python怎么爬图片
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
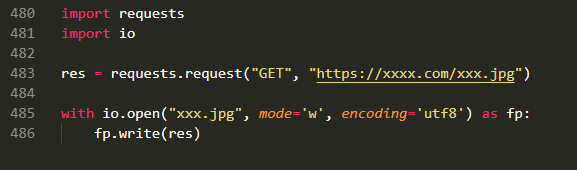
您好,请参考爬取贴吧图片的案列代码:
import urllib.request
import re
def getHtml(url):
page = urllib.request.urlopen(url)
html =page.read().decode("utf-8")
return html
def getImage(page):
reg=r'src="(.+?.jpg)" size'
imgre=re.compile(reg)
print (imgre)
imglist=re.findall(imgre,page)
print (imglist)
x=0
for i in imglist:
urllib.request.urlretrieve(i,'%s.jpg' %x)
x+=1return imglist
html=getHtml("http://tieba.baidu.com/p/4721099001")
print(getImage(html))