
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink SQL 中,可以使用 WHERE 子句来对输入数据进行过滤,但是窗口聚合操作通常需要在窗口中进行计算,而不是在 WHERE 子句中进行过滤。因此,通常情况下,窗口聚合操作不会使用 WHERE 子句来进行条件过滤。
例如,下面的示例代码演示了如何在 Flink SQL 中使用滚动窗口对输入数据进行聚合,并计算每个窗口中 amount 字段的总和:
SELECT
TUMBLE_START(rowtime, INTERVAL '1' HOUR) AS w_start,
TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS w_end,
SUM(amount) AS total_amount
FROM input_table
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR)
在上面的代码中,GROUP BY 子句用于指定窗口的分组方式,SUM(amount) 表示对 amount 字段进行求和操作。注意到这里并没有使用 WHERE 子句来进行条件过滤。
当然,如果您需要在窗口聚合操作中使用条件过滤,可以使用 HAVING 子句来实现。HAVING 子句用于对分组后的数据进行过滤,类似于 WHERE 子句。例如,下面的示例代码演示了如何在窗口聚合操作中使用 HAVING 子句来过滤聚合结果:
SELECT
TUMBLE_START(rowtime, INTERVAL '1' HOUR) AS w_start,
TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS w_end,
SUM(amount) AS total_amount
FROM input_table
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR)
HAVING SUM(amount) > 1000
在上面的代码中,HAVING 子句用于过滤窗口聚合的结果,只保留总和大于 1000 的窗口。注意到这里仍然没有使用 WHERE 子句来进行条件过滤。
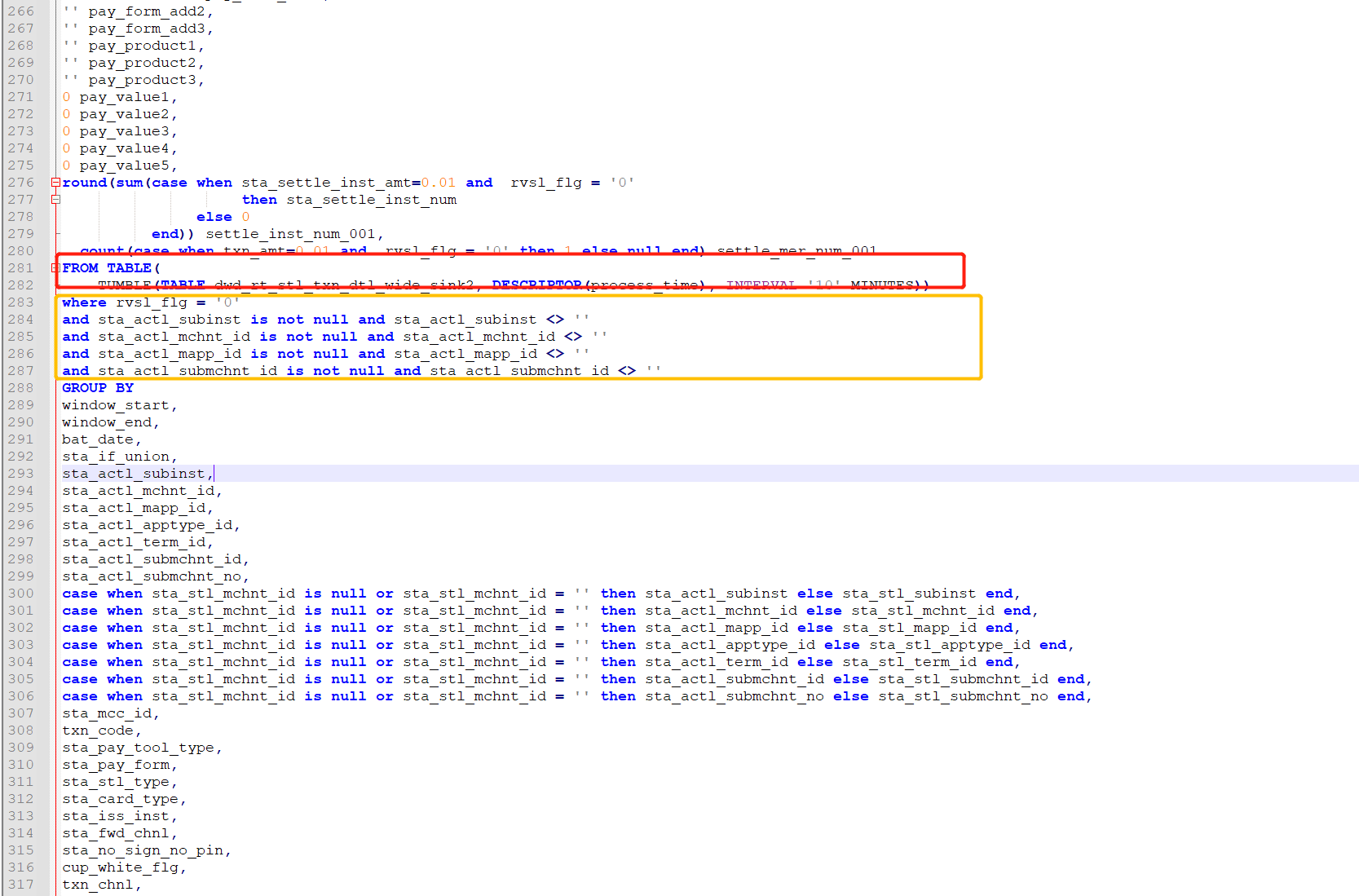
阿里云实时计算 Flink 的 Flink SQL 中的窗口聚合可以使用 WHERE 进行条件过滤。WHERE 语句可以用于在聚合之前对输入流进行条件过滤和筛选。
例如,在以下 SQL 中,使用 TUMBLE 窗口进行聚合,并使用 WHERE 过滤器指定聚合仅在“status”列的值为“SUCCESS”时进行,可以得到“status”列值为“SUCCESS”的条目的计数:
SELECT
TUMBLE_START(ts, INTERVAL '1' HOUR) as wstart,
COUNT(*) as cnt
FROM
myTable
WHERE
status = 'SUCCESS'
GROUP BY
TUMBLE(ts, INTERVAL '1' HOUR)
此外,在Flink SQL中,还可以使用HAVING子句对聚合的结果进行筛选和过滤。
不是。FlinkSQL中的窗口聚合可以使用WHERE进行条件过滤。可以在窗口聚合操作之前使用WHERE子句来过滤输入数据流,以便只有满足特定条件的数据才会被包括在窗口聚合的计算中。例如:
SELECT ... FROM myTable
WHERE condition
GROUP BY ...
WINDOW TUMBLING (SIZE 10 MINUTES)
在上面的示例中,WHERE子句用于过滤来自myTable的输入数据流,然后进行GROUP BY和TUMBLING窗口聚合操作。
不是的,flinksql中的窗口聚合是可以使用where进行条件过滤的。通过where语句可以在窗口聚合前对数据进行筛选,只将符合条件的数据进行聚合。例如:
SELECT COUNT(*) FROM myTable
