
什么是特征工程?(1)
目录
主成分分析
- PCA 利用主成分分析方法,实现降维和降维的功能. PCA算法原理见wiki
- 目前支持稠密数据格式
PAI 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- PAI -name PrinCompAnalysis
- -project algo_public
- -DinputTableName=bank_data
- -DeigOutputTableName=pai_temp_2032_17900_2
- -DprincompOutputTableName=pai_temp_2032_17900_1
- -DselectedColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed
- -DtransType=Simple
- -DcalcuType=CORR
- -DcontriRate=0.9;
算法参数说明
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
| inputTableName | 必选,进行主成分分析的输入表 | - | - |
| eigOutputTableName | 必选,特征向量与特征值的输出表 | - | - |
| princompOutputTableName | 必选,进行主成分降维降噪后的结果输出表 | - | - |
| selectedColNames | 必选,参与主成分分析运算的特征列 | - | - |
| transType | 可选,原表转换为主成分表的方式,支持Simple, Sub-Mean, Normalization | - | Simple |
| calcuType | 可选,对原表进行特征分解的方式,支持 CORR/COVAR_SAMP/COVAR_POP | - | CORR |
| contriRate | 可选,降维后数据信息保留的百分比 | - | 0.9 |
| remainColumns | 可选,降维表保留原表的字段 | - | - |
PCA输出示例
降维后的数据表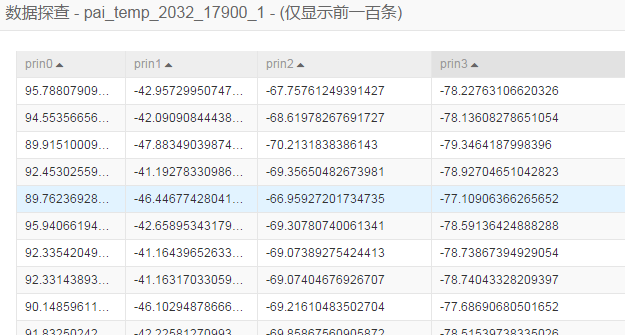
特征值和特征向量表
特征尺度变换
功能说明
- 支持常见的 尺度变化函数 log2,log10,ln,abs,sqrt。支持 稠密或稀疏
PAI 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- PAI -name fe_scale_runner -project algo_public
- -Dlifecycle=28
- -DscaleMethod=log2
- -DscaleCols=nr_employed
- -DinputTable=pai_dense_10_1
- -DoutputTable=pai_temp_2262_20380_1;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,尺度缩放后结果表 | - | - |
| scaleCols | 必选,勾选需要缩放的特征,稀疏特征自动化筛选,只能勾选数值类特征 | - | |
| labelCol | 可选, 标签字段,如果设该签列,可视化特征到目标变量的x-y分布直方图 | - | - |
| categoryCols | 可选,将勾选的字段视作枚举特征处理,不支持缩放 | “” | |
| scaleMethod | 可选,缩放方法,默认log2, 支持 log2,log10,ln,abs,sqrt | SameDistance | |
| scaleTopN | 当scaleCols没有勾选时,自动挑选的TopN个需要缩放特征特征,默认10 | 10 | |
| isSparse | 是否是k:v的稀疏特征,可选,默认稠密数据 | 100 | |
| itemSpliter | 稀疏特征item分隔符,可选,默认逗号 | “,” | |
| kvSpliter | 稀疏特征item分隔符,可选,默认冒号 | “:” | |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
实例
输入数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- create table if not exists pai_dense_10_1 as
- select
- nr_employed
- from bank_data limit 10;
参数配置
勾选nr_employed 做特征尺度变化的特征,只支持数值类特征尺度变化函数,勾选log2
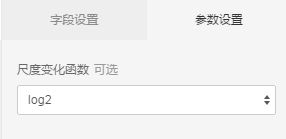
运行结果
| nr_employed |
| 12.352071021075528 |
| 12.34313018339218 |
| 12.285286613666395 |
| 12.316026916036957 |
| 12.309533196497519 |
| 12.352071021075528 |
| 12.316026916036957 |
| 12.316026916036957 |
| 12.309533196497519 |
| 12.316026916036957 |
特征离散
离散模块功能介绍
- 支持 稠密或稀疏的 数值类特征 离散
- 支持 等频离散 和 等距离离散(默认)
pai 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- PAI -name fe_discrete_runner -project algo_public
- -DdiscreteMethod=SameFrequecy
- -Dlifecycle=28
- -DmaxBins=5
- -DinputTable=pai_dense_10_1
- -DdiscreteCols=nr_employed
- -DoutputTable=pai_temp_2262_20382_1;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,离散后结果表 | - | - |
| discreteCols | 必选,勾选需要离散的特征,如果是稀疏特征自动化筛选 | “” | |
| labelCol | 可选, 标签字段,如果设该签列,可视化特征到目标变量的x-y分布直方图 | - | - |
| categoryCols | 可选,将勾选的字段视作枚举特征处理,不支持离散 | “” | |
