
dataworks配置完成后,如何依赖代码血缘分析不匹配
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,血缘分析是在调度周期完成后再进行的。如果依赖的代码有变更,可能会导致血缘分析不匹配。
如果发现血缘分析不匹配,可以尝试以下步骤:
确认代码是否有变更,如果有变更则重新提交任务。
确认代码是否存在问题,例如语法错误等,可以查看日志定位问题并进行修复。
当任务依赖配置完成后,提交的窗口会有一个选项:当输入输出和代码血缘分析不匹配时,是否确认继续执行提交操作。该选项的前提是您已经确认依赖关系正确。如果不能确认,则可以按照上述方法确认依赖关系。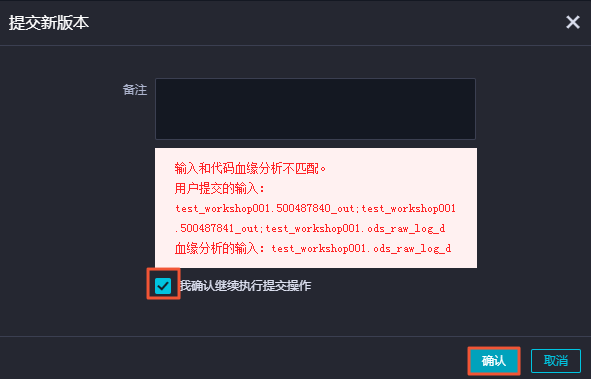 确认依赖关系无误后,直接勾选我确认继续执行提交操作,并单击确认。 https://help.aliyun.com/document_detail/94780.html 此回答整理自钉群“DataWorks交流群(答疑@机器人)”
确认依赖关系无误后,直接勾选我确认继续执行提交操作,并单击确认。 https://help.aliyun.com/document_detail/94780.html 此回答整理自钉群“DataWorks交流群(答疑@机器人)”
会出现输入与代码血缘关系不匹配的提示,可能是代码中删除输入输出→找不到产出该表数据的节点任务>表数据是固定的? 也就是在代码中 select 表或者是 insert 的表,但是在节点的依赖关系这里没有将它作为输入或者输出,通过代码的解析和配置的节点依赖不匹配,所以会出现提示。
解决办法确认这张表的数据源来源,本地上传的表数据,可忽略血缘关系不一致的提示,是DataWorks周期调度产出的表数据,请务必再次确认产出该表数据的节点是否有将该表作为节点输出。因为通过表没有找到这产出表数据的节点方式。
方式二:手动添加上游依赖 场景一:需要依赖某个表数据。 场景二:需要依赖某个节点,不一定存在表血缘依赖。那需要依赖某个节点时可以输入那个节点的输出,如果需要依赖某个表数据,那可以直接在依赖的上游这里直接输入表名,但是前提是要确认它表是每天周期调度产出的表。
方式三:自动推荐 自动推荐: 当自动解析选择为否时,您可以使用自动推荐功能自定义添加需要依赖的上游节点。自动推荐功能会自动解析出所有已经提交并发布至生产环境,并且实际运行产出该表的节点。
因为同步任务是不支持调度依赖自动解析的,所以同步任务配置调度依赖时需要手动配置一下。
出现血缘关系不正确的原因如下: 根据自动解析我们可以知道,当下游查询该表的数据时,自动解析会将该表作为当前节点的上游依赖,但在一开始并未将该表作为节点的输出,导致提交任务时报错依赖的父节点输出不存在,没有根据该表找到产出该表数据的上游任务。如果出现血缘关系不匹配的提示,那再三确认一下代码中用到的表是不是本地上传的,还是周期调度每天调度产出的,如果是周期调度产出的,那一定要再确认一下。产出表数据的节点,有没有将表作为节点输出?
以上仅供参考。
DataWorks 新版本在配置任务依赖的时候,是根据本节点输出名称作为关联项来给任务间设置依赖关系的,楼主可以参考这篇文章-DataWorks 如何设置调度依赖。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



