
 4000积分,社区定制抱枕*5
4000积分,社区定制抱枕*5
SQL不仅是一个工具,更是一种思维方式,它可以帮助我们发掘数据中的潜在价值,为业务决策提供有效的支持。在软件开发过程中,数据库也是很重要的一环,你在学习SQL时觉得哪些部分很有意思?你印象最深的一道SQL题目又是什么?
在这里,邀请大家一起参与「阿里云瑶池数据库SQL挑战赛」,本赛事准备了三道由浅入深的赛题,一起回忆学习SQL的日子,快来试试你有多会写SQL吧!
本期话题:
1、你觉得最经典的SQL题目是什么?
2、本次赛事中哪道题目最有意思?针对该题目有什么高效解法?
欢迎大家分享你和SQL的故事, 点击此处 立即试用云数据库哦,最长免费3个月!
本期奖品:
截止2023年5月31日24时,参与本期话题互动讨论,将选取5位幸运用户发放社区定制抱枕 * 1。
获奖规则:中奖楼层百分比为3%,13%,33%,63%,83%的有效留言用户可获得互动幸运奖。 如:活动结束后,回复为100层,则获奖楼层为100 * 3%=3,依此类推,即第3、13、33、63、83位回答用户获奖。如遇非整数,则向后取整。如:回复楼层为80层,则80 * 3%=2.4,则第3楼获奖。

注:楼层需为有效回答(符合互动主题),灌水/复制回答将自动顺延至下一层。话题讨论要求原创,如有参考,一律注明出处,否则视为抄袭不予发奖。获奖名单将于3个工作日内公布,礼品7个工作日内发放,节假日顺延。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这是我们学校信息中心那边给测试题目
1、MySQLSleep线程过多,以下操作不正确的是()
A.设置interactive_timeout参数,减小wait_timeout等待超时时间
B.php程序不要使用长连接,java程序调整连接池
C.打开mysql慢查询
D.检查应用连接情况,增加连接数
2、只建一个索引,如何建最优()
A.idx_ab(a,b)
B.idx_ba(b,a)
C.idx_abtime(a,b,time)
D.idx_btime(b,time)
经典的SQL题目包括 1.SQL中有一些有趣的函数,比如说字符串函数、日期函数、数学函数等等。例如,可以使用SUBSTRING函数截取字符串的一部分,使用DATEADD函数在日期上加上一定的时间,使用ABS函数获取一个数的绝对值等等。 找出每个部门的员工数量和平均工资,并只显示平均工资高于公司平均工资的部门。如果有多个部门平均工资相同,则按部门名称从A到Z排序。同时,只显示前5个部门。如果有多个部门平均工资相同且都在前5个部门中,则显示所有这些部门。 SELECT department, COUNT() AS num_employees, AVG(salary) AS avg_salary FROM employees GROUP BY department HAVING AVG(salary) > (SELECT AVG(salary) FROM employees) ORDER BY avg_salary DESC, department ASC LIMIT 5 UNION SELECT department, COUNT() AS num_employees, AVG(salary) AS avg_salary FROM employees GROUP BY department HAVING AVG(salary) = (SELECT AVG(salary) FROM employees) AND department IN (SELECT department FROM employees GROUP BY department HAVING AVG(salary) > (SELECT AVG(salary) FROM employees) ORDER BY AVG(salary) DESC, department ASC LIMIT 5) ORDER BY avg_salary DESC, department ASC;
1、经典的SQL题目包括:
查询某个表中的前N行记录 查询某个表中的第N到第M行记录 查询某个表中的重复记录 查询某个表中的最大值、最小值、平均值和总和 查询某个表中的空值和非空值 查询某个表中的数据是否满足某个条件 查询某个表中的数据是否存在重复值 2、本次赛事中最有趣的题目可能是第三道题目,需要使用窗口函数来实现对数据的分组和排序,解决方法包括:
使用ROW_NUMBER()函数来实现对数据的排序和分组 使用RANK()函数来实现对数据的排序和分组 使用DENSE_RANK()函数来实现对数据的排序和分组
给定一个表格,其中有两列,分别为 id 和 score,请编写 SQL 语句,查询出分数排名第二的学生的 id 和 score
SELECT id, score FROM table_name
ORDER BY score DESC
LIMIT 1 OFFSET 1;
1、报表查询,通过多张表关联查询,并组合排序(注意:笛卡尔积)
①两张表,一般用逗号“,”和id进行关联
②多张表,使用逗号“,”和id进行关联时查询效率太慢,需要使用left join
2、数据仓库拉链表
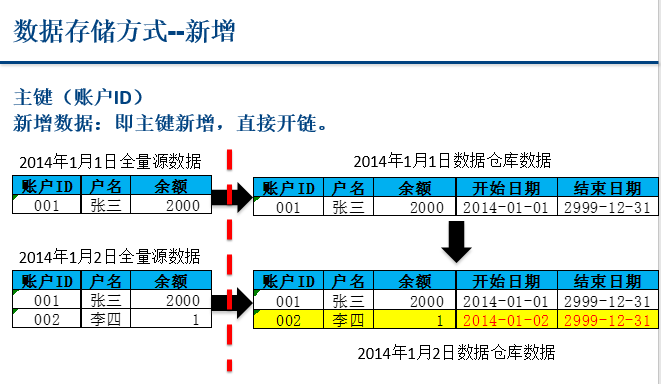

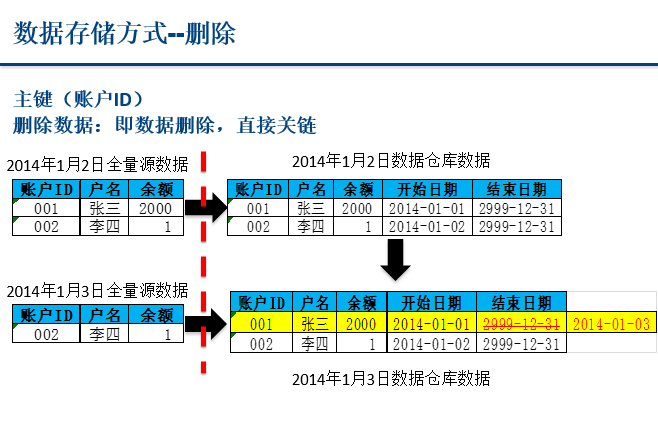
3、父子表级联删除(注意:删除数据时,先删除子表,再删除父表)
①通过业务代码实现
②通过创建触发器实现
SQL 是标准计算机语言,大部分 SQL 数据库程序都拥有它们自己的私有扩展!
