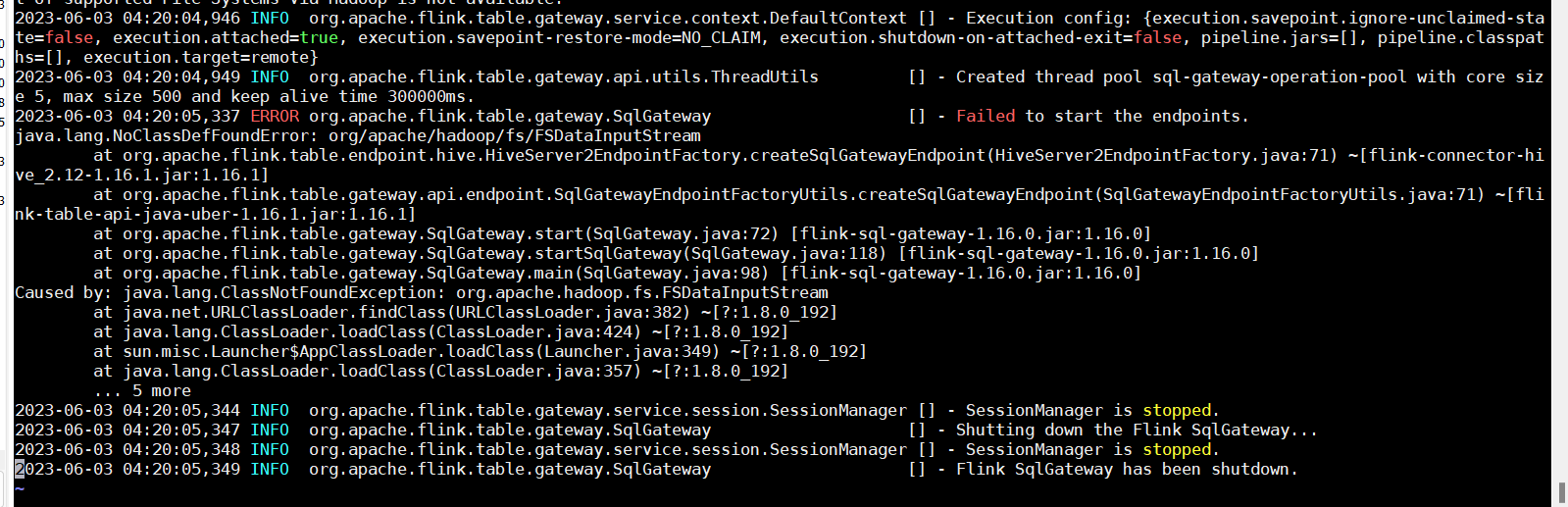
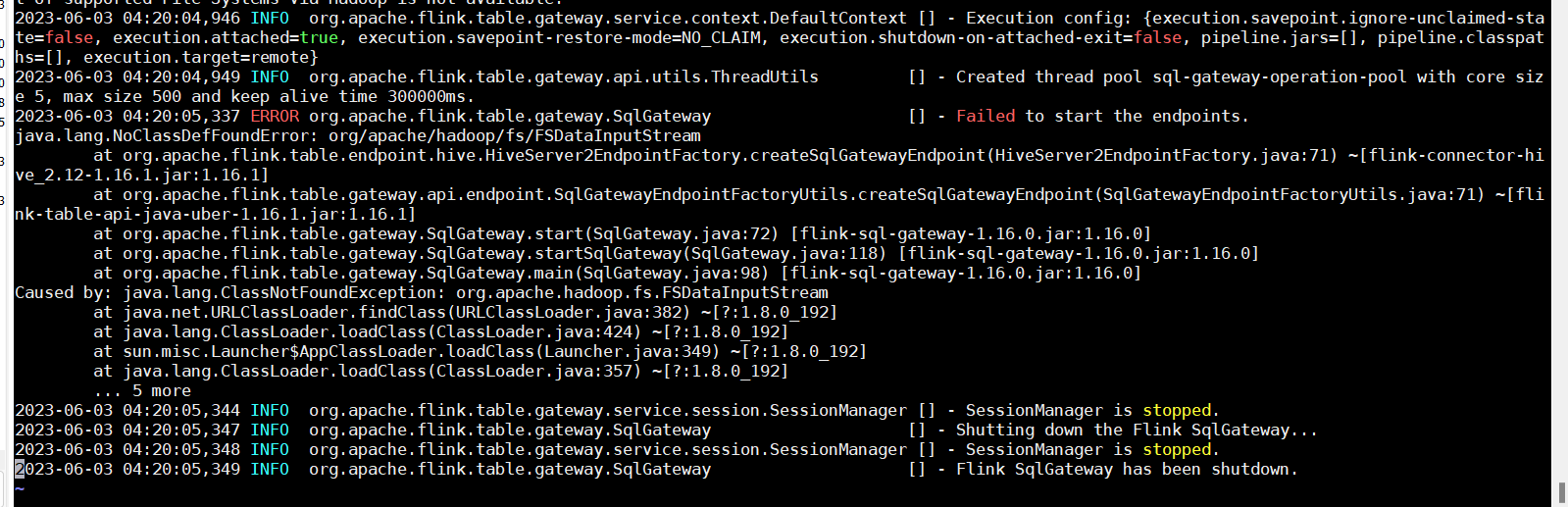
flink 启动 sql gateway链接hiveserver2报错有人遇见过吗?Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FSDataInputStream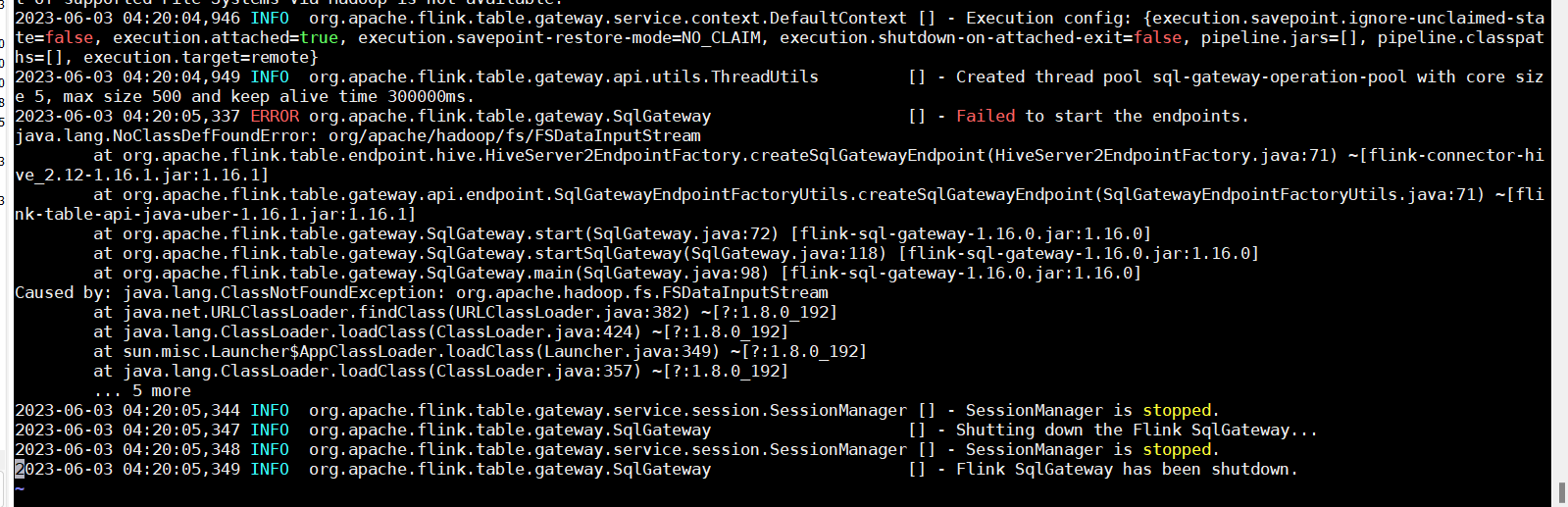
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的信息,看起来您的问题是关于Apache Flink SQL Gateway启动时遇到异常,特别是由于ClassNotFoundException引发的问题。这个问题涉及到org.apache.hadoop.fs.FSDataInputStream 类的缺失。FSDataInputStream 是Hadoop HDFS中的一个类,用于表示HDFS中的数据流。
首先,我们需要确定的是,您是否已经在类路径中包含了Hadoop的相关jar包。如果您还没有这么做,则必须手动下载Hadoop jar包并将它们加入到了Flink项目的类路径中。您可以尝试以下操作:
下载Hadoop 的相应版本(推荐使用与您的Flink版本匹配的那个)。
解压Hadoop压缩包。
将解压出来的lib目录下的所有jar包复制到Flink项目根目录下的lib目录下。
如果有多个Hadoop版本,请删除之前不适用的版本的jar包。
完成上述步骤之后,再次尝试启动Flink SQL Gateway。此外,还需要注意的一点是确保所有的Hadoop jar包都已经正确地放置到位,并且在Flink ClassLoader中可寻址。
如果问题依然存在,那么还可能出现其他的因素导致这个问题发生,例如:
版本不兼容:确保您使用的Hadoop版本与您的Flink版本兼容。
Maven依赖问题:检查Maven pom.xml文件中的依赖项,确保它们都被正确地解析和打包进最终的JAR文件中。
运行环境问题:确保您的操作系统满足Hadoop的要求,例如内核版本和JVM版本等等。
看起来您正在尝试使用HiveServer2端点将Flink SQL网关连接到Apache蜂巢,但在这样做时遇到了ClassNotFoundException。错误特别提到了在执行期间hadoop-fs包 (v16) 中缺少类。根据我的经验,以下是一些可能的解决方案:请确保您已为最新稳定版本的Flink-Hive连接器添加了正确的依赖项。根据日志记录,您似乎正在使用v2.16.x。将以下maven依赖项添加到您的聚甲醛.xml文件中:
