
SourceReaderBase是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
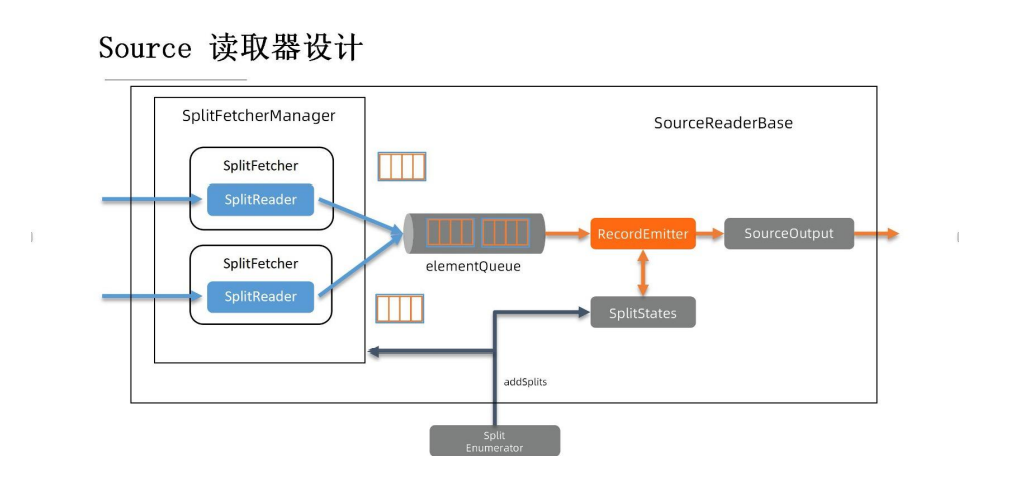
如图示,以中间 elementQueue 队列作为界限,队列左侧用蓝色标出来的部分是需要和外部系统打交道的组件,在 elementQueue 的右侧用橙色标出来的部分是和 Flink的引擎侧打交道的部分。
首先,左侧是由一个或者是多个分片的读取器构成的,每一个 reader 通过一个Fetcher 来驱动,多个 Fetcher 会统一由一个 Fetcher Manager 来管理。这里的实现也有非常多种,比如说可以只开一个线程、只开这一个 SplitReader,通过这一个读取器来消费多个分区。此外,我们也可以根据需求,开多个线程-一个线程运行一个feature,进行一个 reader,每个 reader 负责一个分区来并行的去消费数据。这些完全取决于用户的实现、选择。出于性能考虑,每次SplitReader 会从外部系统中取一批数据,把它们放到elementQueue 里。如图所示,在这个蓝色框子里的是每次取下来的一批数据,而后橙色框是这一批数据下面的每条数据。
其次,elementQueue 的右侧是由 RecordEmitter 和 SourceOutput 组成的。RecordEmitter 把每条记录发送给下游的另外一个 SourceOutput 会把记录输出出去。每次 RecordEmitter 会从中间 elementQueue 里拿一批数据下来,把它们一条一条发送到下游。由于 RecordEmitter 是由主线程来驱动的,该主线程现在的设计里是用了一个无锁的 mailbox 模型,它会把需要执行工作分成一个一个 mail,每次工作线程从 mailbox 里取出来一个 mail 然后来进行工作,所以我们应该注意,这里的实现一定要是无阻塞的。
RecordEmitter 每次往下游发送数据的同时会向下游汇报-后面会不会还有后续的数据需要处理。与此同时呢,我们也会把当前这个分片的处理进度记录在 SplitSta当中,记录它当前的状态、处理到了什么位置。
当 SplitEnumerator 在外部系统当中发现了新的分片,它需要通过 RPC 调用addSplits 方法将新的分片添加读取器。在 SplitFetchermanager 这一侧会根据之前用户已经选定的线程模型把新分片分配出去(如只有一个线程,那便会给这个线程分配一个新任务,再让 reader 去读取这个新的分片。如果整体是多线程的实现的,那便新建一个线程,新建一个 reader 来单独去处理分片。同样我们也要在 SplitStates中记录当前处理的这个进度是怎么样的。
资料来源:《Apache Flink 必知必会》,下载链接:https://developer.aliyun.com/topic/download?id=1189
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


