
DataWorks中Hadoop数据迁移MaxCompute最佳实践执行结果?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
单击左侧导航栏中的临时查询。选择新建 > ODPS SQL。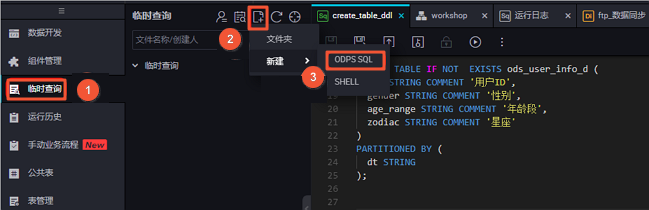 编写并执行SQL语句,查看导入hive_doc_good_sale的数据。SQL语句如下所示: --查看是否成功写入MaxCompute。 select * from hive_doc_good_sale where pt=1; 您也可以在odpscmd命令行工具中输入select * FROM hive_doc_good_sale where pt =1;,查询表结果。如果您想实现MaxCompute数据迁移至Hadoop,步骤与上述步骤类似,不同的是同步脚本内的reader和writer对象需要对调,具体实现脚本如下。{"configuration": {"reader": {"plugin": "odps","parameter": {"partition": "pt=1","isCompress": false,"datasource": "odps_first","column": ["create_time","category","brand","buyer_id","trans_num","trans_amount","click_cnt"],"table": "hive_doc_good_sale"}},"writer": {"plugin": "hdfs","parameter": {"path": "/user/hive/warehouse/hive_doc_good_sale","fileName": "pt=1","datasource": "HDFS_data_source","column": [{"name": "create_time","type": "string"},{"name": "category","type": "string"},{"name": "brand","type": "string"},{"name": "buyer_id","type": "string"},{"name": "trans_num","type": "BIGINT"},{"name": "trans_amount" https://help.aliyun.com/document_detail/98132.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
编写并执行SQL语句,查看导入hive_doc_good_sale的数据。SQL语句如下所示: --查看是否成功写入MaxCompute。 select * from hive_doc_good_sale where pt=1; 您也可以在odpscmd命令行工具中输入select * FROM hive_doc_good_sale where pt =1;,查询表结果。如果您想实现MaxCompute数据迁移至Hadoop,步骤与上述步骤类似,不同的是同步脚本内的reader和writer对象需要对调,具体实现脚本如下。{"configuration": {"reader": {"plugin": "odps","parameter": {"partition": "pt=1","isCompress": false,"datasource": "odps_first","column": ["create_time","category","brand","buyer_id","trans_num","trans_amount","click_cnt"],"table": "hive_doc_good_sale"}},"writer": {"plugin": "hdfs","parameter": {"path": "/user/hive/warehouse/hive_doc_good_sale","fileName": "pt=1","datasource": "HDFS_data_source","column": [{"name": "create_time","type": "string"},{"name": "category","type": "string"},{"name": "brand","type": "string"},{"name": "buyer_id","type": "string"},{"name": "trans_num","type": "BIGINT"},{"name": "trans_amount" https://help.aliyun.com/document_detail/98132.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

