
前置知识
缓存行:缓存是由缓存行组成的,通常是64字节,因此在一个缓存行中可以存8个long类型的变量。CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个缓存行。如在一个long数组的值加载到缓存中,会自动加载其他7个,因此数组能够很快被遍历,处理器对数组的缓存机制更加友好。
伪共享:变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果,从而导致消费者线程的缓存中的缓存行无效,需要从主存中重新读取。这种无法充分使用缓存行特性的现象就是伪共享。
CAS:compare and swap(A,B,C) 如果A地址的值等于B,那么将A地址的值改为C
基本概念
Disruptor是英国外汇交易公司LMAX开发的高性能的并发框架,研发的初衷是解决内存队列的延迟问题,它是线程间通信的高效低延时的内存消息组件,它最大的特点是高性能。与 Kafka、RabbitMQ 用于服务间的消息队列不同,disruptor 一般用于一个 JVM 中多个线程间消息的传递。
来自官方的一个与ArrayBlockingQueue比较:

其他性能表现可以参见:https://github.com/LMAX-Exchange/disruptor/wiki/Performance-Results
自测的性能表现( 线程数:512 单线程生产量: 2048 容量:1024 数据总量:1048576):
2021-05-14T03:48:01.971Z ArrayBlockingQueue 总耗时:5761
2021-05-14T03:48:48.348Z 处理的sequence:1048575 count:1048576 Disruptor 总耗时:1935
基本概念基础组件
组件图如下:

基本概念:
- Event:从生产者到消费者过程中所处理的数据单元,存放在Ringbuffer。Disruptor中没有代码表示Event,因为它完全是由用户定义的。
- EventProcessor:主要事件循环,处理Disruptor中的Event,并且拥有消费者的Sequence。主要有两种实现:单线程批量处理BatchEventProcessor和多线程处理MultiBufferBatchEventProcessor。事件处理将回调到一个EventHandler接口的实现对象。源码分析:com.lmax.disruptor.BatchEventProcessor#processEvents
- EventHandler:由用户实现并且代表了Disruptor中的一个消费者的接口。
基础组件:
- RingBuffer: 负责存储和更新在Disruptor中流通的数据。
- Sequence:表示一个特殊组件处理的序号。大部分的并发代码依赖这些Sequence值的运转,本质上是一个计数器;它是线程安全的,支持CAS操作,通过padding来避免伪共享。
- Sequencer:这是Disruptor真正的核心。实现了这个接口的两种生产者(单生产者和多生产者)均实现了所有的并发算法,为了在生产者和消费者之间进行准确快速的数据传递。
- SequenceBarrier: 用来在消费者之间以及消费者和RingBuffer之间建立依赖关系,例如消费B时要在消费者A后执行的,那么A的序号一定小于B。类似于栅栏效果,消费者B会在SequenceBarrier中等待,直到所有依赖的序号大于等于这个消费者B的序号
- Wait Strategy:等待策略
名称 |
措施 |
适用场景 |
BlockingWaitStrategy |
加锁 |
CPU资源紧缺,吞吐量和延迟并不重要的场景 |
BusySpinWaitStrategy |
自旋 |
通过不断重试,减少切换线程导致的系统调用,而降低延迟。推荐在线程绑定到固定的CPU的场景下使用 |
PhasedBackoffWaitStrategy |
自旋 + yield + 自定义策略 |
CPU资源紧缺,吞吐量和延迟并不重要的场景 |
SleepingWaitStrategy |
自旋 + yield + sleep |
性能和CPU资源之间有很好的折中。延迟不均匀 |
TimeoutBlockingWaitStrategy |
加锁,有超时限制 |
CPU资源紧缺,吞吐量和延迟并不重要的场景 |
YieldingWaitStrategy |
自旋 + yield + 自旋 |
性能和CPU资源之间有很好的折中。延迟比较均匀 |
高效原因
- 消除了伪共享(使用缓存行填充,避免当前处理器缓存上缓存的数据因为和其他处理器的数据在同一个缓存行,用空间换时间),提高cache命中率
- 高效的ringbuffer结构,减少GC开销
消费者和生产者
消费者
BatchEvenProcessor:每个processor都有各自的sequence,消息被同一消费者每个消费者都消费
WorkProcessor:每个WorkProcessor也有一个Sequence,多个WorkProcessor还共享一个Sequence用于互斥的访问RingBuffer,消息只能被其中一个消费者消费。
两种EventProcessor都实现了Runnable接口,在组装完成后可以直接放入线程中执行。
生产者
分为单生产者SingleProducerSequencerPad和多生产者MultiProducerSequencer:
单生产者:
Disruptor<ObjectEvent<T>> disruptor = new Disruptor(new DisruptorEventFactory(),
queueSize, Executors.defaultThreadFactory(), ProducerType.SINGLE,
new YieldingWaitStrategy());
多生产者:
Disruptor<ObjectEvent<T>> disruptor = new Disruptor(new DisruptorEventFactory(),
queueSize, Executors.defaultThreadFactory(), ProducerType.MULTI,
new YieldingWaitStrategy());
public Disruptor(
// 创建环形缓冲中对象的工厂
final EventFactory<T> eventFactory,
// ringBuffer大小
final int ringBufferSize,
// 线程工厂
final ThreadFactory threadFactory,
// 生产者类型,单或多生产者
final ProducerType producerType,
// 等待环形缓冲游标的等待策略
final WaitStrategy waitStrategy)
{
this(
RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),
threadFactory);
}
RingBuffer介绍
Disruptor高性能原因之一就是用到了RingBuffer,它是一个环形数组结构,Ringbuffer拥有一个指针序号Sequence,这个序号指向数组中下一个可用元素i,序号会一直增长,下一次访问这个位置的元素的时候,Seqence等于i + buffer_size,将序号对数组大小取余(实际上是位运算)就可以得到数组索引。这样指针在缓冲区上反复游走,故可以将缓冲区看成环状。
它有几个优点:
- 为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好(访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个)。
- 数组长度2的次方,通过位运算,加快定位的速度。下标采取递增的形式。
- 无锁设计,每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据
示意图:
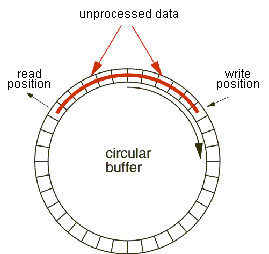
生产和消费情况分析
- 1、当生产者和消费者都只有一个时,由于两个线程分别操作不同的指针,所以不需要锁。生产者申请写入m个元素,如果可以写入,那么就开始写入元素。相关源码:com.lmax.disruptor.RingBuffer#next(),单线程生产者下获取只一个序号:com.lmax.disruptor.SingleProducerSequencer#next(int)*com.lmax.disruptor.SingleProducerSequencer#publish(long)