| discreteMethod | 可选,离散方法,默认SameDistance 目前支持:SameDistance(等距离散), SameFrequecy(等频离散) | SameDistance | |
| discreteTopN | 当discreteCols没有勾选时,自动挑选的TopN个需要离散特征特征,默认10 | 10 | |
| maxBins | 离散区间大小,默认100 | 100 | |
| isSparse | 是否是k:v的稀疏特征,可选,默认稠密数据 | 100 | |
| itemSpliter | 稀疏特征item分隔符,可选,默认逗号 | “,” | |
| kvSpliter | 稀疏特征item分隔符,可选,默认冒号 | “:” | |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
建模示例
输入数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- create table if not exists pai_dense_10_1 as
- select
- nr_employed
- from bank_data limit 10;
参数配置
输入数据为pai_dense_10_1离散特征勾选 nr_employed,用 等距离离散 方法离散成5个区间, 结果如下

运行结果
| nr_employed |
| 4.0 |
| 3.0 |
| 1.0 |
| 3.0 |
| 2.0 |
| 4.0 |
| 3.0 |
| 3.0 |
| 2.0 |
| 3.0 |
特征异常平滑
组件功能介绍
- 功能:将输入特征中含有异常的数据平滑到一定区间,支持稀疏和稠密
ps: 特征平滑组件只是将异常取值的特征值修正成正常值,本身不过滤或删除任何记录,输入数据维度和条数都不变.
平滑方法介绍
- Zscore平滑:如果特征分布遵循正态分布,考虑噪音一般集在-3xalpha 和 3xalpha 之外,ZScore是将该范围数据平滑到[-3xalpha,3xalpha]。
eg: 某个特征遵循特征分布,均值为0,标准差为3,因此-10的特征值会被识别为异常而修正为-3x3+0=-9,同理,10会被修正为3x3+0
- 百分位平滑: 将数据分布在[minPer, maxPer]分位之外的数据平滑平滑到minPer/maxPer这两个分位点
eg: age特征取值0-200,设置minPer为0,maxPer为50%,那么在0-100之外的特征取值都会被修正成0或者100
- 阈值平滑: 将数据分布在[minThresh, maxThresh]之外的数据平滑到minThresh和maxThresh这两个数据点.
eg: age特征取值0-200,设置minThresh=10,maxThresh=80,那么在0-80之外的特征取值都会被修正成0或者80
三 pai 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- PAI -name fe_soften_runner -project algo_public
- -DminThresh=5000 -Dlifecycle=28
- -DsoftenMethod=min-max-thresh
- -DsoftenCols=nr_employed
- -DmaxThresh=6000
- -DinputTable=pai_dense_10_1
- -DoutputTable=pai_temp_2262_20381_1;
四 算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,平滑后结果表 | - | - |
| labelCol | 可选, 标签字段,如果设该签列,可视化特征到目标变量的x-y分布直方图 | - | - |
| categoryCols | 可选,将勾选的字段视作枚举特征处理 | “” | |
| softenCols | 必选,勾选需要平滑的特征,但特征是稀疏特征时自动化筛选 | - | |
| softenMethod | 可选,平滑方法,默认zscore 目前支持:min-max-thresh(阈值平滑), min-max-per(百分位平滑) | zscore | |
| softenTopN | 当softenCols没有勾选时,自动挑选的TopN个需要的平滑特征特征,默认10 | 10 | |
| cl | 置信水平,当平滑方法是zscore方生效 | 10 | |
| minPer | 最低百分位,当平滑方法是min-max-thresh方生效 | 0.0 | |
| maxPer | 最高百分位,当平滑方法是min-max-thresh方生效 | 1.0 | |
| minThresh | 阈值最小值,默认-9999,表示不设置, 当平滑方法是min-max-per方生效 | -9999 | |
| maxThresh | 阈值最大值,默认-9999,表示不设置,当平滑方法是min-max-per方生效 | -9999 | |
| isSparse | 是否是k:v的稀疏特征,可选,默认稠密数据 | 100 | |
| itemSpliter | 稀疏特征item分隔符,可选,默认逗号 | “,” | |
| kvSpliter | 稀疏特征item分隔符,可选,默认冒号 | “:” | |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
五 实例
1. 输入数据
输入数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- create table if not exists pai_dense_10_1 as
- select
- nr_employed
- from bank_data limit 10;
| nr_employed |
| 5228.1 |
| 5195.8 |
| 4991.6 |
| 5099.1 |
| 5076.2 |
| 5228.1 |
| 5099.1 |
| 5099.1 |
| 5076.2 |
| 5099.1 |
参数配置
平滑特征列勾选nr_employed,参数配置中选择阈值平滑,下限5000,上限6000

运行结果
| nr_employed |
| 5228.1 |
| 5195.8 |
| 5000.0 |
| 5099.1 |
| 5076.2 |
| 5228.1 |
| 5099.1 |
| 5099.1 |
| 5076.2 |
| 5099.1 |
随机森林特征重要性
组件功能
使用原始数据和随机森林模型,计算特征重要性.
