
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果在阿里云Flink SQL客户端执行SQL时出现“字段过多”的报错,可能是由于SQL中选择的字段过多,导致内存溢出或其他资源问题。为了解决这个问题,可以考虑以下几点:
减少选择的字段数量:通过优化SQL语句,减少选择的字段数量,以降低内存和资源的消耗。可以根据业务需求和数据特征,选择最关键、最有价值的字段进行计算和分析。
增加集群资源:如果减少选择的字段数量无法解决问题,可以考虑增加阿里云Flink集群的资源,如内存、CPU等,以提高集群的计算能力和容错能力。
调整SQL执行参数:可以通过调整阿里云Flink SQL客户端的执行参数,如max-parallelism、max-idle-state-retention-time等,以优化SQL的执行效率和资源利用率。具体参数的调整需要根据具体情况进行调试和优化。
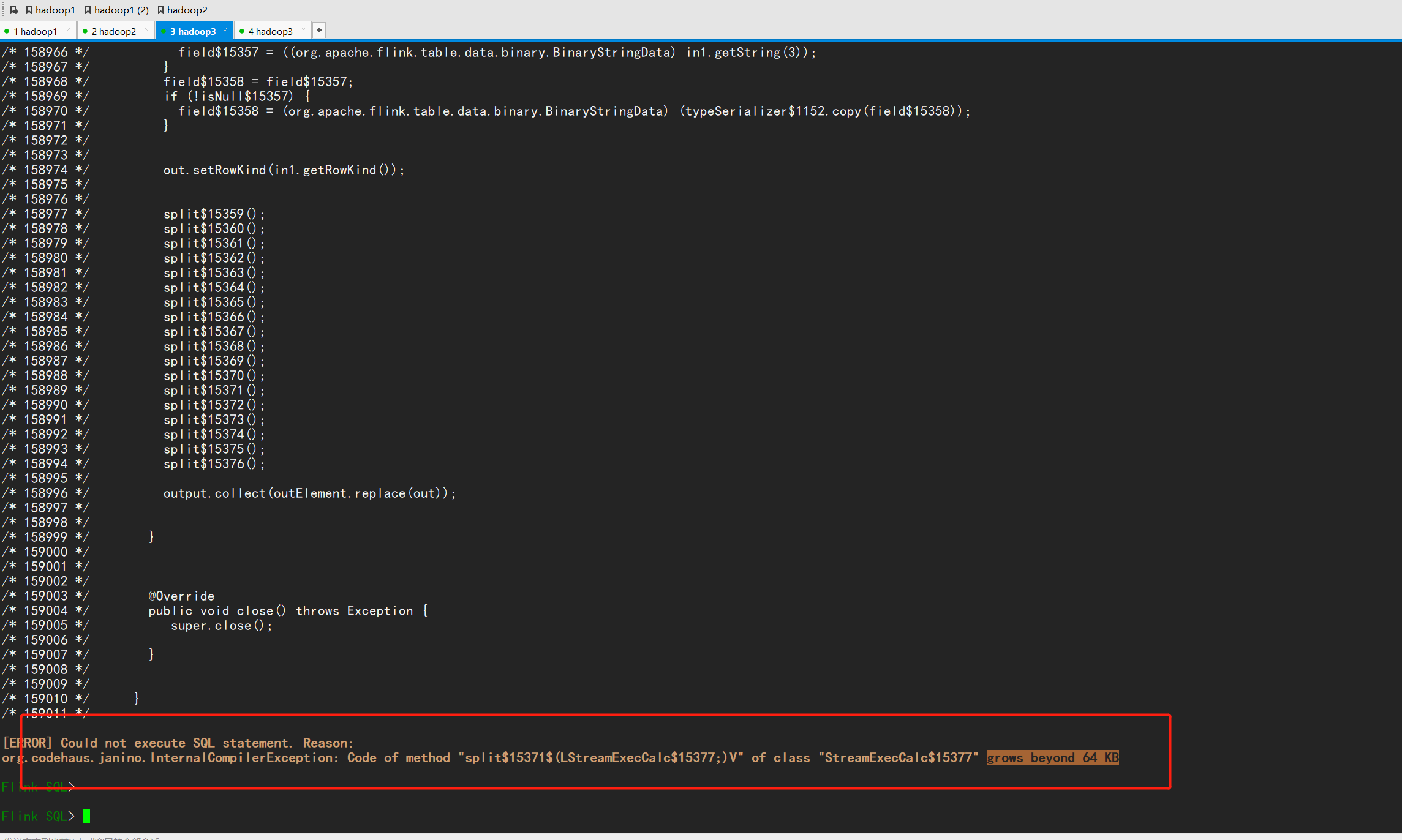
这个错误提示是因为您的 Flink SQL 查询语句过于复杂,导致 StreamExecCalc 类的 split 方法代码超出了 Java 虚拟机(JVM)对单个方法的最大限制(即 64 KB),从而无法继续执行查询。解决这个问题的方法是:
最简单的方法是简化查询语句,减少查询中所包含的字段数量或表达式的复杂度。可以尝试将查询拆分为子查询,然后将结果合并。例如,在以下示例中,查询分为两个子查询,一个查询 my_table 表的前三个字段,另一个查询该表的后两个字段,然后将两个子查询的结果通过 JOIN 组合起来:
SELECT a.id, a.name, a.age, b.gender, b.city
FROM (
SELECT id, name, age FROM my_table
) a
JOIN (
SELECT id, gender, city FROM my_table
) b
ON a.id = b.id;
注意,这种方法需要使用适当的 JOIN 条件来组合两个查询中的结果集,保证查询结果的正确性。
如果查询中的字段数量或表达式的复杂度无法简化,可以尝试增加 JVM 参数来扩大单个方法的最大限制。在 Flink 中,可以通过在启动参数中添加 -XX:MaxInlineSize=<value> 参数来设置方法的最大内嵌深度。例如,可以使用以下命令行启动 Flink SQL 客户端,并将 MaxInlineSize 参数的值设置为 1000:
./sql-client.sh embedded -v -e "SELECT * FROM my_table" -d /path/to/catalog -Dflink.optimizer.max-iteration=1000 -Dflink.optimizer.max-iterations=1000 -Djvm.args="-XX:MaxInlineSize=1000"
需要注意的是,增加 JVM 参数也可能会导致内存占用增加,从而影响 Flink 的性能。因此,建议使用这种方式时要谨慎设置参数值,确保在性能和复杂度之间取得平衡。
另一个解决该问题的方法是使用 Flink Table API 替换 Flink SQL。通过编写 Table API 代码,可以使用更加灵活的方式进行查询、过滤和转换操作,从而避免由于查询复杂度过高而导致的代码量过大的问题。当然,这也需要您具备一定的编程经验和技能。如果您对此感兴趣,可以参考 Flink 官方文档中有关 Table API 的章节。