- 2、当有多个消费者时,每个消费者各自控制自己的指针,依次读取每个序号(也就是每个消费者都会读取到所有的event),这时只需要保证生产者指针不会超过最慢的消费者(超过最后一个消费者“一圈”)即可,也不需要锁。例如:最慢的消费者在 9 的位置,它就可以让生产者写入节点 3,4,5,6,7 和 8,中间不需要再次检查消费者的位置。com.lmax.disruptor.MultiProducerSequencer#next(int)
- 3、当有多个生产者时,此处需要考虑多线程问题,例如两个生产者线程同时写数据,当前写指针=0,运行后其中一个线程应获得缓冲区0号Slot,另一个应该获得1号,写指针=2。对于这种情况,每个线程获取不同的一段数组空间进行操作,Disruptor使用CAS来保证多线程安全判断这段空间是否被分配出去。实际上在多生产者情况下,还没生产数据就已经将游标移动了。同时为了避免消费者读到还未写的元素,还引入了一个与Ring Buffer大小相同的buffer: available Buffer. 当某个位置写入成功的时候, 便把availble Buffer相应的位置置位, 标记为写入成功. 读取的时候, 会遍历available Buffer, 来判断元素是否已经就绪。参考源码:MultiProducerSequencerVarHandle#next(int)
在读数据时会进行下面的处理:
- 申请读取到序号n
- 当下一个写入位置指针>= n,这时仍然无法确定连续可读的最大下标。需要从当前读指针开始读取available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
- 消费者读取元素。

当多个生产者写入的时候:
- 申请写入m个元素;
- 若是有m个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间;
- 生产者写入元素,写入元素的同时设置available Buffer里面相应的位置,以标记自己哪些位置是已经写入成功的。