PAI 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- pai -name feature_importance -project algo_public
- -DinputTableName=pai_dense_10_10
- -DmodelName=xlab_m_random_forests_1_20318_v0
- -DoutputTableName=erkang_test_dev.pai_temp_2252_20319_1
- -DlabelColName=y
- - DfeatureColNames="pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign,poutcome"
- -Dlifecycle=28 ;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
| inputTableName | 必选,输入表 | - | - |
| outputTableName | 必选,输出表 | - | - |
| labelColName | 必选,label所在的列 | - | - |
| modelName | 必选,输入的模型名 | - | - |
| featureColNames | 可选,输入表选择的特征 | - | 默认除label外的其他列 |
| inputTablePartitions | 可选,输入表选择的分区 | - | 默认选择全表 |
| lifecycle | 可选,输出表的生命周期 | - | 默认不设置 |
| coreNum | 可选,核心数 | - | 默认自动计算 |
| memSizePerCore | 可选,内存数 | - | 默认自动计算 |
实例
训练数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- drop table if exists pai_dense_10_10;
- creat table if not exists pai_dense_10_10 as
- select
- age,campaign,pdays, previous, poutcome, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y
- from bank_data limit 10;
参数配置
实例流程图如下,数据源为pai_dense_10_10, y列为随机森林的标签列,其他列为特征列,强制转换列勾选age和campaign,表示这两个特征当做枚举特征处理,其他采用默认参数。 运行成功如下
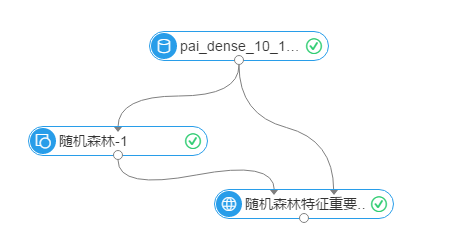
运行结果
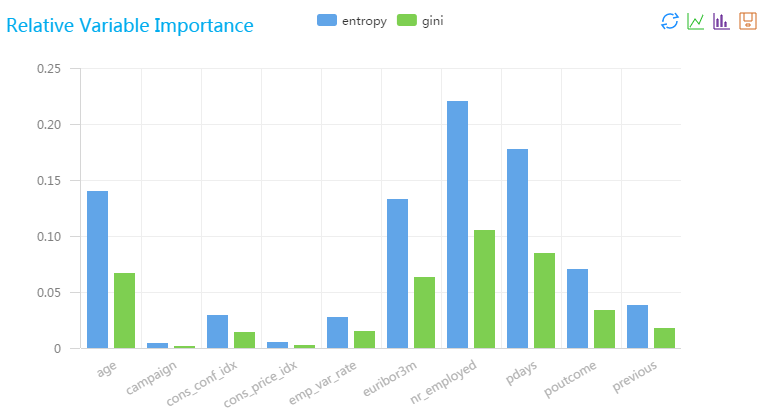
| colname | gini | entropy |
| age | 0.06625000000000003 | 0.13978726292803723 |
| campaign | 0.0017500000000000003 | 0.004348515545596772 |
| cons_conf_idx | 0.013999999999999999 | 0.02908409497018851 |
| cons_price_idx | 0.002 | 0.0049804499913461255 |
| emp_var_rate | 0.014700000000000003 | 0.026786360680260933 |
| euribor3m | 0.06300000000000003 | 0.1321936348846039 |
| nr_employed | 0.10499999999999998 | 0.2203227248076733 |
| pdays | 0.0845 | 0.17750329234397513 |
| poutcome | 0.03360000000000001 | 0.07050327193845542 |
| previous | 0.017700000000000004 | 0.03810381005801592 |
随机森林特征重要性组件上 右键查看可视化分析,效果如下所示
GBDT特征重要性
组件功能
计算梯度渐进决策树(GBDT)特征重要性
PAI 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- pai -name gbdt_importance -project algo_public
- -DmodelName=xlab_m_GBDT_LR_1_20307_v0
- -Dlifecycle=28 -DoutputTableName=pai_temp_2252_20308_1 -DlabelColName=y
- -DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign
- -DinputTableName=pai_dense_10_9;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
| inputTableName | 必选,输入表 | - | - |
| outputTableName | 必选,输出表 | - | - |
| labelColName | 必选,label所在的列 | - | - |
| modelName | 必选,输入的模型名 | - | - |