这个错误常常是由于使用 Flink SQL 执行类似于 SELECT * 这样的语句,查询结果包含太多的字段,从而导致内存不足。您可以考虑以下两个方法来解决报错问题:
明确查询所需字段:尽量避免使用 SELECT * 的方式查询,而是使用具体的字段名进行查询,可以减少不必要的内存开销。
调整 Flink 配置:可以增加 Flink 的内存分配,以便在查询时可以处理更多的字段。具体来说,可以调整 taskmanager.heap.size 和 table.exec.resource.default-parallelism 这两个参数。但需要注意,这种方法并不是最优解决方案,仅仅是一种权宜之计。
根据Flink 官方描述Specifies a threshold where generated code will be split into sub-function calls. Java has a maximum method length of 64 KB. This setting allows for finer granularity if necessary.来看是超过了Java的最大方法长度为64 KB,对应参数table.generated-code.max-length,在问题描述中https://issues.apache.org/jira/browse/FLINK-23007已经有了相应的处理方案,建议减小sql大小,升级Flink到1.14版本以上。
当您使用 Flink SQL 客户端执行较大的 SQL 语句时可能会这样的报错。这个问题通常是由于编译器生成的函数代码超过了 JVM 的限制导致的。要解决此问题,可以使用以下两种方法之一:
1、将较大的 SQL 语句分解为更小的重叠子集。 这种方法的思想是将大 SQL 语句拆分为多个小语句,并在这些语句之间增加一些重叠,以确保数据正确性。例如:
-- 原始 SQL 语句
INSERT INTO my_table SELECT * FROM source_table WHERE value > 100 AND value < 200;
-- 拆分为两个子句
INSERT INTO my_table SELECT * FROM source_table WHERE value > 100;
INSERT INTO my_table SELECT * FROM source_table WHERE value >= 200;
拆分后的 SQL 语句会执行多个单独的查询,但是每个查询的执行时间可能会更短。您可以尝试根据数据的特点和查询的复杂性来选择适当的拆分方式。
2、使用批量作业模式
如果第一种方法不适用于您的情况,可以考虑使用批量作业模式,这是一种将 SQL 语句作为批处理程序执行的方法。Flink 提供了 TableEnvironment.execute() 方法,可用于在批量模式下执行查询。例如:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment btEnv = BatchTableEnvironment.create(env);
Table sourceTable = btEnv.from("my_table");
Table result = sourceTable.select("...");
