@[toc]
函数
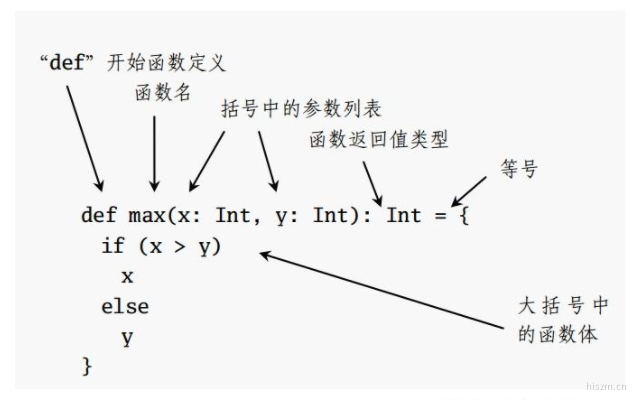
方法定义
def 方法名(参数: 参数类型): 返回值类型 = {
//方法体
//最后一行作为返回值(不需要使用return)
}
def max(x: Int, y: Int): Int = {
if(x > y)
x
else
y
}
package org.example
object App {
def main(args: Array[String]): Unit = {
println(add(2,5))
}
def add(x:Int,y:Int):Int={
x+y
}
}
7
package org.example
object App {
def main(args: Array[String]): Unit = {
println(three())
//没有入参的时候可以不用写
println(three)
}
def three()=1+2
}
无返回值 自动加Unit
默认参数
默认参数: 在函数定义时,允许指定参数的默认值
//参数
def sayName(name: String ) = {
println(name)
}
//默认参数
def sayName1(name: String ="Jack") = {
println(name)
}
//main调用
sayName("jaja")
sayName1()
sayName1("Ma")jaja
Jack
Ma
相关源码:SparkContext中使用
命名参数
可以修改参数的传入 顺序
def speed(destination: Float, time: Float): Float {
destination / time
}
println(speed(100, 10))
println(speed(time = 10, destination = 100))
可变参数
变参数(可传入任意多个相同类型的参数) java中 int... numbers
JDK5+:可变参数
def sum(number: Int*) = {
var result = 0
for(num <- number) {
result += num
}
result
}
相关源码:org.apache.spark.sql.Dataset中的select方法
条件语句

循环语句
- to 1 to 10 (左闭右闭) 1.to(10)
- range Range(1,10) (左闭右开的) Range(1,10,2) (2为步长)
- until 1 until 10 (左闭右开)
to、until的底层调用都是Range
scala> 1 to 10
res1: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> Range(1,10)
res2: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> 1.to(10)
res3: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> Range(1,10,2)
res4: scala.collection.immutable.Range = Range(1, 3, 5, 7, 9)
scala> Range(1,10,5)
res5: scala.collection.immutable.Range = Range(1, 6)
scala> Range(10,1,-1)
res8: scala.collection.immutable.Range = Range(10, 9, 8, 7, 6, 5, 4, 3, 2)
scala> 1 until 10
res9: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
- for
for(i <- 1.to(10)) {
println(i)
}
for(i <- 1.until(10, 2)) {
println(i)
}
for(i <- 1 to 10 if i % 2 == 0) {
println(i)
}
val courses = Array("Hadoop", "Spark SQL", "Spark Streaming", "Storm", "Scala")
for(x<- courses) {
println(x)
}
//x其实就是courses里面的每个元素
// => 就是将左边的x作用上一个函数,变成另外一个结果
courses.foreach(x=> println(x))
- while
var (num, sum) = (100, 0)
while(num > 0){
sum = sum + num
num = num - 1
}
println(sum)面向对象
概述
Java/Scala OO(Object Oriented)
- 封装:属性、方法封装到类中,可设置访问级别
- 继承:父类和子类之间的关系 重写
- 多态:父类引用指向子类对象 开发框架基石
Person person = new Person();
User user = new User();
Person person =new User();类的定义和使用
package org.example
object ObjectApp {
def main(args: Array[String]): Unit = {
val person = new People()
person.name = "Messi"
// println(person.name + ".." + person.age)
println("invoke eat method: " + person.eat)
person.watchFootball("Barcelona")
person.printInfo()
//编译不通过 private 修饰
// println(person.gender)
}
}
class People{
//var(变量)类型自动生成getter/setter
//这种写法就是一个占位符
var name: String = _
//val(常量)类型自动生成getter
val age: Int = 10
private [this] var gender = "male"
def printInfo() : Unit = {
print("gender: " + gender)
}
def eat(): String = {
name + " eat..."