| featureColNames | 可选,输入表选择的特征 | - | 默认除label外的其他列 |
| inputTablePartitions | 可选,输入表选择的分区 | - | 默认选择全表 |
| lifecycle | 可选,输出表的生命周期 | - | 默认不设置 |
| coreNum | 可选,核心数 | - | 默认自动计算 |
| memSizePerCore | 可选,内存数 | - | 默认自动计算 |
实例
输入数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- drop table if exists pai_dense_10_9;
- create table if not exists pai_dense_10_9 as
- select
- age,campaign,pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y
- from bank_data limit 10;
参数配置
实例流程图如下,输入数据为pai_dense_10_9, GBDT二分类组件选择标签列y,其他字段作为特征列,组件参数配置中 叶节点最小样本数配置为1,运行
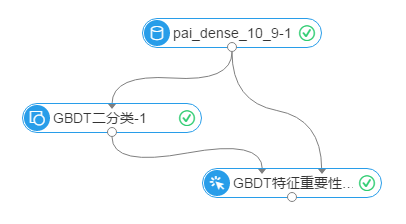
运行结果
| colname | feature_importance |
| age | 0.004667214954427797 |
| campaign | 0.001962038566773853 |
| cons_conf_idx | 0.04857761873887033 |
| cons_price_idx | 0.01925292649801252 |
| emp_var_rate | 0.044881269590771274 |
| euribor3m | 0.025034606434306696 |
| nr_employed | 0.036085457464908766 |
| pdays | 0.639121250405536 |
| previous | 0.18041761734639272 |
右键查看可视化分析报告

线性模型特征重要性
组件功能
计算线性模型的特征重要性,包括线性回归和二分类逻辑回归。 支持稀疏和稠密。
PAI 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- PAI -name regression_feature_importance -project algo_public
- -DmodelName=xlab_m_logisticregressi_20317_v0
- -DoutputTableName=pai_temp_2252_20321_1
- -DlabelColName=y
- -DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign
- -DenableSparse=false -DinputTableName=pai_dense_10_9;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
| inputTableName | 必选,输入表 | - | - |
| outputTableName | 必选,输出表 | - | - |
| modelName | 必选,输入的模型名 | - | - |
| labelColName | 必选,label所在列 | - | - |
| feaureColNames | 可选,输入表选择的特征 | - | 默认除label外的其他列 |
| inputTablePartitions | 可选,输入表选择的分区 | - | 默认选全表 |
| enableSparse | 可选,输入表数据是否为稀疏格式 | true, false | false |
| itemDelimiter | 可选,当输入表数据为稀疏格式时,kv间的分割符 | - | 空格 |
| kvDelimiter | 可选,当输入表数据为稀疏格式时,key和value的分割符 | - | 冒号 |
| lifecycle | 可选,输出表的生命周期 | - | 默认不设置 |
| coreNum | 可选,核心数 | - | 默认自动计算 |
| memSizePerCore | 可选,内存数 | - | 默认自动计算 |
实例
输入数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- create table if not exists pai_dense_10_9 as
- select
- age,campaign,pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y
- from bank_data limit 10;
参数配置
建模流程如下图示, 逻辑回归多分类组件选择标签列为y,其他字段为特征列,其他参数默认,运行
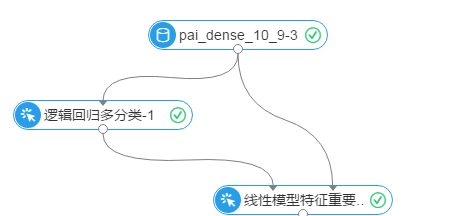
运行效果
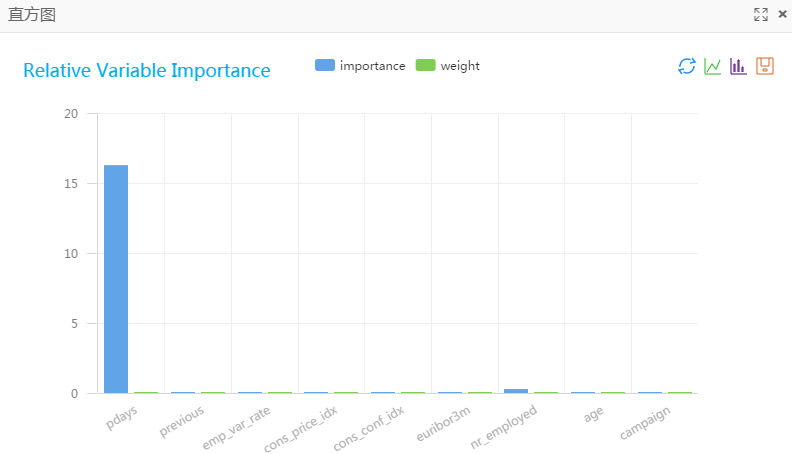
| colname | weight | importance |
| pdays | 0.033942600256583334 | 16.31387797440866 |
