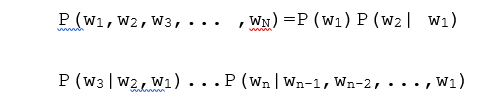我是某211大学信息管理与信息系统专业的学生,目前正在学习机器学习和前后端项目的开发,在大学学习的过程中不可避免地遇到前后端项目服务器部署、机器学习和深度学习跑模型等需要,在同班同学的安利下,我知道了阿里云平台,特别是“飞天加速计划·高校学生在家实践”活动。
我认为资金是大学生群体做研究的困难点之一,而阿里云平台提供地这个计划就很好地解决学生的需求,可以低价甚至免费使用服务器,帮助了我们去做比赛、做项目和做研究。
我最近在学习机器学习的自然语言处理方面,分词是一个比较基础内容,这是我的分享:
分词就是指将连续的自然语言文本切分成具有语义合理性和完整性的词汇序列的过程。like this👇
基于词典的分词算法
基于词典的分词算法,实质上是字符串匹配。将待匹配的字符串使用一定的算法规则,和一个足够大的词典中的词条进行字符串匹配,若在词典中找到某个字符串匹配命中,则可以分词。
根据不同的匹配策略,可以将基于词典的分词算法进行分类。按照字符串匹配时扫描方向的不同,可分为正向匹配法、逆向匹配法与双向匹配法。按照匹配的字符串长度的不同,可分为最大匹配法与最小匹配法。按照匹配时是否与词性标注过程相结合,可分为单纯分词法与分词与标注相结合法。
1️⃣正向最大匹配算法
首先设置分词词典中的最长词有n个字符,然后从左到右切分文本的n个字符作为匹配字段,接着查找词典并进行匹配,若恰好与词典中的某个字符串匹配成功,则将这个匹配字段作为一个词切分出来;若匹配失败,将匹配字段中的最后一个字去掉,对此时剩下的字串重新与分词词典进行匹配,如此下去直到匹配成功切分出所有词为止。2️⃣逆向最大匹配算法
逆向最大匹配算法是正向最大匹配的逆向思维,从右到左对语句进行切分,与词典匹配,匹配不成功,则将匹配字段的最前一个字去掉,直到最后匹配成功切分出所有词为止。
3️⃣双向最大匹配法
双向最大匹配法就是将正向最大匹配法得到的分词结果和逆向最大匹配法的得到的结果进行比较,根据大颗粒度词越多越好,非词典词和单字词越少越好的原则,选取其中一种分词结果输出。
基于统计机器学习的分词算法
基于统计的分词算法的基本原理是按照字符串在语料库中出现的统计频率来决定其是否构成词。词是字的组合, 相邻的字同时出现的次数越多,构成词组得可能性越大。该算法不需要建立词典,但需要大规模的训练文本用来训练模型参数。
1️⃣N元模型(N-gram)N-gram模型思想:第$n$个词的出现依赖于前$n-1$个词,整句的概率就是各个词出现概率的乘积。给定一个由 $n$ 个词组成的序列$\lbrace w_1,w_2,...w_n \rbrace $,根据链式法则可得,

然而,当n取值比较大时,乘法链式后面几项的计算会变得非常困难,这时需要用合理的假设来简化计算,即假设当前这个词仅仅跟前面几个有限的词相关,而不必追溯到最开始的那个词,这样便可以大幅减小计算量。
设$\lbrace w_1,w_2,...w_n \rbrace$是长度为$n$的字符串,若规定任意词$w_i$只依赖于其前一个词,可得到一元模型(unigram model) ,即
若规定任意词$w_i$只依赖于前两个词,可得到二元模型(bigram model) ,即
若规定任意词$w_i$只与它的前两个相关,可得到三元概率模型(trigram) ,即
在实践中bigram和trigram应用比较广泛,而且效果可观。高于四元的模型应用的相对较少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度也高,精度却难以提高。
2️⃣隐马尔科夫模型(Hidden Markov Model,HMM)
