
DataWorks创建EMR Hive节点操作步骤?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
进入数据开发页面。登录DataWorks控制台。在左侧导航栏,单击工作空间列表。选择工作空间所在地域后,单击相应工作空间后的进入数据开发。鼠标悬停至图标,单击EMR > EMR Hive。您也可以找到相应的业务流程,右键单击EMR,选择新建 > EMR Hive。在新建节点对话框中,输入节点名称,并选择目标文件夹。说明 节点名称必须是大小写字母、中文、数字、下划线(_)和小数点(.),且不能超过128个字符。单击提交。在节点编辑页面,输入代码。-- SQL语句示例。-- SQL语句最大不能超过130KB。show tables;-- 可以结合调度参数使用。select 'unknown';-- 系统会自动为SELECT语句加上'limit 10000'的限制。select * from userinfo ;调度参数使用详情可参考文档:基础属性:调度参数如果您需要修改代码中的参数赋值,请单击界面上方工具栏的高级运行。参数赋值逻辑详情请参见:运行,高级运行和开发环境冒烟测试赋值逻辑有什么区别 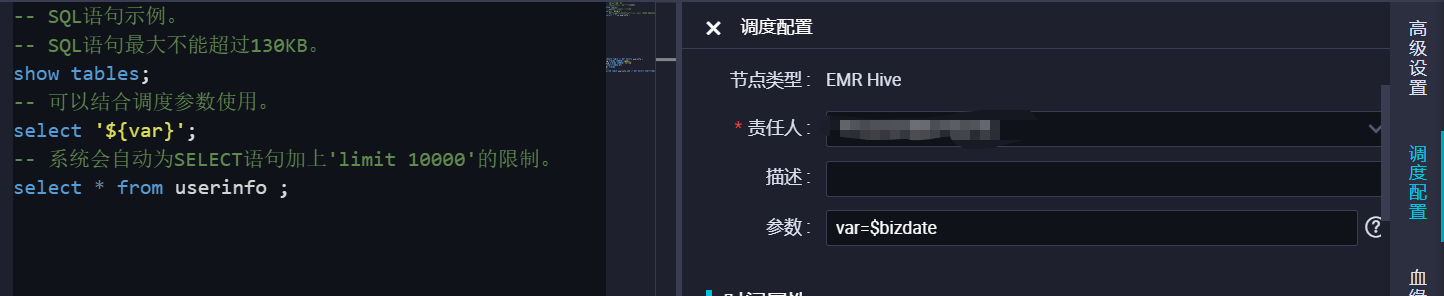 相关文档:Hive SQL作业配置说明 如果您的工作空间绑定多个EMR引擎,需要选择EMR引擎。如果仅绑定一个EMR引擎,则无需选择。编辑高级配置。"USE_GATEWAY":true ,表示任务会被提交到EMR gateway上执行,默认提交到header节点。"SPARK_CONF": "--conf spark.driver.memory=2g --conf xxx=xxx" ,设置spark 任务运行参数,多个参数在该key中追加。“queue”:提交作业的调度队列,默认为default队列。“vcores”: 虚拟核数,默认为1。“memory”:内存,默认为2048MB(用于设置启动器Launcher的内存配额)。“priority”:优先级,默认为1。“FLOW_SKIP_SQL_ANALYZE”:SQL语句执行方式,参数值为false表示每次执行——该回答整理自钉群“DataWorks交流群(答疑@机器人)“
相关文档:Hive SQL作业配置说明 如果您的工作空间绑定多个EMR引擎,需要选择EMR引擎。如果仅绑定一个EMR引擎,则无需选择。编辑高级配置。"USE_GATEWAY":true ,表示任务会被提交到EMR gateway上执行,默认提交到header节点。"SPARK_CONF": "--conf spark.driver.memory=2g --conf xxx=xxx" ,设置spark 任务运行参数,多个参数在该key中追加。“queue”:提交作业的调度队列,默认为default队列。“vcores”: 虚拟核数,默认为1。“memory”:内存,默认为2048MB(用于设置启动器Launcher的内存配额)。“priority”:优先级,默认为1。“FLOW_SKIP_SQL_ANALYZE”:SQL语句执行方式,参数值为false表示每次执行——该回答整理自钉群“DataWorks交流群(答疑@机器人)“
https://help.aliyun.com/document_detail/137518.html 创建EMR Hive节点 
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



