
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink任务、Spark任务提交到集群,通常需要将可执行Jar上传到集群,手动执行任务提交指令,如果有配套的大数据平台则需要上传Jar,由调度系统进行任务提交。对开发者来说,本地IDEA调试Flink、Spark任务不涉及对象的序列化及反序列化,任务在本地调试通过后,执行在分布式环境下也可能会出错。而将任务提交到集群进行调试还要走那些繁琐的流程太影响效率了。
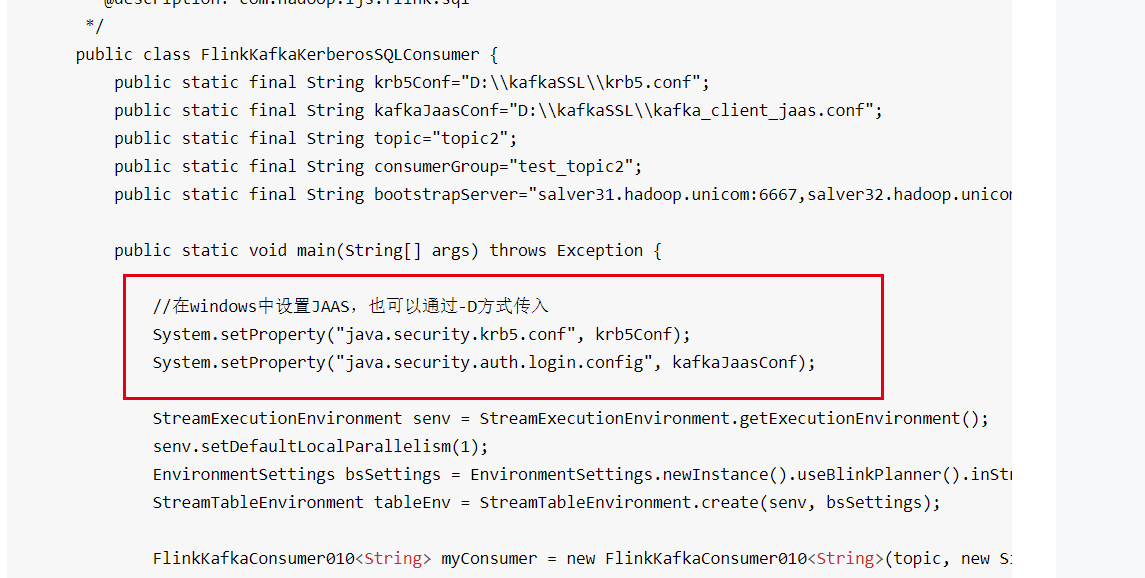
https://nightlies.apache.org/flink/flink-docs-master/zh/docs/deployment/security/security-kerberos/ Kerberos 身份认证设置和配置
需要下面三个文件: 1、KerberosServer的配置文件krb5.conf,让程序知道我应该哪个kdc去登录认证; [libdefaults]udp_preference_limit=1 renew_lifetime=3650dforwardable=truedefault_realm=CHINAUNICOMticket_lifetime=3650ddns_lookup_realm=falsedns_lookup_kdc=falsedefault_ccache_name=/tmp/krb5cc_%{uid} #default_tgs_enctypes = aes des3-cbc-sha1 rc4 des-cbc-md5 #default_tkt_enctypes = aes des3-cbc-sha1 rc4 des-cbc-md5[domain_realm] .CHINAUNICOM = CHINAUNICOM[logging]default=FILE:/var/log/krb5kdc.logadmin_server=FILE:/var/log/kadmind.log kdc = FILE:/var/log/krb5kdc.log[realms]CHINAUNICOM={ admin_server = master98.hadoop.ljskdc=master98.hadoop.ljs }
2、认证肯定需要指定认证方式这里需要一个jaas.conf文件,一般集群的conf目录下都有: KafkaClient{com.sun.security.auth.module.Krb5LoginModulerequireduseKeyTab=truekeyTab="D:\kafkaSSL\kafka.service.keytab"storeKey=trueuseTicketCache=falseprincipal="kafka/salver32.hadoop.unicom@CHINAUNICOM"serviceName=kafka;};
3、就是用户的登录认证票据和认证文件。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