隐马尔科夫模型在人工智能领域应用十分广泛,它包含观测序列和隐藏序列两部分。观测序列数据是能观测到的,而隐藏序列数据是不能观察到的。利用HMM模型可实现根据观测值序列查找对应的隐藏状态值序列。
对应到NLP分词中,我们的语句是观测序列,而分词后的序列标注结果是隐藏序列,因此基于HMM进行分词实质上可以看作是一个序列标注问题,即一个考虑上下文的字分类问题,可以先通过大量带序列标注结果的分词语料来训练出一个序列标注模型,然后再用这个模型对无标注的语料进行分词。
首先,我们可根据字在词中的位置给语句中的所有字进行分类。实践中一般采用{B:begin, M:middle, E:end, S:single}这4个类别来描述一个分词样本中每个字所属的类别。其中,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。
如“王小红在教室里认真地写程序”,标注后结果为“BMESBESBESBME”,对应的分词结果为“王小红/在/教室/里/认真/地/写程序/”。接着,将标注好的分词训练集输入HMM模型,便可得到HMM模型的相关参数,然后利用viterbi算法来计算待分词文本最可能的隐藏序列,最终就得到最佳分词结果。
① 输入:小红本科毕业于北京大学
② 通过算法,我们成功预测出各个字位对应的分词标签:BEBEBMEBEBE
③ 根据这个状态序列我们可以进行切词: BE/BE/BME/BE/BMME
④ 切词结果如下: 小红/本科/毕业于/北京大学
3️⃣条件随机场(CRF)
CRF亦是描述输入序列与输出序列之间的关系。与HMM模型不同的是,HMM存在独立性假设,导致其不会考虑前后文特征,局限了特征的可用范围,而CRF基于条件概率来描述模型的,它不对单独的节点进行归一化,而是对所有特征进行全局归一化,获取全局的最优值。
HMM模型围绕的是一个关于序列X和Y的联合概率分布P(X,Y),而CRF则围绕条件概率分布模型(Y|X)展开,用特征函数的方法来将前后文的观测序列连接起来,后期利用优化的viterbi算法来计算待分词文本最可能的隐藏序列,最终就得到最佳分词结果。
基于神经网络的分词算法
传统的中文分词方法是基于有监督的学习算法,需要大量的人工标记语料,同时还会存在所提取的局部特征稀疏的问题。现如今,随着深度学习的发展,各种神经网络已广泛用于解决NLP任务,给NLP带来了诸多新的机遇。
1️⃣双向长短时记忆神经网络(Bilstm)LSTM为循环神经网络(RNN)中的一种,在一定程度上解决了RNN在训练过程中梯度消失和梯度爆炸的问题。LSTM是有方向的,使用LSTM模型可以捕捉到无限距离的前文依赖关系,但无法编码从后到前的信息。而通过BiLSTM却可以有效捕捉到双向的语义依赖,分别从句子的前文和后文对输入进行处理,将上下文信息进行编码,通过softmax分类层完成对每个位置的分类,提升预测效果。
LSTM模型由$t$时刻的输入词$X_t$,细胞状态 $C_t$,临时细胞状态$\widetilde{C_t}$ ,隐层状态$h_t$,遗忘门$f_t$,记忆门$i_t$,输出门$O_t$组成。
LSTM的计算过程可以概括为:通过对细胞状态中信息遗忘和记忆新的信息使得对后续时刻计算有用的信息得以传递,而无用的信息被丢弃,并在每个时间步都会输出隐层状态$h_t$,其中遗忘、记忆与输出由通过上个时刻的隐层状态$h_{t-1}$和当前输入$X_t$计算出来的遗忘门$f_t$、记忆门$i_t$与输出门$O_t$来控制。
Bilstm是由前向LSTM与后向LSTM组合而成,将前向和后向的隐向量进行拼接得到最终的隐层状态$h_t$。
欢迎随时指导~