btEnv.executeSql("CREATE TABLE output_table ( ... ) WITH (...)");
result.insertInto("output_table");
btEnv.execute("My Batch Job");
在此示例中,我们使用 Flink 的 BatchTableEnvironment 创建批量环境,并使用 execute() 方法执行查询。在执行查询之前,我们将 my_table 的数据加载到表中,然后选择要查询的数据。接下来,我们将结果插入到名为 output_table 的新表中,并在执行程序时设置作业名称。
请注意,在使用此方法时,您需要将 SQL 语句和作业设置转换为批量作业的程序,因此这可能需要更多的开发工作,并且可能与更改当前架构之类的操作不太兼容。
这个错误是由于Flink默认限制查询结果集的列数不能超过1000,可以通过修改Flink配置文件来解决。
在Flink的conf目录下,找到flink-conf.yaml文件,添加以下配置:
table.exec.max-column-count: 2000 这里配置的是最大列数为2000,你可以根据实际情况来设置。修改完配置文件后,重启Flink即可生效。
出现 "too many fields" 的报错可能是由于 SQL 查询涉及的字段数过多导致的。在 Flink 中,默认情况下,查询支持的最大字段数是 32767,如果查询中的字段数超过此限制,就会出现该报错。
为了解决这个问题,可以尝试以下几种方法:
减少查询中涉及的字段数。可以检查查询语句中是否存在一些不必要或重复的字段。如果查询中的所有字段都是必需的,可以尝试拆分查询,将字段数分散到不同的子查询中。
增加可用内存。可以通过增加 Flink 集群的内存限制来提高查询的可用性。可以考虑增加 TaskManager 的数量或增加 TaskManager 的内存容量。
提高字段类型精度。在某些情况下,可能会因为数据类型的选择不当导致一个字段被拆分成多个字段,从而导致查询中涉及的字段数过多。因此,可以尝试调整数据类型的精度,例如将 BIGINT 类型改为 INT 类型等。
需要注意的是,以上方法可能需要根据具体情况进行调整和组合使用。如果仍然无法解决问题,可以通过增加并行度、优化查询计划等方式进一步提高查询的性能和稳定性。
楼主你好,根据你的报错提示,原因是查询结果集的列数超过了限制数量,你可以通过配置flink对应的配置文件参数进行修改限制,具体参数为:
table.exec.result-flags.max-columns
这个错误通常是由于您的 SQL 语句中包含的字段过多,导致生成的代码超出了 64KB 的限制。一种解决方法是减少 SQL 语句中的字段数量,或者将其拆分成多个更小的 SQL 查询。另一种解决方法是通过调整 Flink 的配置来增加代码生成器的缓冲区大小。
具体来说,您可以尝试使用以下配置参数来增加代码生成器的缓冲区大小:
table.exec.codegen.bufferSize: 16384
这将会增加代码生成器的缓冲区大小为 16KB,从而允许生成更大的代码。如果这个值仍然不够大,您可以再次增加它,直到能够容纳您的 SQL 语句中的所有字段。
注意,增加缓冲区大小会增加内存的使用量,因此您需要根据实际情况来调整它的大小。此外,如果您的 SQL 语句中包含的字段数量非常大,那么拆分成多个更小的查询可能是更好的解决方法。