SQL 对大小写不敏感!除非你对他做了特殊的处理!
大体上,SQL可以分为两种:数据操作语言 (DML) 和 数据定义语言 (DDL)
那肯定是学生、课程、成绩的问题。苦笑,每次面试手写题目基本上都包含这个。
本次赛题,本来想选择第二道题目,奈何下载测试数据之后,使用Navicat导入本地数据库不进去,不知道大佬们是如何处理的。但是在aliyun平台是可以导入进去的。也看了很多大佬的写法,感觉都没有注意一些细节点。我也没有好的方法。
SELECT
customers.customer_name,
COUNT(orders.order_id) AS order_count
FROM
customers
LEFT JOIN
orders ON customers.customer_id = orders.customer_id
GROUP BY
customers.customer_name
HAVING
COUNT(orders.order_id) > 10
ORDER BY
order_count DESC;
这个查询用于从一个包含客户和订单数据的数据库中获取客户的名称以及其订单数量。它使用了 LEFT JOIN 连接两个表,并通过 GROUP BY 子句将结果按客户分组。然后,使用 HAVING 子句筛选出订单数量大于10的客户,并通过 ORDER BY 子句按订单数量降序排序。
这个查询展示了 SQL 的一些重要概念,如表连接、分组、过滤和排序,对于处理数据库中的复杂数据非常有用。
在“找出各项考试中的佼佼者”这题目中,我觉得挺有意思的。我用的是子查询和联结的方式。
SELECT t.name AS test_name, s.name AS student_name, ta.score
FROM TestAttempt ta
JOIN Student s ON s.id = ta.studentId
JOIN Test t ON t.id = ta.testId
WHERE (
SELECT COUNT(DISTINCT score)
FROM TestAttempt
WHERE testId = ta.testId AND score > ta.score
) < 3
AND (
SELECT MAX(score)
FROM TestAttempt
WHERE studentId = ta.studentId
) = ta.score
ORDER BY t.name, ta.score DESC
这个查询语句使用了子查询和联结操作,实现了按顺序列出每门考试的分数最高的学生,同时包括并列前三名的情况。
具体来说,子查询 (SELECT COUNT(DISTINCT score) FROM TestAttempt WHERE testId = ta.testId AND score > ta.score) < 3 用于过滤出在同一门考试中得分排在第一到第三的学生,而 (SELECT MAX(score) FROM TestAttempt WHERE studentId = ta.studentId) = ta.score 条件用于过滤出每位学生的最高分数记录。
最经典的SQL: 查询表中的所有数据:编写一个SQL查询,返回指定表中的所有记录。 sql: SELECT * FROM table_name;
条件查询:编写一个SQL查询,返回满足特定条件的记录。 sql: SELECT * FROM table_name WHERE condition;
聚合函数:使用聚合函数计算表中的统计信息,如总数、平均值、最大值、最小值等。 sql: SELECT COUNT(*) FROM table_name; -- 计算记录总数 SELECT AVG(column_name) FROM table_name; -- 计算列的平均值 SELECT MAX(column_name) FROM table_name; -- 找出列的最大值 SELECT MIN(column_name) FROM table_name; -- 找出列的最小值
表连接:通过关联两个或多个表,返回相关联数据的查询结果。 sql: SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
