,可以通过使用 FlinkCDCSource 对象创建 DataStream,并在 DataStream 上进行数据处理,例如:
java
Copy
FlinkMySQLSource.Builder sourceBuilder = FlinkMySQLSource.builder()
.hostname("localhost")
.port(3306)
.database("test")
.table("my_table")
.username("root")
.password("root")
.startupOptions(StartupOptions.earliest());
FlinkCDCSource source = sourceBuilder.build();
DataStream stream = env.addSource(source)
.map(new MyMapFunction())
.filter(new MyFilterFunction());
在上述示例中,使用 FlinkMySQLSource 对象创建 FlinkCDCSource,并使用 startupOptions() 方法设置起始位置和读取数据的方式。然后,使用 env.addSource() 方法创建 DataStream,并在 DataStream 上进行数据处理,例如通过 map() 和 filter() 方法等进行转换和过滤。
在处理完数据后,可以使用 Flink 的 savepoint 机制,将任务的状态保存到指定的文件系统中,例如:
Copy
./bin/flink savepoint
在上述命令中, 是要保存状态的 Flink 任务的 ID, 是指定的保存状态的文件系统路径。
需要注意的是,在使用 savepoint 机制时,需要确保 Flink 任务和文件系统之间的网络连接畅通,并且需要使用相应的存储插件进行状态的保存和恢复。
有特殊字符?datastream里scan.startup.mode是initail,这个设置是全量跑完了会继续增量吧(没有只跑全量的设置吧),你看到没日志了,但是你怎么确定是全量跑完了没日志,还是全量跑完了又跑了会增量后没日志的呢,此回答整理自钉群“Flink CDC 社区”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


