
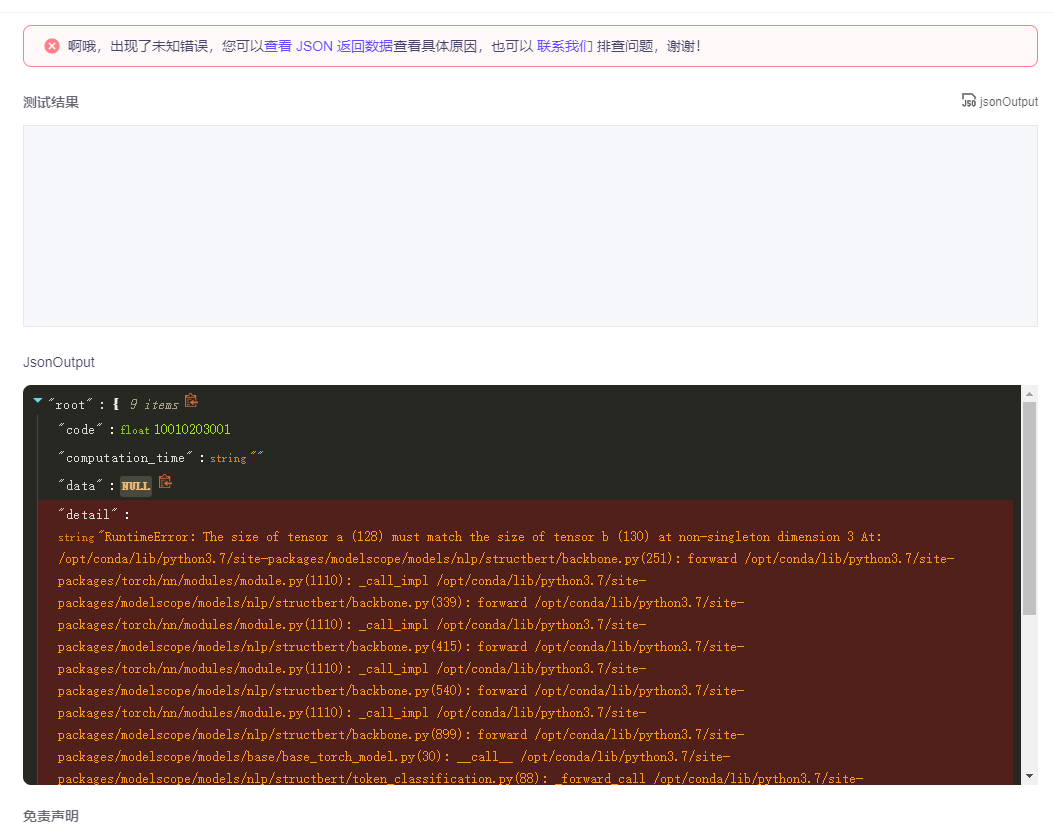
ModelScope中分词模型输入128个字符会报错,无论是网页上还是本地运行都会,请问这里是限制字符长度有问题还是模型内tensor问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
BERT分词模型默认的tokenizer长度是128,分词输入的时候前后添加一个特殊字符的padding, 所以默认能支持的最大长度是128-2=126;长度需要增加的话可以在modelScope的代码里面修改,参考: https://github.com/modelscope/modelscope/blob/master/modelscope/preprocessors/nlp/token_classification_preprocessor.py#L223,但是最长不能超多BERT输入的最大长度512。此答案整理自钉钉群“魔搭ModelScope开发者联盟群 ①”