分组和排序:使用GROUP BY子句对数据进行分组,并使用ORDER BY子句对结果进行排序。 sql: SELECT column_name(s) FROM table_name GROUP BY column_name ORDER BY column_name;
子查询:在一个查询中嵌套另一个查询,用于检索更复杂的数据。 sql: SELECT column_name FROM table_name WHERE column_name IN (SELECT column_name FROM table_name WHERE condition);
我认为最经典的sql题为: 题目:现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请你取出相应数据。 示例:question_practice_detail id device_id quest_id result date 1 2138 111 wrong 2021-05-03 2 3214 112 wrong 2021-05-09 3 3214 113 wrong 2021-06-15 4 6543 111 right 2021-08-13 5 2315 115 right 2021-08-13 6 2315 116 right 2021-08-14 7 2315 117 wrong 2021-08-15 根据示例,你的查询应返回以下结果: avg_ret 0.3000
SQL概述以及发展历程: 大多数数据库均使用SQL作为共同的数据存取语言和标准接口,使不同数据库系统之间的互操作有了共同的基础。SQL提出1974年,由IBM研究员发布了一篇揭开数据库技术的论文《SEQUEL:一门结构化的英语查询语言》,直到现在这门结构化的查询语言并没有太大的变化,想对比其他语言,SQL的半衰期可以说非常长了。SQL(Structured Query Language,结构化查询语言),称为许多数据库的标准语言,SQL标准也经历了不断发展的过程,增加了很多的功能与改变。目前没有一个数据库能够支持SQL标准的所有概念和特性,许多软件厂商对SQL基本命令集还进行了不同程度的扩充和修改,又可以支持标准以外的一些特性。 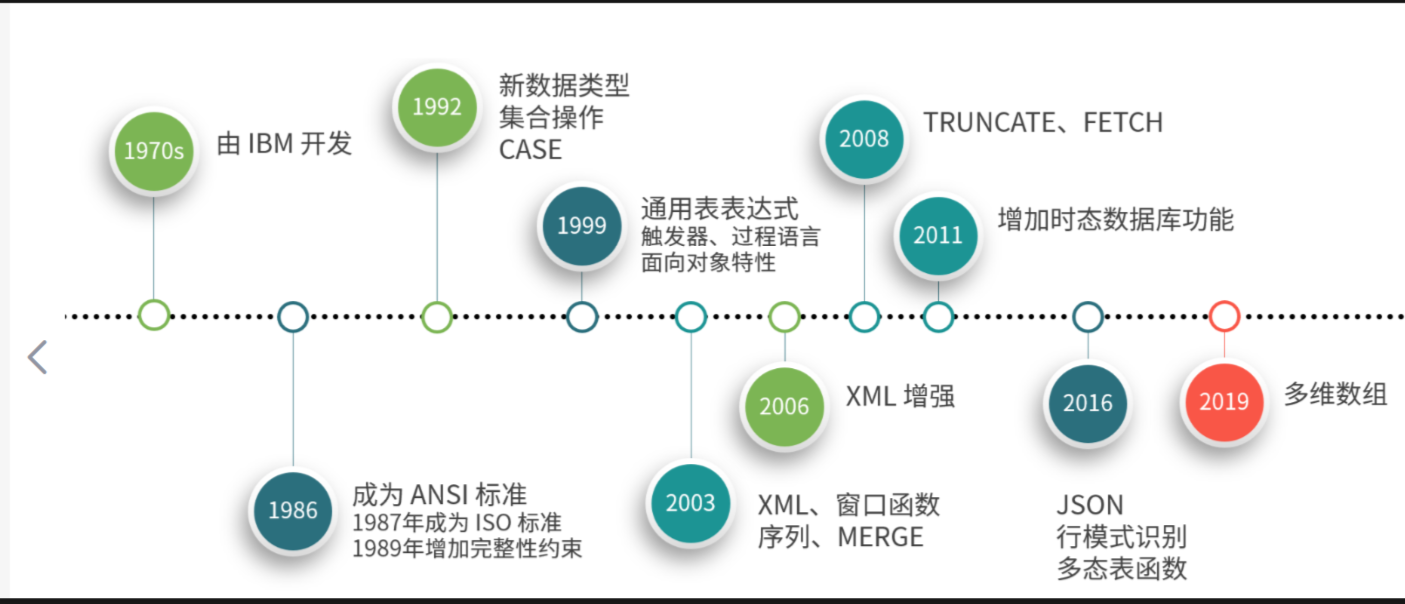
开发中遇到的SQL功能点: 在实际的开发中,可以说任何一个项目来说,都要使用到数据库的操作,也就离不开与sql进行打交道,目前市场上面常用的数据库有mysql、SQL Server、Oracle,这三种关系型数据库;还有一些就是NSQL的数据库,一般很少使用常规的sql语句进行编写处理。常用的功能就是报表的处理,在sql中实现报表的方式有很多种,最经典的是分页查询,然后汇总结果集的处理;比如说在一个大的数据库中需要查询出来本月里面,关于门票的售卖最多的是那个经典,这个就要使用到关联查询以及分页查询还有就是求出最大值的计算等等;涉及到的函数有max、group by、datediff、等等操作; 在查询比较慢的时候,需要对数据库表进行创建索引的方式提升查询的速度,比如说门票的基本信息表、门票的售卖表、订单表等等,这些表至少每个表都要一个主键、多个外键的处理。还有就是时间字段需要创建聚合索引等等方式来进行处理,便于根据时间查询的时候速度表快。 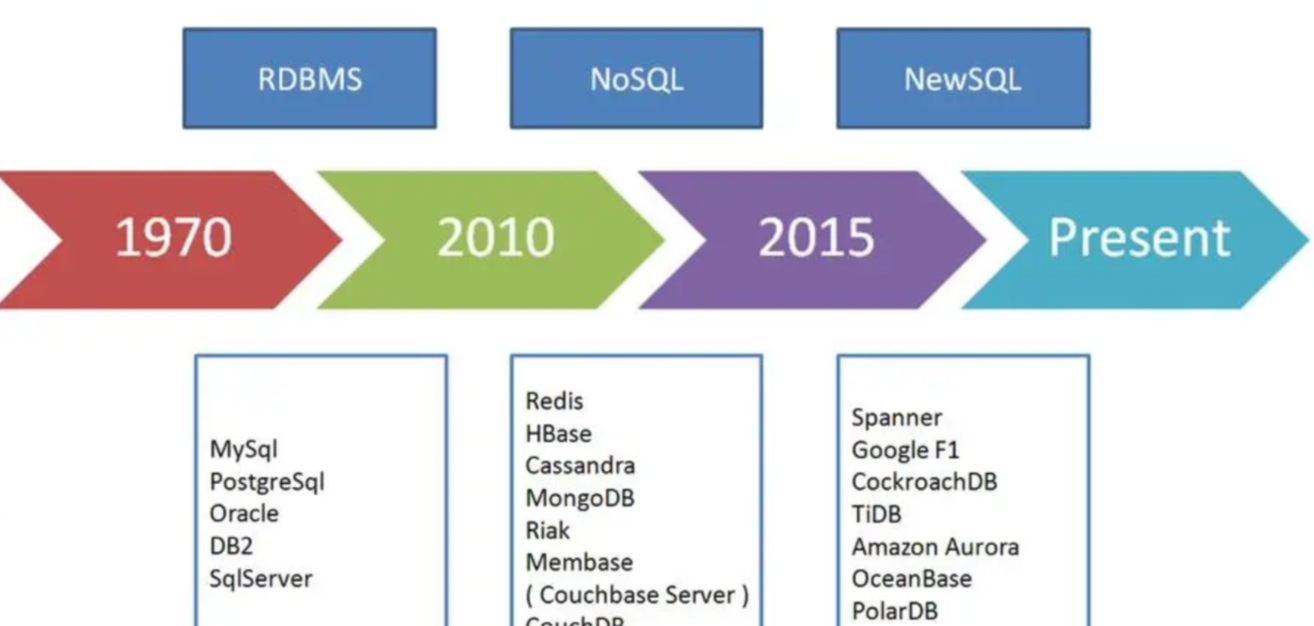
阿里云瑶池数据库SQL挑战赛题目解析: 通过本次参与阿里云瑶池数据库sql挑战赛,发现本次的三道题目都比较经典,本次参与的题目是:“编写一个SQL查询,找出每个考试中 得分最高的的考生 。若同一个考生有多条考试记录,则取最高分。如果存在并列,将并列的考生都列举出来,直到列举的考生达到或超过三人。”,这个是平时我们所经常会见到的题目,本人的解题思路是,首先需要查询分数表,求出分数表里面的最大值,然后关联查询测试表以及学生信息表,需要根据分数表查询出来,分数的个数,然后进行倒叙排列出来。 
最后: SQL已经深入到开发者的日常工作中,因为项目是要与数据打交道的,一个项目的核心就是数据,只不过是数据化的信息,比如说任何一个项目都有主业务一样,如何把项目可以数字化的帮助企业进行增加营收,以及减轻员工的工作是每个开发者的目标,只有不断的提升自己的能力,掌握更加先进的技术,才能实现这个目标。