| previous | 0.00004248130342485344 | 0.000030038817725357177 |
| emp_var_rate | 0.00006720242617694611 | 0.00010554561260753949 |
| cons_price_idx | 0.00012311047229142307 | 0.00006581255124425219 |
| cons_conf_idx | 0.00017227965471819213 | 0.0008918770542818432 |
| euribor3m | 0.00006113758212679113 | 0.00010427128177450988 |
| nr_employed | 0.0034541377310490697 | 0.26048098230126043 |
| age | 0.00009618162708080744 | 0.0009267659744232966 |
| campaign | 0.000019142551785274455 | 0.000041793353660529855 |
指标计算公式
| 列名 | 公式 | |
| weight | abs(w_) | |
| importance | abs(w_j) * STD(f_i) |
在线性模型特征重要性组件上, 右键查看可视化分析
偏好计算
功能介绍
- 给定用户的明细行为特征数据,自动计算用户对特征值的偏好得分.
- 输入表包含用户id和用户明细行为特征输入,假设在口碑到店场景,某用户2088xxx1在3个月内吃了两次川菜,一次西式快餐,那么输入表形式如下:
| user_id | cate |
| 2088xxx1 | 川菜 |
| 2088xxx1 | 川菜 |
| 2088xxx1 | 西式快餐 |
- 输出表为用户对川菜和西式快餐的偏好得分,形式如下:
| user_id | cate |
| 2088xxx1 | 川菜:0.0544694,西式快餐:0.0272347 |
PAI命令示例
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- pai -name=preference
- -project=algo_public
- -DInputTableName=preference_input_table
- -DIdColumnName=user_id
- -DFeatureColNames=cate
- -DOutputTableName=preference_output_table
- -DmapInstanceNum=2
- -DreduceInstanceNum=1;
算法参数
| 参数key名称 | 参数描述 | 必/选填 | 默认值 |
| InputTableName | 输入表名 | 必填 | - |
| IdColumnName | 用户id列 | 必填 | - |
| FeatureColNames | 用户特征列 | 必填 | - |
| OutputTableName | 输出表名 | 必填 | - |
| OutputTablePartitions | 输出表分区 | 选填 | - |
| mapInstanceNum | mapper数量 | 选填 | 2 |
| reduceInstanceNum | reducer数量 | 选填 | 1 |
实例
测试数据
新建数据SQL<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- drop table if exists preference_input_table;
- create table preference_input_table as
- select
- *
- from
- (
- select '2088xxx1' as user_id, '川菜' as cate from alipaydw.dual
- union all
- select '2088xxx1' as user_id, '川菜' as cate from alipaydw.dual
- union all
- select '2088xxx1' as user_id, '西式快餐' cate from alipaydw.dual
- union all
- select '2088xxx3' as user_id, '川菜' as cate from alipaydw.dual
- union all
- select '2088xxx3' as user_id, '川菜' as cate from alipaydw.dual
- union all
- select '2088xxx3' as user_id, '西式快餐' as cate from alipaydw.dual
- ) tmp;
运行结果<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- +------------+------------+
- | user_id | cate |
- +------------+------------+
- | 2088xxx1 | 川菜:0.0544694,西式快餐:0.0272347 |
- | 2088xxx3 | 川菜:0.0544694,西式快餐:0.0272347 |
- +------------+------------+
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答