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_{{scala_version}}{% endfor %}</artifact_id>
<version>{{flink_hive_connector}}</version>
'将scala_version替换为您在Flink安装中使用的Scala版本,并且flink_hive_connector应与正在使用的Flink版本匹配。 验证您是否设置了通过hiveserver2访问蜂巢所需的环境变量。特别是,确保定义了 $ HADOOP_HOME并指向您的Hadoop发行版的根目录。 如果在设置上述内容后仍面临问题,请尝试降级到Flink的早期版本或升级到较新的版本,具体取决于兼容性限制。
在使用Flink SQL Gateway连接HiveServer2时也遇到了类似的错误。根据我的经验,这个问题可能是由于Flink SQL Gateway的Hadoop依赖问题导致的。你可以尝试以下方法来解决这个问题:
org.apache.hadoop
hadoop-client
2.7.3
CopyCopy
implementation 'org.apache.hadoop:hadoop-client:2.7.3'
CopyCopy
-Dorg.apache.hadoop.fs.FSDataInputStream.class.path=/path/to/your/hadoop-client-jars
CopyCopy
将/path/to/your/hadoop-client-jars替换为你的Hadoop客户端库的路径。
如何解决Flink依赖冲突问题?https://help.aliyun.com/zh/flink/support/reference?spm=a2c4g.11186623.0.i74

问题现象
有明显报错,且引发错误的为Flink或Hadoop相关类。
java.lang.AbstractMethodError
java.lang.ClassNotFoundException
java.lang.IllegalAccessError
java.lang.IllegalAccessException
java.lang.InstantiationError
java.lang.InstantiationException
java.lang.InvocationTargetException