最有意思的题目是,编写一个 SQL 查询,报告在首次游玩后的一周内至少再有一次游玩的玩家的比例,也就是注册首周内至少有两次登录的玩家占总玩家的比例,四舍五入到小数点后两位
以下是一个思考后简单 SQL 查询,可以报告首次游玩后的一周内至少再有一次游玩的玩家的比例,也就是注册首周内至少有两次登录的玩家占总玩家的比例,四舍五入到小数点后两位:
SELECT COUNT(DISTINCT player_id) / COUNT(DISTINCT game_id) AS ratio FROM login_history WHERE login_date BETWEEN DATE_SUB(NOW(), INTERVAL 1 WEEK) AND NOW() GROUP BY DATE(login_date) HAVING COUNT(DISTINCT player_id) >= 2 ORDER BY ratio ASC LIMIT 2; 这个查询使用了两个 SQL 关键词。首先,我们使用 COUNT(DISTINCT player_id) 来计算所有玩家的唯一玩家 ID 的数量,并使用 COUNT(DISTINCT game_id) 计算所有游戏 ID 的数量。然后,我们使用子查询来筛选首次游玩后的一周内至少有两次登录的玩家。最后,我们使用 GROUP BY 和 HAVING 子句来计算符合条件的玩家数量,并使用 ORDER BY 子句按照比例排序,并选取前两个结果。
请注意,这个查询只适用于支持 DISTINCT 关键字的数据库(如 MySQL、PostgreSQL 等)。如果您使用的是其他数据库,可能需要使用不同的语法来实现相同的功能。
我认为最经典的SQL题目应该是选择一个表,查询该表中某个列的最大值、最小值、平均值以及总和。例如: SELECT MAX(column_name) AS max_value, MIN(column_name) AS min_value, AVG(column_name) AS avg_value, SUM(column_name) AS sum_value FROM table_name; 这是一个基本的聚合函数练习,也是SQL基础知识的一部分。 我认为最有意思的是赛题三,赛题三里既涵盖了数学知识也针对性的考了SQL函数。需要将数学公式改成sql函数,要计算每个三角形的面积,我们需要使用三角形面积公式:area = 0.5 * |(x2-x1)(y3-y1) - (x3-x1)(y2-y1)|,其中(x1,y1),(x2,y2),(x3,y3)是三角形的三个顶点坐标。在本题中,我们可以通过连接Triangle表和Point表来获得每个三角形的三个顶点的空间坐标。以下是一个使用SQL计算每个三角形面积的示例:
SELECT ROUND(0.5 * ABS((Point1.X-Point2.X)(Point3.Y-Point1.Y) - (Point1.X-Point3.X)(Point2.Y-Point1.Y)), 2) AS area FROM A JOIN Point AS Point1 ON Triangle.pointId1 = Point1.id JOIN Point AS Point2 ON Triangle.pointId2 = Point2.id JOIN Point AS Point3 ON Triangle.pointId3 = Point3.id 上面的SQL查询语句中,我们首先使用了JOIN操作连接A表和B表三次,每次连接B表的不同行(即不同顶点)。然后,我们使用ABS函数计算三角形的绝对面积,使用ROUND函数将计算结果保留两位小数。请注意,此查询计算的是每个三角形的平面面积而不是空间面积。
统计吉大用户9月练题情况
1、用左连接把user和question连接起来,那么我们得到的结果首先就是所有的user的基本信息,如果答题了就会有答题的相关数据,如果没答题那么答题的相关数据为null。 2、COUNT(q.question_id)聚合函数是不计空值的,所以遇到空值默认为0了; 利用SUM() 和case when... then去计算答对的题数。 3、筛选条件时要注意月份,只敲MONTH(date) = 9是不够的,这样会遗漏那些没有答题的同学,所以要加上MONTH(date) IS NULL。 4、最后GROUP BY device_id求出所有吉林大学的同学的情况