}
def watchFootball(teamName: String): Unit = {
println(name + " is watching match of " + teamName)
}
}
invoke eat method: Messi eat...
Messi is watching match of Barcelona
gender: male
继承和重写
- 继承
class Student(name: String, age: Int, var major: String) extends Person(name, age) {}
- 重写
override def acquireUnrollMemory()
override def toString = "test override"package org.example
object ConstructorApp {
def main(args: Array[String]): Unit = {
var person =new Person("zhangsan",99)
println(person.age+":"+person.name)
var person2 =new Person("zhangsan",99,"Man")
println(person2.age+":"+person2.name+";"+person2.gender)
}
}
//主构造器
class Person(val name: String, val age: Int){
println("Person constructor enter...")
val school = "ustc"
//占位符肯定要预先指定类型
var gender: String = _
//附属构造器
def this(name: String , age: Int, gender: String){
//必须要调用主构造器或者其他附属构造器
this(name, age)
this.gender = gender
}
override def toString = "test override"
println("Person Constructor leave...")
}
//继承
//name: String, age: Int, var major: String 继承父类的可以不用直接写var 否则需要重新申明
class Student(name: String, age: Int, var major: String) extends Person(name, age) {
//重写
override val school = "pku"
println("Person Student enter...")
println("Person Student leave...")
}
抽象类
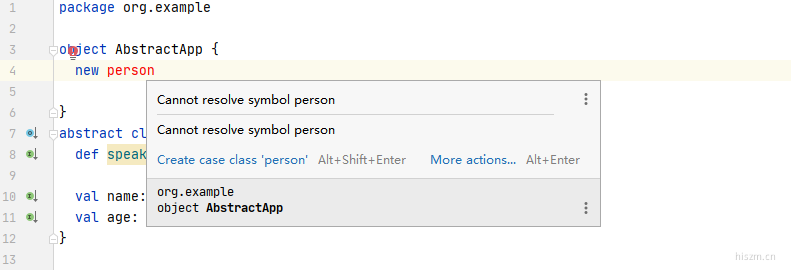
package org.example
object AbstractApp {
def main(args: Array[String]): Unit = {
var stu =new Student1();
println(stu.age)
println(stu.name)
stu.speak;
}
}
abstract class Person3{
def speak
val name: String
val age: Int
}
class Student1 extends Person3{
override def speak: Unit = {
println("speak")
}
override val name: String = "Messi"
override val age: Int = 32
}
伴生类和伴生对象
如果有一个class,还有一个与class同名的object互为 伴生类和伴生对象
class ApplyTest{
def apply(){
println(...)
}
}
object ApplyTest{
def apply(){
println("Object ApplyTest apply...")
new ApplyTest
}
} 类名() ==> Object.apply
对象() ==> Class.apply
最佳实践:在Object的apply方法中去new一个Class
package org.example
object ApplyApp {
def main(args: Array[String]): Unit = {
// for(i<-1 to 10){
// ApplyTest.incr
// }
// //object 是一个单例对象
// println(ApplyTest.count)
var b=ApplyTest()
//默认走的是object=》apply
//Object ApplyTest apply...
println("-----------------------")
var c= new ApplyTest()
c()
//Class ApplyTest apply...
}
}
class ApplyTest {
def apply() = {
println("Class ApplyTest apply...")
}
}
object ApplyTest {
println("Object start...")
var count = 0
def incr={
count=count+1
}
def apply() = {
println("Object ApplyTest apply...")
//在object中的apply中new class
new ApplyTest
}
println("Object end...")
}
case和trait
case class :不用new
case class Dog(name: String)
直接可以调用Dog("wangcai")
Trait: 类似implements
xxx entends ATrait
xxx extends Cloneable with Logging with Serializable源码中Partition类