note
- 为了避免生产者的生产速度过快而造成的新消息覆盖了未被消费的旧消息,在每个消费者加入消费时,都会调用生产者的以下这个方法,增加控制序列的方式,判断是否能够进行生产。voidaddGatingSequences(Sequence... gatingSequences);
- 当消息可以被重复消费的时候,每个消费者相互独立;不能重复消费时,共用一个序号。
在埋点中的使用
创建埋点event
@ToString
@Data
public class ObjectEvent<T> {
/**
* 埋点数据类型
*/
private EventEnum tag;
/**
* 埋点数据内容
*/
private T obj;
}
实例化生产者
public static <T> DisruptorQueue<T> getWorkPoolQueue(int queueSize, boolean isMoreProducer,
AbsDisruptorConsumer... consumers) {
Disruptor<ObjectEvent<T>> disruptor = new Disruptor(new DisruptorEventFactory(),
queueSize, Executors.defaultThreadFactory(),
isMoreProducer ? ProducerType.MULTI : ProducerType.SINGLE,
new YieldingWaitStrategy());
disruptor.handleEventsWithWorkerPool(consumers);
return new DisruptorQueue(disruptor);
}
写入数据
public void add(EventEnum tag, T t) {
if (t != null) {
long sequence = this.ringBuffer.next();
try {
ObjectEvent<T> event = (ObjectEvent) this.ringBuffer.get(sequence);
event.setObj(t);
event.setTag(tag);
} finally {
this.ringBuffer.publish(sequence);
}
}
}
消费
public void consume(ObjectEvent event) {
try {
log.debug("Disruptor消费标志: {} , 内容为: {} ", event.getTag(), event.getObj());
switch (event.getTag()) {
case API_ERROR:
DisruptorHelper.getInstance().consumeApiErrorLog((AppErrorLog) event.getObj());
break;
case API_EVENT:
DisruptorHelper.getInstance().consumeApiEventLog((AppEventLog) event.getObj());
break;
case API_SESSION:
DisruptorHelper.getInstance().consumeApiSessionLog((AppEventSession) event.getObj());
break;
case API_EXT:
DisruptorHelper.getInstance().consumeApiExtLog((AppEventExtinfo) event.getObj());
break;
case XX_TRACK:
DisruptorHelper.getInstance().consumeXxEvent((EventDetail) event.getObj());
break;
default:
break;
}
} catch (Exception e) {
log.error("disruptor消费失败,出错信息: {},原因为:{} ", e.getMessage(), e.getStackTrace()[0]);
}
}
高级用法
依赖关系(消费等待)
例如,下图

