UniASR语音识别-中文-通用-16k-实时 这个模型的结果是normal模式还是fast模式呢?
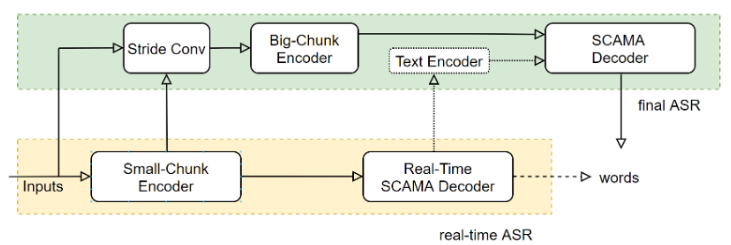
UniASR 模型是一种2遍刷新模型(Two pass)端到端语音识别模型。日益丰富的业务需求,不仅要求识别效果精度高,而且要求能够实时地进行语音识别。一方面,离线语音识别系统具有较高的识别准确率,但其无法实时的返回解码文字结果,并且,在处理长语音时,容易发生解码重复的问题,以及高并发解码超时的问题等;另一方面,流式系统能够低延时的实时进行语音识别,但由于缺少下文信息,流式语音识别系统的准确率不如离线系统,在流式业务场景中,为了更好的折中实时性与准确率,往往采用多个不同时延的模型系统。为了满足差异化业务场景对计算复杂度、实时性和准确率的要求,常用的做法是维护多种语音识别系统,例如,CTC系统、E2E离线系统、SCAMA流式系统等。