SELECT
u.device_id,
u.university,
COUNT(q.question_id) AS question_cnt,
SUM(CASE WHEN result = 'right' THEN 1
ELSE 0 END) AS right_question_cnt
FROM user_profile u
LEFT JOIN question_practice_detail q
USING(device_id)
WHERE university = '吉林大学' AND (MONTH(date) = 9&nbs***bsp;MONTH(date) IS NULL)
GROUP BY device_id;
假设有两个表格,一个是名为“Employees”的员工表格,另一个是名为“Salaries”的员工薪资表格。它们的结构如下:
Employees表格:
Column Name Data Type Description
EmployeeID int 员工ID
FirstName varchar(50) 名字
LastName varchar(50) 姓氏
Department varchar(50) 部门
HireDate date 入职日期
TerminationDate date 离职日期
Salaries表格:
Column Name Data Type Description
EmployeeID int 员工ID
Salary int 薪资
EffectiveDate date 生效日期
TerminationDate date 终止日期
问题:找出每个部门中获得最高薪资的员工。
思考过程:
这个问题需要使用SQL聚合函数和子查询来解决。我们需要首先找出每个部门中获得最高薪资的员工,然后将它们组合成一个结果集。下面是详细的思考和求解过程:
Step 1: 找出每个部门中获得最高薪资的员工
我们可以使用以下SQL查询语句来找出每个部门中获得最高薪资的员工:
Copy
SELECT Department, MAX(Salary) AS MaxSalary
FROM Employees
INNER JOIN Salaries
ON Employees.EmployeeID = Salaries.EmployeeID
GROUP BY Department
这个查询语句将两个表格进行了内连接,将相同的员工ID关联在一起。然后按照部门分组,并找出每个部门中获得最高薪资的员工。这个查询语句将返回一个结果集,其中包含每个部门的名称和该部门中获得最高薪资的员工的薪资。
Step 2: 找出每个部门中获得最高薪资的员工的详细信息
接下来,我们需要找出每个部门中获得最高薪资的员工的详细信息,包括他们的姓名和薪资。我们可以使用以下查询语句来实现:
n1ql
Copy
SELECT E.Department, E.FirstName, E.LastName, S.Salary
FROM Employees E
INNER JOIN Salaries S ON E.EmployeeID = S.EmployeeID
INNER JOIN (
SELECT Department, MAX(Salary) AS MaxSalary
FROM Employees
INNER JOIN Salaries
ON Employees.EmployeeID = Salaries.EmployeeID
GROUP BY Department
) T ON E.Department = T.Department AND S.Salary = T.MaxSalary
这个查询语句使用了三个表格:Employees、Salaries和一个子查询。子查询返回了每个部门中获得最高薪资的员工的薪资。然后,我们将这个子查询与Employees和Salaries表格进行内连接,将相同的员工ID关联在一起。最后,我们使用T表格中的部门和最高薪资来筛选出每个部门中获得最高薪资的员工的详细信息。
总结:
这个SQL问题需要使用聚合函数和子查询来解决,涉及到多个表格的内连接和分组。通过上述步骤,我们可以找出每个部门中获得最高薪资的员工的详细信息。
有一个朋友参加了世界500强企业的面试,问了一道sql题目?