java.lang.NoClassDefFoundError
java.lang.NoSuchFieldError
java.lang.NoSuchFieldException
java.lang.NoSuchMethodError
java.lang.NoSuchMethodException
无明显报错,但会引起一些不符合预期的现象,例如:
日志不输出或log4j配置不生效。
该类问题通常是由于依赖中携带了log4j相关配置导致的。需要排查作业JAR包中是否引入了log4j配置的依赖,可以通过在dependency中配置exclusions的方式去掉log4j配置。
说明
如果必须要使用不同版本的log4j,需要使用maven-shade-plugin将log4j相关的class relocation掉。
RPC调用异常。
Flink的Akka RPC调用出现依赖冲突可能导致的异常,默认不会显示在日志中,需要开启Debug日志进行确认。
例如,Debug日志中出现Cannot allocate the requested resources. Trying to allocate ResourceProfile{xxx},但是JM日志在Registering TaskManager with ResourceID xxx后,没有下文,直到资源请求超时报错NoResourceAvailableException。此外TM持续报错Cannot allocate the requested resources. Trying to allocate ResourceProfile{xxx}。
原因:开启Debug日志后,发现RPC调用报错InvocationTargetException,该报错导致TM Slot分配到一半失败出现状态不一致,RM持续尝试分配Slot失败无法恢复。
问题原因
作业JAR包中包含了不必要的依赖(例如基本配置、Flink、Hadoop和log4j依赖),造成依赖冲突从而引发各种问题。
作业需要的Connector对应的依赖未被打入JAR包中。
排查方法
查看作业pom.xml文件,判断是否存在不必要的依赖。
通过jar tf foo.jar命令查看作业JAR包内容,判断是否存在引发依赖冲突的内容。
通过mvn dependency:tree命令查看作业的依赖关系,判断是否存在冲突的依赖。
解决方案
基本配置建议将scope全部设置为provided,即不打入作业JAR包。
DataStream Java
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。