管理消费者的依赖关系需要两个 ConsumerBarrier 对象。第一个仅仅与 Ring Buffer 交互,C1 和 C2 消费者向它申请下一个可访问节点。第二个 ConsumerBarrier 只知道消费者 C1 和 C2,它返回两个消费者访问过的消息序号中较小的那个。关键代码:com.lmax.disruptor.RingBuffer#addGatingSequences
源码分析
消费者
创建消费者,构建消费者链
Disruptor#createEventProcessors(com.lmax.disruptor.Sequence[], com.lmax.disruptor.EventHandler<? super T>[])
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
checkNotStarted();
// 对应此事件处理器组的序列组
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i];
// 批量处理事件的循环
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null)
{
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
// 记录每个消费者处理情况
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
// 每次添加完事件处理器后,更新门控序列
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}
BatchEventProcessor批量处理消息
private void processEvents()
{
T event = null;
// sequence.get()是当前读取到序号,+1则是下一个需要读取的下标
long nextSequence = sequence.get() + 1L;
while (true)
{
try
{
// 申请读取元素的最大序号
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null && availableSequence >= nextSequence)
{
// 总共申请读取多少个元素
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
}
while (nextSequence <= availableSequence)
{ // 读取元素
event = dataProvider.get(nextSequence);
// 回调用户实现的eventHandler的onEvent方法
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
// 移动读指针
nextSequence++;
}
// 读取完后,设置目前指针所在位置
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (running.get() != RUNNING)
{
break;
}
}
catch (final Throwable ex)
{
handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}
例子:
可用序列屏障SequenceBarrier
主要作用是用于等待并获取可用的消费事件,其中一个实现类为ProcessingSequenceBarrier,主要看它waitFor方法
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
checkAlert();
// 获取最大可用序号 sequence为给定序号,一般为当前序号+1,cursorSequence记录生产者最新位置
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence)
{
return availableSequence;
}
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
主要是waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);这一行,WaitStrategy有不同的实现类,实现了不同的等待策略。
等待策略
前面基础概念中有列出不同的等待策略,以BlockingWaitStrategy为例,它的做法是进行加锁。
public long waitFor(final long sequence, final Sequence cursorSequence, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
// 消费者序号大于生产者,说明消费速度过快
if (cursorSequence.get() < sequence)
{ // 需要进行等待
synchronized (mutex)
{
while (cursorSequence.get() < sequence)
{
barrier.checkAlert();
mutex.wait();
}
}
}
// 给定序号大于上一个消费者组最慢消费者序号时,需要等待。
// 不能超前消费上一个消费者组未消费完毕的事件。
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
// JDK 9用法,让线程等待一下
Thread.onSpinWait();
}
return availableSequence;
}
生产者
单生产者获取写入位置:
public long next(final int n)
{
if (n < 1 || n > bufferSize)
{
throw new IllegalArgumentException("n must be > 0 and < bufferSize");
}
// 当前RingBuffer的游标,即生产者的位置指针
long nextValue = this.nextValue;
long nextSequence = nextValue + n;
// 减掉一圈 用来判断next是否超出buff的长度
long wrapPoint = nextSequence - bufferSize;
// 上一次缓存的最小的消费者指针
long cachedGatingSequence = this.cachedValue;
// 生产者指针的位置超过当前消费最小的指针
// 如果还没开始消费cachedGatingSequence为-1,wrapPoint值没有走过一圈,那么比cachedGatingSequence小,可以进行写入
// 如果wrapPoint值走过了一圈,那么就需要限制不能覆盖未读数据。
// 或 最慢消费者在当前写入位置的前面,说明写入位置已经过期
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)
{
cursor.setVolatile(nextValue); // StoreLoad fence
long minSequence;
//再次遍历所有消费者的指针,确认是否超过;如果超过最慢消费者,则等待
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue)))
{ // 空间不够用,生产者等待一下
LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin?
}
this.cachedValue = minSequence;
}
this.nextValue = nextSequence;
return nextSequence;
}
发布事件:
public void publish(final long sequence)
{
// 记录了该生产者目前生产到的序号
cursor.set(sequence);
// 通知等待数据的消费者
waitStrategy.signalAllWhenBlocking();
}
多生产者获取写入位置:
public long next(final int n)
{
if (n < 1 || n > bufferSize)
{
throw new IllegalArgumentException("n must be > 0 and < bufferSize");
}
long current = cursor.getAndAdd(n);
long nextSequence = current + n;
// 用来判断next是否超出buff的长度,wrapPoint也可以认为是可能追尾的点(wrapPoint大于1,那么一句走过一圈了)
long wrapPoint = nextSequence - bufferSize;
//当前处理队列尾,在多消费者模式下,消费者会预分配处理位置,所以gatingSequenceCache可能会超过写入的位置
long cachedGatingSequence = gatingSequenceCache.get();
// 生产者指针的位置超过当前消费最小的指针 或 队列尾在当前写入位置的前面,说明写入位置已经过期
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
long gatingSequence;
while (wrapPoint > (gatingSequence = Util.getMinimumSequence(gatingSequences, current)))
{
LockSupport.parkNanos(1L); // TODO, should we spin based on the wait strategy?
}
gatingSequenceCache.set(gatingSequence);
}
return nextSequence;
}
发布事件:
public void publish(final long sequence)
{
//设置sequence序列可读
setAvailable(sequence);
// 通知等待的消费者
waitStrategy.signalAllWhenBlocking();
}
private void setAvailable(final long sequence)
{
setAvailableBufferValue(calculateIndex(sequence), calculateAvailabilityFlag(sequence));
}
private void setAvailableBufferValue(final int index, final int flag)
{ // 发布成功同时将同时设置available Buffer里面相应的位置
AVAILABLE_ARRAY.setRelease(availableBuffer, index, flag);
}
private int calculateAvailabilityFlag(final long sequence)
{
return (int) (sequence >>> indexShift);
}
开源框架应用场景
以Log4j 2为例,异步模式采用的是Disruptor,与Log4j 1最大的优势在于多线程并发场景下性能更优。以下是摘自log4j官网的实验数据:

在在64个线程的下,loggers all async的吞吐量明显比Async Appender优。
在log4j2中,AsyncLogger内部使用了AsyncLoggerDisruptor,这个类中持有disruptor实例,用来完成异步日志处理。在打印日志时,将生成的LogEvent放入RingBuffer中,利用RingBufferLogEventHandler进行消费日志,具体可见log4j2源码,这里不再解析。
参考地址
- https://tech.meituan.com/2016/11/18/disruptor.html
- https://www.hangge.com/blog/cache/detail_2851.html
- https://blog.csdn.net/a78270528/article/details/79925404
- https://zhuanlan.zhihu.com/p/364440317
- http://ziyue1987.github.io/pages/2013/09/22/disruptor-use-manual.html
- https://logging.apache.org/log4j/2.x/manual/async.html
- https://github.com/LMAX-Exchange/disruptor