他毕业于一所普通的大学,虽然专业是计算机科学,但由于学校教育水平的限制,他并没有掌握很多实用的技能。但他从小就喜欢电脑和编程,对于软件开发也有着自己的想法和见解。因此,他开始自学各种编程语言,并通过参加各种比赛和项目实践来提高自己的技能。
然而,在找工作的过程中,他遇到了重重困难。他的简历不够出色,找到面试的机会非常有限。每次面试时,他也总是因为没有足够的经验和知识而遭遇失败。尽管如此,他从未放弃,仍然继续努力学习,积极寻找机会。
某天,他偶然得知世界500强公司正在招聘软件开发工程师,他决定抓住这个机会。他花费了大量时间和精力准备面试,阅读了大量的文献资料,学习了各种技术和知识。他认为只要自己付出足够的努力,就一定会得到这个机会。
在面试的时候,他遇到了一道非常难的SQL题目。但是,由于他之前的努力和准备,他很快就想到了正确的解决方法,并成功地回答了这道问题。他还通过自信、清晰和有条理的表达方式,给面试官留下了深刻印象。
最终,在经过多轮面试后,他被这家世界500强公司录用了。他开始踏上了自己的职业生涯,一步步实现着自己的梦想。
题目如下
题目:有一个订单表和一个商品表,每个订单包含多个商品,现在需要统计每个商品被下单的总量,并按照总量从高到低排序。其中,订单表与商品表通过订单编号关联,商品表中包含商品编号和商品名称两列,订单表中包含订单编号和商品编号两列。
例子: 订单表(order):
订单编号 商品编号
1 100
1 200
2 100
3 300
3 200
4 300
商品表(product):
商品编号 商品名称
100 商品A
200 商品B
300 商品C
要求:按照商品被下单的总量从高到低排序,输出商品编号、商品名称和商品被下单的总量。
思考过程:
首先,我们需要对订单表进行分组,统计每个商品被下单的总量。这里使用GROUP BY语句,将订单表按照商品编号进行分组,并使用SUM函数计算每个商品被下单的总量。
SELECT order.商品编号, SUM(1) AS 下单数量 FROM 订单表 order GROUP BY order.商品编号
得到结果:
商品编号 下单数量
100 2
200 2
300 2
接下来,我们需要将上面的结果按照下单数量从高到低排序,并输出商品编号和商品名称。这里可以使用INNER JOIN语句连接订单表和商品表,获取每个商品的名称,然后使用ORDER BY语句按照下单数量从高到低排序。
SELECT order.商品编号, product.商品名称, SUM(1) AS 下单数量 FROM 订单表 order INNER JOIN 商品表 product ON order.商品编号 = product.商品编号 GROUP BY order.商品编号, product.商品名称 ORDER BY 下单数量 DESC
得到最终结果:
商品编号 商品名称 下单数量
100 商品A 2
200 商品B 2
300 商品C 2
以上就是这道SQL题目的详细思考和求解过程。
只要不放弃,坚持努力,即使从小没有受到良好的教育,也可以通过自学和实践来提高自己的技能。只要有足够的热情和毅力,任何人都可以成为优秀的软件开发工程师。同时,这个故事也告诉我们,每一个机会都需要我们争取,只要我们付出足够的努力,就有可能实现自己的梦想。
数据库模型设计:数据库模型是关系数据库设计的基础,对于不同的业务场景需要选择合适的模型,合理地设计表结构。在这个过程中需要考虑到数据库的性能、可扩展性、数据完整性等方面,可以体现出设计师的创造力和思考能力。
数据查询:SQL 语言最基本的功能是对数据进行查询,在查询中可以使用多种关键字和操作符,如 SELECT、FROM、WHERE、GROUP BY、HAVING 等,可以实现非常复杂的查询。通过不断练习和调试,可以发现很多有趣的查询方式,例如将多个表进行联合查询,构建更加复杂的查询语句。
数据库事务:事务是保证数据库数据一致性的重要机制,SQL 语言提供了多个支持事务的关键字和操作符,如 COMMIT、ROLLBACK、SAVEPOINT 等。通过学习事务,可以更好地理解数据库的 ACID 属性,进而提高数据库性能和稳定性。
数据库优化:在实际的工作中,数据库的性能优化和调优是非常重要的,只有保证数据库的高性能才能更好地支持业务需求。SQL 语言提供了多个优化相关的操作符和关键字,例如索引、分区、视图等,在学习优化过程中可以发现很多有趣的调优技巧,也可以让自己的 SQL 代码更加高效。
数据库设计和范式理论:在学习SQL的过程中,了解如何设计和规范关系型数据库的表结构,以及如何优化表结构,可以帮助我们更好地理解SQL的应用场景和优化技巧。
数据库查询优化:SQL查询性能是数据库应用的重要指标之一,了解如何优化SQL查询语句、使用索引和分区等技术,可以帮助我们提高查询效率和数据处理能力。