这个错误提示的是查询结果集的列数超过了限制,具体限制可以在 Flink 的配置文件中通过参数 table.exec.result-flags.max-columns 进行设置,例如设置为 5000,即可允许查询结果集最多有 5000 列。你可以尝试将这个参数调大一些,看看是否能解决你的问题。注意,修改完配置文件之后需要重启 Flink。
如果您在 Flink SQL 客户端执行 SQL 时遇到了“字段过多”的报错,这通常意味着您的表格中包含了大量的字段,导致 Flink SQL 引擎无法处理。为了解决这个问题,您可以考虑以下几种方法:
减少表格中的字段数量 如果您的表格中存在许多不必要的字段,可以尝试删除其中一些字段来减少字段数量,并重新设计数据模型以更好地满足业务需求。
使用分区表格 如果您的表格中的字段非常多,并且这些字段之间存在某种逻辑关系,可以将表格拆分成多个分区表格,每个分区表格只包含部分字段,并且还具有相应的分区键。这样可以大大降低每个表格的字段数量,并使查询和分析更加高效。
使用宽表和窄表 如果您的表格中需要同时包含大量的字段,例如记录了大量的传感器数据等,可以考虑使用宽表(wide table)和窄表(narrow table)两种数据模型来优化表格结构。宽表是指将所有的字段都存储在同一个表格中,而窄表则是将不同的字段拆分成多个表格,每个表格只包含部分相关的字段。对于大型的、复杂的数据集,通常建议使用窄表来构建数据模型,以便更好地保持数据的清晰性和可维护性。
使用 Flink 中的 Projection 如果您只需要查询表格中的一部分字段,可以使用 Flink 中的 Projection 特性来选择需要的字段。通过 Projection,可以将宽表转换为窄表,并且减少查询和计算操作的成本。例如,以下代码演示了如何使用 Projection 将表格中的 name 和 age 两个字段筛选出来:
SELECT name, age FROM MyTable; 需要注意的是,在实际应用中,还需要根据具体情况进行调整和优化。同时,Flink SQL 引擎也会不断升级和改进,以提高性能和可靠性。
这个错误提示是由于 Flink 默认的内存限制太低导致的,可以通过调整 Flink 系统参数来解决。 需要调节 Flink 集群中的 taskmanager.memory.task.heap.size 参数和 SQL Client 中使用的内存大小。
你可以在 Flink 配置文件中的 flink-conf.yaml 文件中修改 taskmanager.memory.task.heap.size 参数的值,以增加 TaskManager 的 Java 堆内存大小。例如:
taskmanager.memory.task.heap.size: 4g
在 SQL Client 中,可以通过 --buffer-memory 和 --max-table-memory 参数来设置内存大小。其中,--buffer-memory 设置了输出缓冲区的大小,--max-table-memory 设置了内存中允许存放的 Table 数量。例如:
./bin/sql-client.sh embedded -m localhost:8081 --buffer-memory 32mb --max-table-memory 512mb
需要根据实际情况进行调整,建议逐渐增加内存大小,直到不再出现错误为止。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