WHERE price > 100
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR)
上面的SQL语句中,使用WHERE子句将价格大于100的数据筛选出来,并使用TUMBLE窗口将时间按照每小时进行聚合。
是可以支持Where条件过滤的。官网的示例很多,你可以参考下。 另外我看了下其他人的回答,大家基本都是一致的。你在实际使用中,如果发现不起作用,可以检查下where的条件,可以尝试一个极限条件,看看执行前后的数据差异。
在 Flink SQL 中,窗口聚合是支持条件过滤的。可以通过在窗口定义中添加 WHERE 子句来实现。在定义窗口时,WHERE 子句在窗口函数之前使用,因此可以用来限制计算仅应适用于符合给定条件的数据。
举个例子,假设有一个数据流,包含“id”、“name”和“score”三个字段。我们想要按照“id”字段进行分组,并在每个分组中计算“score”字段的平均值,但只想针对“score” > 80 的数据进行计算。可以通过以下 Flink SQL 语句实现:
SELECT id, AVG(score) FROM events WHERE score > 80 GROUP BY id 这里使用 WHERE 子句,对数据进行过滤,只保留“score” > 80 的数据。然后使用 GROUP BY 子句对“id”进行分组,并对每个分组计算“score”字段的平均值。
因此,可以在 Flink SQL 中使用 WHERE 子句对窗口聚合进行条件过滤。
Flink SQL 支持使用 WHERE 关键字对数据进行条件过滤,以便更精细地控制窗口的聚合行为。
在 Flink SQL 中,可以使用类似如下的语句进行窗口聚合和过滤:
SELECT TUMBLE_START(rowtime, INTERVAL '5' MINUTE) as wStart, TUMBLE_END(rowtime, INTERVAL '5' MINUTE) as wEnd, SUM(amount) as totalAmount FROM Orders WHERE amount > 100 GROUP BY TUMBLE(rowtime, INTERVAL '5' MINUTE)
其中,WHERE 子句用于指定数据过滤条件。上述示例中的语句将会计算每 5 分钟的订单销售总额。只有当订单金额大于 100 时才会被包括在计算结果中。具体实现中,Flink SQL 将在所有参与窗口计算的数据集合上执行一次条件过滤,然后再对过滤后的数据集合执行聚合操作。
需要注意的是,在 Flink SQL 中,数据过滤和窗口函数之间的顺序会影响计算结果。一般来说,应该先执行数据过滤操作,再进行窗口聚合操作,以确保计算的正确性。
Flink SQL 中的窗口聚合是可以使用 WHERE 进行条件过滤的,只需要将 WHERE 子句添加到窗口函数的语法中即可。例如,假设有一个数据流包含两个字段,分别为 word 和 count,需要对 word 进行分组并计算过去 5 分钟内每个 word 出现的次数,同时只保留 count 大于等于 10 的结果,可以使用如下的 Flink SQL 语句:
SELECT word, SUM(count) as total_count
FROM table_name
WHERE count >= 10
GROUP BY word, TUMBLE(rowtime, INTERVAL '5' MINUTE)
其中,TUMBLE(rowtime, INTERVAL '5' MINUTE) 表示按照时间窗口进行分组,窗口大小为 5 分钟,rowtime 表示数据流中的时间戳字段。WHERE count >= 10 表示对 count 进行条件过滤,只保留 count 大于等于 10 的数据。
因此,Flink SQL 中的窗口聚合是支持 WHERE 进行条件过滤的,可以根据具体的业务需求进行灵活的使用。