数据库事务和锁机制:在多用户并发访问数据库时,事务和锁机制可以保证数据的一致性和可靠性,了解这些概念和技术可以帮助我们更好地处理并发访问和数据更新的问题。
数据库的高级特性:SQL具有很多高级特性,如窗口函数、递归查询、动态SQL等,这些特性可以帮助我们更高效地处理复杂的数据分析和处理任务。
总的来说,SQL是一门非常实用的技能,通过学习SQL,可以帮助我们更好地理解和处理数据,提高数据处理和分析的能力。
以下是一道难度较大的SQL题目,它需要运用多种SQL技巧,包括子查询、视图、聚合函数和窗口函数等,希望对你有所帮助。
题目:
有一张orders表,包含订单的id、用户id、订单金额和订单创建时间等信息。请编写一个SQL查询语句,查询每个用户的第一笔订单和最后一笔订单的订单金额差值,如果用户只有一笔订单,则差值为0。并将结果按照差值从大到小排序。
解题过程:
首先,我们需要使用子查询和视图分别获取每个用户的第一笔订单和最后一笔订单的订单金额。然后,我们需要使用聚合函数和窗口函数计算出每个用户的第一笔订单和最后一笔订单的订单金额差值。最后,我们使用ORDER BY语句将结果按照差值从大到小排序。
代码如下:
SELECT user_id, MAX(last_order_amount) - MAX(first_order_amount) AS diff_amount
FROM (
SELECT user_id,
MIN(order_amount) OVER (PARTITION BY user_id ORDER BY order_date) AS first_order_amount,
MAX(order_amount) OVER (PARTITION BY user_id ORDER BY order_date) AS last_order_amount
FROM (
SELECT user_id, order_amount, order_date,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_date) AS row_num
FROM (
SELECT user_id, order_amount, order_date,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_date) AS row_num
FROM orders
) t1
WHERE row_num = 1 OR row_num = (SELECT COUNT(*) FROM orders t2 WHERE t1.user_id = t2.user_id)
) t3
) t4
GROUP BY user_id
ORDER BY diff_amount DESC;
解释一下代码:
首先,我们使用子查询和ROW_NUMBER()窗口函数获取每个用户的第一笔订单和最后一笔订单,其中子查询t1用于获取每个用户的订单列表,并按照订单日期排序,ROW_NUMBER()函数用于给每个用户的订单编号。然后,我们使用WHERE子句将只保留每个用户的第一笔订单和最后一笔订单。接着,我们使用视图和MAX()聚合函数获取每个用户的第一笔订单和最后一笔订单的订单金额。最后,我们使用MAX()和GROUP BY语句计算出每个用户的订单金额差值,并使用ORDER BY语句按照差值从大到小排序。
总的来说,这道题目难度比较大,需要运用多种SQL技巧来解决问题,其中最难的部分可能是使用子查询和视图获取每个用户的第一笔订单和最后一笔订单。
赛题三:
题目描述:给定三维空间内三角形三个顶点的坐标,请编写一个SQL查询语句,计算该三角形的面积。
解题思路:使用海伦公式计算三角形面积,公式如下:
s = sqrt(p(p-a)(p-b)(p-c))
其中,p为半周长,a、b、c为三角形三条边的长度。 代码如下:
SELECT sqrt(p*(p-a)*(p-b)*(p-c)) AS area
FROM (
SELECT
sqrt(pow(x1-x2, 2) + pow(y1-y2, 2) + pow(z1-z2, 2)) AS a,
sqrt(pow(x1-x3, 2) + pow(y1-y3, 2) + pow(z1-z3, 2)) AS b,
sqrt(pow(x2-x3, 2) + pow(y2-y3, 2) + pow(z2-z3, 2)) AS c,
(a+b+c)/2 AS p
FROM triangle
) t;
本次赛事中最有意思的题目可能是第三道题目,需要将数学公式转化为SQL语言,考验了参赛者的数学功底和编程能力。针对该题目,高效解法就是使用子查询和计算字段的方式将公式转化为SQL语言,避免重复计算和代码冗长。
