ReaderPool(二)(Lucene 8.7.0)
本文承接文章ReaderPool(一),继续介绍剩余的内容。
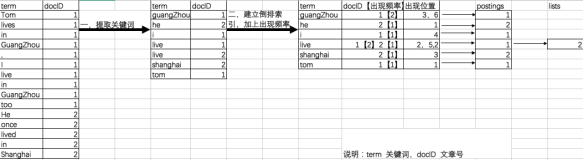
读取ReaderPool对象
我们继续介绍ReaderPool对象中的readerMap这个map容器ReaderAndUpdates中包含的实例变量。
图1:


图2:

boolean isMerging
图3:

正如图3中的注释描述的那样,isMerging这个布尔值相用来描述一个段是否正在参与段的合并操作。如果一个段正在合并中,并且该段中的有些文档满足DocValues的更新条件(更新方式见文章文档的增删改(上)),那么更新信息将被暂存到图3红框标注的mergingNumericUpdates中,它是一个map容器。当合并结束后,暂存在mergingNumericUpdates中的更新信息将作用到合并后的新段。
注意的是从Lucene 4.6.0开始正如图3注释描述的那样,更新信息的确是被暂存在mergingNumericUpdates的map容器中,下图是Lucene 4.6.0中的代码:
图4:

然而在Lucene 8.7.0中,更新信息是暂存在图2中的mergingDVUpdates的map容器的,所以图3中的mergingNumericUpdates属于书写错误。
什么时候isMerging的值为true?
以执行段的合并为例,如下所示:
图5:

图5中,红框标注的两个流程点中根据一个段的SegmentCommitInfo的信息,从ReaderPool中的readerMap(图1所示)中找到ReaderAndUpdates,然后置ReaderAndUpdates中的isMerging的值为true。
Map<DocValuesFieldUpdates>> pendingDVUpdates
图6:

如果某个段没有参与段的合并,更精确的描述应该是这个段对应在ReaderPool中的isMerging的值为false时,在索引(Indexing)的过程(段的合并跟索引可以是并行操作,取决于段的合并调度)中,即执行文档的增删改的操作,当段中的文档满足DocValues的更新操作,那么更新信息会被暂存到pendingDVUpdates中。
为什么是暂存更新信息?
如果不是暂存,那么就是持久化到磁盘,即生成新的索引文件.dvd&&dvm。但是每次有DocValues的更新操作就执行I/O磁盘操作,这显然不是合理的设计。
什么时候将DocValues的更新操作持久化到磁盘?
例如在执行flush、commit、获取NRT reader时。
图7:

图7中,当用户调用了主动flush(执行IndexWriter.flush()操作),当执行到流程点更新ReaderPool,说明这次flush产生的DocValues的更新信息已经实现了apply,那么此时可以将更新信息生成新的索引文件dvd&&dvm。
什么时候一个段会被作用(apply)DocValues的更新信息
还是以图7的flush为例,在IndexWriter处理事件的流程中,会执行一个处理删除信息的事件,其流程图如下所示:
图8:

图10中红框标注的流程点将会为每个满足DocValues的更新操作的段记录更新信息,即将更新信息暂存到pendingDVUpdates中。
另外在执行段的合并过程中,待合并的段在图5的流程点作用(apply)删除信息被作用DocValues的更新信息。
Map<DocValuesFieldUpdates>> mergingDVUpdates
图9:

正如图9的注释描述的那样,当某个段正在进行合并时,即上文中中isMerging的值为true,mergingDVUpdates容器用来暂存在合并期间生成的新的DocValues更新信息,在合并结束后,这些更新信息将被作用新生成的段。
在图5的流程点提交合并中,将会读取mergingDVUpdates中暂存的更新信息,并作用到新生成的段。
boolean poolReaders
图10:

最后我们再介绍下ReaderPool对象中的poolReaders,它是一个布尔值,图10的注释中说到,该值的特点就像是往DVD上刻录,一旦刻录了就无法再次刻录,即该值默认为false,一旦被赋值为true,那么就不会再为true。
哪些场景下poolReaders的值会被置为true
在生成IndexWriter对象时,可以指定为true,见文章构造IndexWriter对象(一)的介绍,或者是在使用NRT机制的时候。
poolReaders设置为true后有什么用
目前唯一使用的场景是在执行段的合并中,如果poolReaders为true,那么在图5的流程点生成IndexReaderWarmer,至于IndexReaderWarmer的作用可以阅读文章执行段的合并(四)。
结语
通过两篇文章的介绍,想必已经深入理解了ReaderPool这个类的作用。理解了这个类,才能真正理解Lucene的段的合并、flush/commit、NRT等机制。