Flink SQL 中的窗口聚合操作可以使用 WHERE 子句进行条件过滤,以筛选要参与聚合的数据。WHERE 子句可以在 GROUP BY 子句之前或之后进行使用,具体使用方式如下所示:
Copy code
SELECT
window_start,
window_end,
COUNT(*)
FROM
my_table
WHERE
my_field > 10
GROUP BY
TUMBLE(rowtime, INTERVAL '1' MINUTE)
上述示例中,WHERE 子句用于筛选 my_table 表中满足条件 my_field > 10 的数据,然后进行窗口聚合操作,统计每个窗口中符合条件的数据数量。
需要注意的是,WHERE 子句中的条件表达式应该是与窗口时间属性相关的,以保证窗口聚合操作的正确性。如果 WHERE 子句中的条件表达式与窗口时间属性无关,可能会导致聚合结果不准确。
在 Flink SQL 中,窗口聚合是可以使用 WHERE 条件进行过滤的。WHERE 子句用于选择与指定条件匹配的行,因此您可以在它之后添加 GROUP BY 和聚合函数来完成窗口聚合操作。
例如,您可以通过以下方式实现基于条件的窗口聚合:
SELECT *
FROM myTable
WHERE columnA = 'valueA'
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR)
HAVING COUNT(columnB) > 10
这里使用 WHERE 子句过滤出符合条件 columnA = 'valueA' 的行,并将它们分组到一个小时的时间窗口中。然后,使用 HAVING 子句过滤出聚合结果中满足 COUNT(columnB) > 10 的分组。
需要注意的是,Flink SQL 的语法和语义可能因版本而异,具体规则请参考相应版本的文档。
不是的,Flink SQL 中的窗口聚合可以使用 WHERE 子句进行条件过滤。WHERE 子句通常用于筛选输入数据流中的特定记录,并将其传递到后续的计算操作,如窗口聚合。
在 Flink SQL 中,你可以使用 WHERE 子句来过滤输入数据流中的记录。例如,以下 SQL 查询将从输入数据流中选择 age 大于 18 的记录,并对它们执行滑动窗口聚合:
SELECT name, COUNT(*) FROM myStream WHERE age > 18 GROUP BY name, TUMBLE(rowtime, INTERVAL '1' HOUR) 在上述查询中,WHERE 子句用于选择符合条件(age > 18)的记录,并将它们传递给 GROUP BY 子句,以便按照姓名和时间窗口进行聚合。因此,你可以在 Flink SQL 中使用 WHERE 子句来过滤输入数据流中的记录,并将它们传递给窗口聚合操作。
在 Flink SQL 中,窗口聚合可以使用 GROUP BY 和 HAVING 子句来进行分组和过滤。
如果需要在分组和聚合之前进行条件过滤,可以在 SQL 语句中使用 WHERE 子句来实现。例如,假设我们有一个名为 sensor_data 的表,其中包含设备的温度传感器数据,我们希望对这些数据进行一分钟的聚合,并且只保留温度大于 30 度的记录,可以这样写 SQL:
SELECT
SENSOR,
MAX(TEMPERATURE),
MIN(TEMPERATURE),
COUNT(*) AS COUNT
FROM
sensor_data
WHERE
TEMPERATURE > 30
GROUP BY
SENSOR,
TUMBLE(PROCTIME(), INTERVAL '1' MINUTE)
HAVING
COUNT(*) >= 2;
在这个 SQL 语句中,WHERE 子句用于过滤温度小于或等于 30 度的记录,然后使用 GROUP BY 将结果按照 SENSOR 以及一分钟的时间窗口进行分组聚合,最后使用 HAVING 子句过滤出出现次数大于等于 2 次的记录。
窗口聚合是支持 WHERE 进行条件过滤的。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