1、印象深刻的SQL题 个人印象比较深的sql是使用JOIN 连接时,条件为以逗号分隔的字段与另一张表的 ID 相匹配做的查询。比如下图:
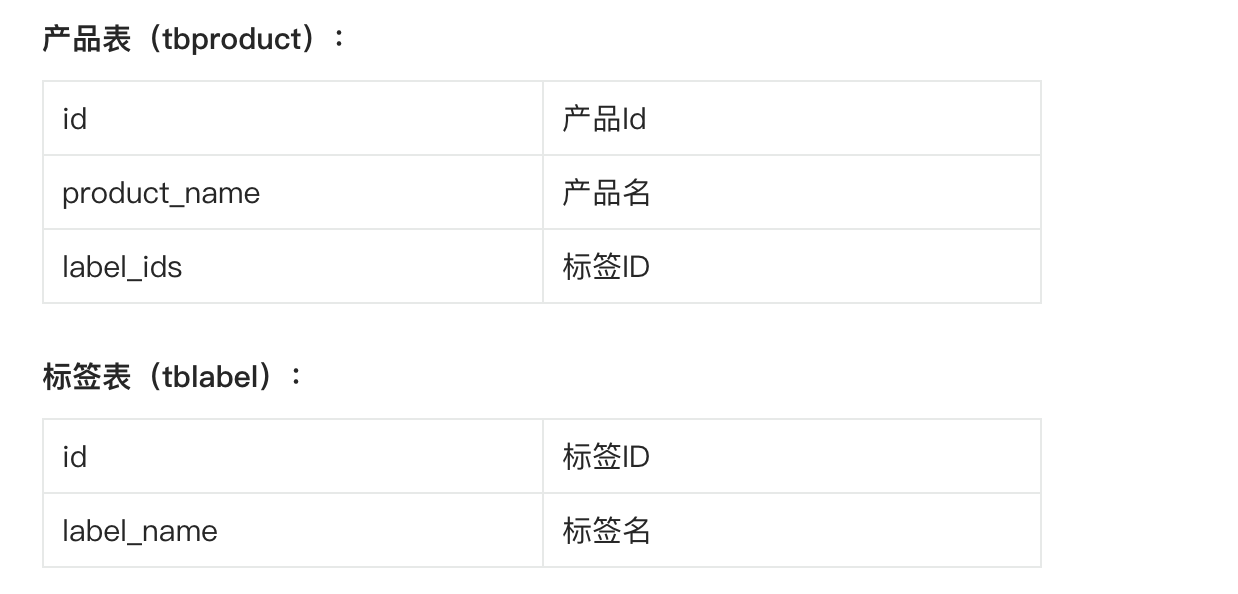
SQL为:
t1.id,
t1.product_name,
GROUP_CONCAT( t2.label_name SEPARATOR "-" ) AS label_names,
t1.label_ids
FROM
tbproduct t1
LEFT JOIN `tblabel` t2 ON FIND_IN_SET( t2.id, t1.label_ids )
GROUP BY
t1.`id`
查询后的结果为: 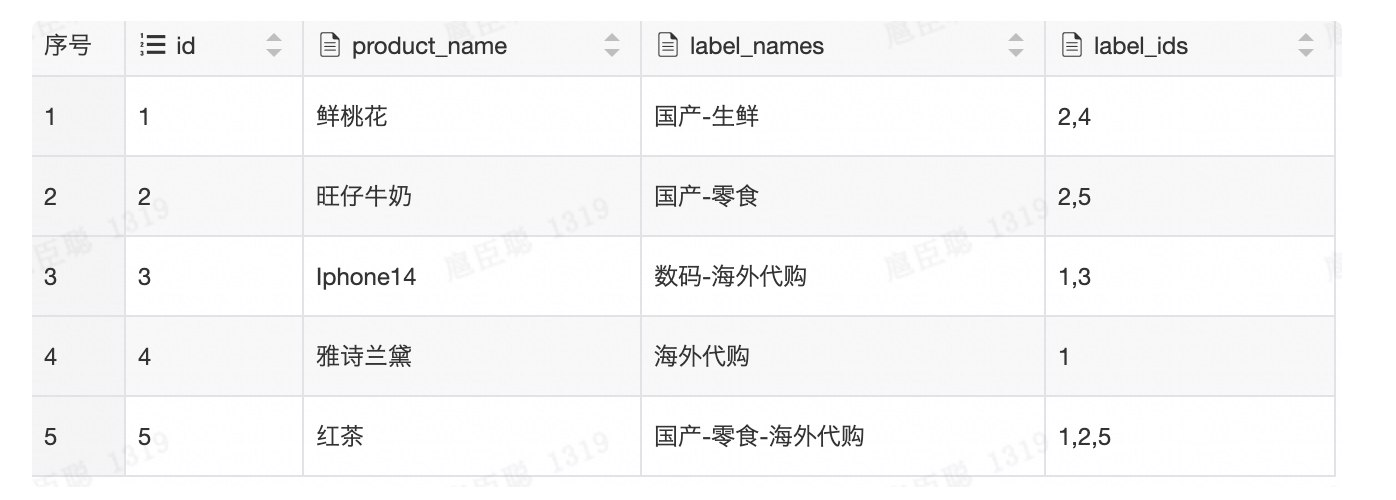
2、本次赛事中哪道题目最有意思?针对该题目有什么高效解法? 我觉得赛题三比较有意思,既考了数学知识也考了SQL函数。解题思路其实比较简单,在确认使用哪种公式计算三角形面积后剩下的SQL就简单了。 已知三个点的坐标,所以我们首先能得到的就是三角形的三条边的长度,由此会想到用海伦公式计算:
S=sqrt[p(p-a)(p-b)(p-c)]
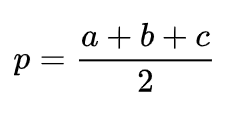
这个公式经过演算到套入三点的x,y,z坐标后会变得很复杂,因此放弃这个公式解法。 另一种三角形的面积求法为向量叉积的计算方式:

由此,公式就变的比较简单了,并且转化为SQL后也比较容易了。
不由得感叹一下,学好数理化,走遍天下都不怕呀。
SQL(Structured Query Language,结构化查询语言),是一种用于管理和操作关系型数据库的标准计算机语言,其语法相对简洁,但实际运用中足够灵活。
在学习SQL过程中,我发现这种语言的运用不仅是一种工具,更是一种思维方式。使用SQL可以帮助我们有效地发掘数据中的潜在价值,最终为业务决策提供有效的支持。
SQL的基本语法包括:SELECT, INSERT, UPDATE, DELETE, CREATE, ALTER和DROP等基本语句,以及包括GROUP BY,HAVING和ORDER BY等扩展语法。
当我学习SQL时,我觉得最有趣的部分是数据分析和可视化。通过使用SQL,我可以通过处理有关数据的问题来发现问题的根源,进而产生洞察力和绩效提升。
SQL对于软件开发来说也是非常重要的一环,因为大多数应用程序都需要对数据进行存储、检索和更新。在软件系统中,数据库也是一种非常重要的组成部分,它聚合了应用程序的业务规则和数据,提供数据深度解析、预测和洞察。数据库的优化对系统的整体性能、稳定性和用户体验至关重要。
回到题目,我认为最经典的SQL题目是关于如何筛选出某一特定日期和时间范围内的数据。这个题目经常涉及到实际应用中的数据筛选和处理,具有广泛的实用价值。在语法上,涉及到的基本表达式包括:BETWEEN、AND和DATEPART等。在实际操作中,我们可以使用以下语句来解决这个具体问题:
SELECT * FROM [table_name] WHERE [date_field] BETWEEN '[start_date]' AND '[end_date]';
其中,[table_name]是表名,[date_field]是日期字段,[start_date]是日期范围的开始日期,[end_date]是日期范围的结束日期。这个问题是SQL初学者最常遇到的问题之一,但它可以帮助我们更好地理解SQL的语法和灵活性。
在阿里云瑶池数据库SQL挑战赛中,我认为最有趣的问题是关于如何查找出现频率最高的词汇的问题。这个问题通常是在文本分析和数据挖掘等领域中使用的。在语法上,涉及到的基本表达式包括:GROUP BY和COUNT等。在实际操作中,我们可以使用以下语句来解决这个具体问题:
SELECT [column_name], COUNT() FROM [table_name] GROUP BY [column_name] ORDER BY COUNT() DESC LIMIT 1;
其中,[column_name]是文本列名,[table_name]是表名,上面的语句将按照文本列中出现最多的单词进行排序。这个问题比较有趣,并且具有广泛的实用价值,因为它可以帮助我们挖掘文本数据的潜在价值,并为企业提供报表、分析或使用的决策支持。
在解决上述两个问题时,我学习到了SQL的语法和灵活性。在实际应用中,SQL可以帮助我们从数据中发现潜在的价值和一致性,同时也可以帮助我们进行遥测方案设计、缩减数据负载和更好的数据分析。除此之外,SQL还可以帮助我们更好地进行数据可视化,从而为业务决策提供更好的支持。最终,SQL对于企业决策、产品管理和用户体验的提升都具有非常重要的作用,尤其是在今天的数据时代。

