
为啥obdumper导出来的分区表的分区数量对不上呢?有的分区表子分区直接就没了呢? 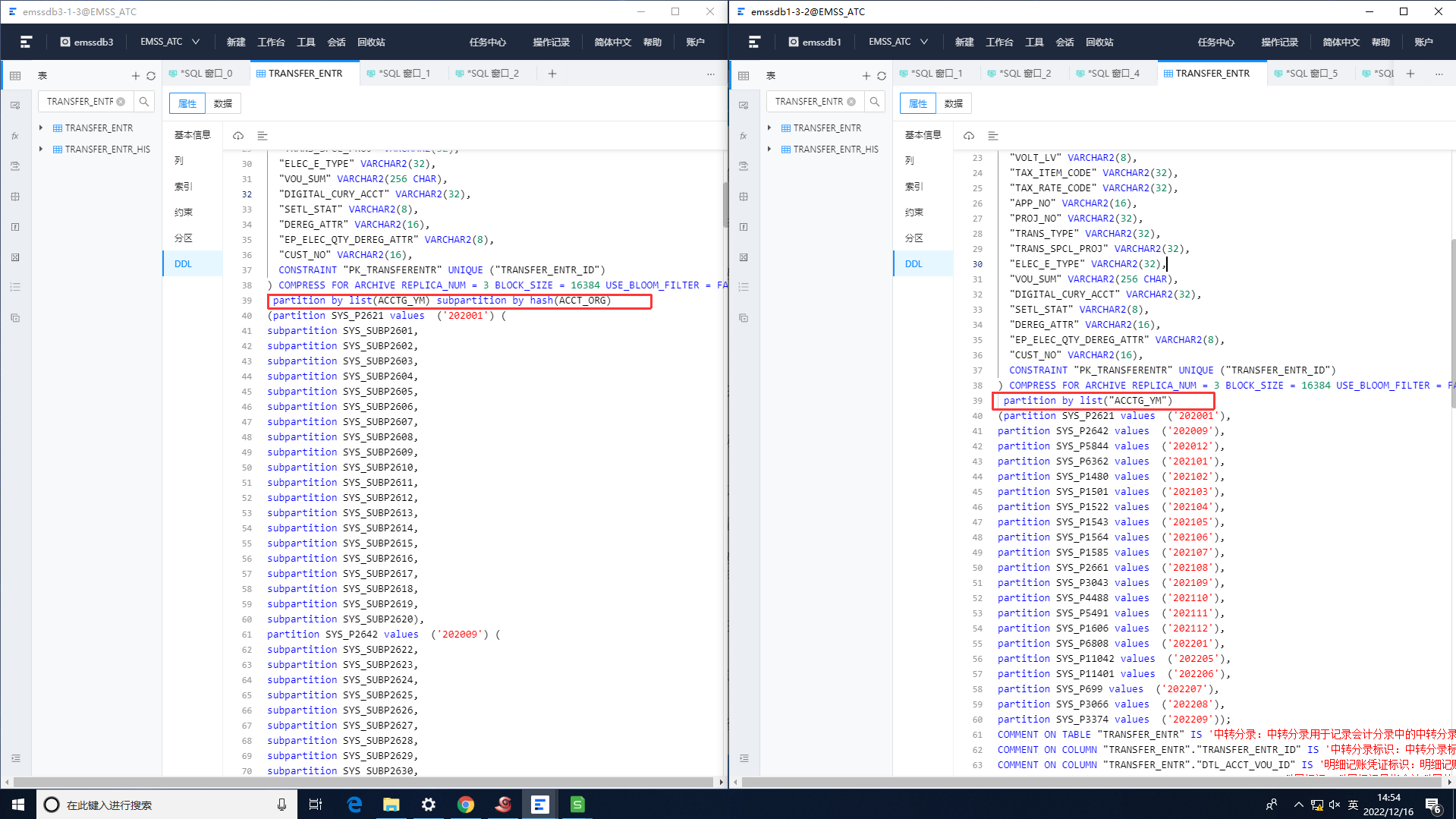
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
从你提供的截图来看,你在 Dataphin 中跳转到 Spark 后遇到了 "Cluster is not ready" 错误。这通常表示 Spark 集群尚未完全启动或遇到了一些问题。
以下是一些可能的原因:
集群仍在启动:Spark 集群可能仍在启动过程中。等待几分钟,然后重试。
资源不足:集群可能没有足够的资源(例如,CPU、内存)来启动所有 Spark 进程。检查集群的资源使用情况,并确保有足够的资源可供 Spark 使用。
配置问题:Spark 集群的配置可能存在问题。检查 spark-defaults.conf 文件中的设置,并确保它们正确。
网络问题:Spark 集群中的节点可能无法相互通信。检查网络连接,并确保防火墙不会阻止 Spark 进程之间的通信。
软件包问题:Spark 集群可能缺少必需的软件包。检查集群中是否安装了所有必需的软件包,例如 Hadoop 和 Scala。
硬件问题:Spark 集群中的节点可能存在硬件问题。检查集群中的节点,并确保它们正常运行。
解决方法:
等待几分钟,然后重试。
检查集群的资源使用情况,并确保有足够的资源可供 Spark 使用。
检查 spark-defaults.conf 文件中的设置,并确保它们正确。
检查网络连接,并确保防火墙不会阻止 Spark 进程之间的通信。
检查集群中是否安装了所有必需的软件包。
检查集群中的节点,并确保它们正常运行。
如果你仍然遇到问题,请提供更多详细信息,例如 Dataphin 和 Spark 集群的版本,以及你遇到的确切错误消息。


