
flink1.16.1 配合flinkcdc2.3.0 还需要加上其他依赖吗? org.apache.flink flink-streaming-java com.ververica flink-sql-connector-mysql-cdc org.apache.flink flink-java 和 org.apache.flink flink-streaming-java 可以2选1吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
link 1.16.1 配合 Flink CDC 2.3.0 所需的依赖项,包括 org.apache.flink 的 flink-streaming-java 和 flink-java,以及 com.ververica 的 flink-sql-connector-mysql-cdc。
org.apache.flink 的 flink-streaming-java 和 flink-java 确实可以二选一,因为它们是 Flink 的不同组件。如果您使用的是 Flink 的流处理功能,您需要添加 flink-streaming-java 依赖项。如果您使用的是 Flink 的批处理功能,您需要添加 flink-java 依赖项。
楼主你好,使用阿里云的Flink 1.16.1配合Flink CDC 2.3.0时,需要添加以下依赖: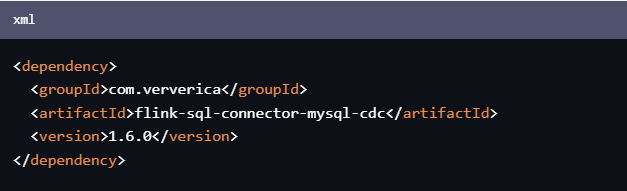
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<version>1.6.0</version>
</dependency>
同时,需要保证依赖的版本与Flink相应版本兼容。
对于org.apache.flink flink-java和org.apache.flink flink-streaming-java,它们是Flink核心库,都是必需的。如果你只需要使用流式处理的功能,可以只依赖flink-streaming-java。如果你还需要使用Flink的批处理功能,那么就需要同时依赖flink-java和flink-streaming-java。
总之,在使用Flink时,不同版本的依赖很重要,需要仔细匹配版本。
在使用 Flink 1.16.1 配合 Flink CDC 2.3.0 时,您可能需要添加其他依赖项,具体取决于您的具体需求和配置。以下是一些常见的依赖项:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.16.1</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.16.1</version>
</dependency>
请注意,上述示例中的版本号适用于 Scala 2.11。如果您使用的是其他 Scala 版本,请相应地调整 artifactId 中的 "_2.11" 后缀为相应的版本号。
至于 Flink Streaming Java 和 Flink Java 之间的选择,取决于您的具体需求和代码实现方式。如果您使用 Flink Table & SQL API 构建流处理作业,那么通常需要同时引入 Flink Streaming Java 和 Flink Table & SQL 依赖项。但如果您仅使用 Flink Streaming Java API 编写作业,而不使用 Flink Table & SQL API,则可以选择只引入 Flink Java 依赖项。
最后,确保在引入这些依赖项时与您的项目的其他依赖项和版本兼容,并根据实际情况进行适当调整。
如果你想在 Flink 1.16.1 中使用 Flink CDC 2.3.0,你需要在项目中添加 Flink CDC 的依赖。具体来说,你需要添加以下依赖:
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-cdc-plugin</artifactId>
<version>2.3.0</version>
</dependency>
此外,你还需要添加 Flink 和 Flink JDBC 的依赖,例如:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.16.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java_2.12</artifactId>
<version>1.16.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.12</artifactId>
<version>1.16.1</version>
</dependency>
关于你提到的 org.apache.flink flink-streaming-java 和 org.apache.flink flink-java 依赖,它们是相同的,因此你可以选择其中一个。同样地,对于 com.ververica flink-sql-connector-mysql-cdc 和 org.apache.flink flink-jdbc 依赖,它们也是相同的,因此你可以选择其中一个来连接 MySQL 数据库。
如果你想使用 Flink CDC 2.3.0 版本,你需要确保你的项目使用的是 Flink 1.16.x 版本或更高版本。如果你使用的是早期版本的 Flink,你需要使用 Flink CDC 的早期版本。
在使用 Flink 1.16.1 配合 Flink CDC 2.3.0 时,除了需要添加 Flink 和 Flink CDC 的依赖之外,还可能需要添加其他依赖,具体取决于你的使用场景和需求。以下是一些可能需要添加的常见依赖:
Flink Core 依赖:除了 Flink 的核心模块之外,你可能还需要添加其他的 Flink 依赖,如 flink-java 和 flink-streaming-java。这些依赖通常是必需的,因为它们包含了 Flink 的核心功能和 API。
数据库连接器依赖:如果你打算使用 Flink CDC 连接到特定的数据库,你需要添加相应的数据库连接器依赖。例如,如果你要连接到 MySQL 数据库,则需要添加 flink-sql-connector-mysql-cdc 依赖。
根据你的问题,flink-java 和 flink-streaming-java 是 Flink 的两个模块,flink-java 包含了 Flink Core 和基本的流处理功能,而 flink-streaming-java 则是在 flink-java 的基础上添加了流处理的功能。在 Flink 1.16.1 中,建议使用 flink-streaming-java 模块,因为它更全面且包含了更多的功能。
在使用 Flink 1.16.1 版本配合 Flink CDC 2.3.0 进行开发时,除了上述提到的依赖外,还需要添加其他一些必要的依赖。以下是建议的完整依赖列表:
xml
org.apache.flink flink-java 和 org.apache.flink flink-streaming-java 这两个依赖,它们是 Flink 的核心依赖之一,用于支持 Flink 的基本功能和流式处理。在上述的完整依赖列表中已经包含了 flink-streaming-java 的依赖,因此你可以选择其中一个来添加到项目中即可。如果您想要在Flink 1.16.1中使用Flink CDC 2.3.0,那么您需要在项目中添加Flink CDC的依赖。您可以在Maven或Gradle中添加以下依赖:
flink-cdc:这是Flink CDC的主要依赖,包含了Flink CDC的核心功能。
mysql-cdc:这是Flink CDC支持MySQL数据源的依赖,包含了MySQL CDC的核心功能。
fasterxml.jackson:这是Flink CDC使用的JSON序列化和反序列化库,用于将JSON数据写入目标数据库。
关于您提到的org.apache.flink flink-streaming-java和org.apache.flink flink-java,它们是Flink的主要依赖,包含了Flink的核心功能。如果您想要使用Flink CDC,那么您需要在项目中添加flink-cdc依赖,而不是这两个依赖。
需要注意的是,不同的情况可能需要不同的依赖,因此需要根据具体情况进行调整和优化。同时,您可以使用Flink CDC提供的TableFunction接口,自定义一个TableFunction实现类,对读取到的数据进行特殊过滤,以避免出现表字段变少的情况。

