前言
在分布式系统领域,CAP定理可谓鼎鼎大名,各种理解和解释颇多,今天,我也来聊聊自己的感受。
1.CAP基本概念
首先我们先描述一下CAP定理的基本概念:
1.1 一致性
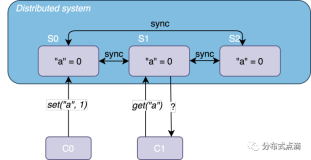
- 一致性(Consistency):每次请求都可以得到最新的数据。对于单机系统而言,这一点似乎很容易保证,比如我们更新的单机数据库中的一条记录之后无论怎么读取数据,都能得到更新之后的最新数据【注1】。
但是对于一个有多个节点的分布式系统,情况就没有这么简单了,一般情况下节点之间的数据是通过“复制”的方式来同步的,假设你更新系统中某一节点的一条数据,对数据的更新操作会复制到系统的其他节点,但是复制有一个“窗口期”,也就是说一个节点的更新复制到另一个节点上需要一定的时间,在“窗口期”时间之内,请求到复制没有完成的节点返回的数据就会产生不一致情况。
理论上,我们减小“窗口期”时间就可以降低不一致发生的概率,但是“窗口期”永远不可能为零,及时节点“复制”达到了光速,即使使用了量子纠缠也不能让复制行为达到“同步”,所以完美的一致性在这个宇宙是不存在的只存在于神话中。
1.2 可用性
- 可用性(Availability):每次请求都可以得到一个响应,但是得到的数据不一定是最近的数据。对于一个要持续可用的分布式系统,每一个非故障的节点必须对每一个请求作出响应。也就是说,服务使用的任何算法都必须最终终止,当同时要求分区容忍性时,这是一个很强的定义:即使是严重的网络错误,每个请求必须终止。这里需要注意发生故障且无法响应客户请求的节点,并不会导致失去这里所述的“可用性”。
可用性保证每次请求都能得到响应,即使某些节点挂了,系统依然要响应请求。这点对于分布式系统至关重要,我们不能保证系统中众多节点在运行期间整体可用,总会出现不可用的情况,比如节点崩溃、节点数据异常、节点连接超时等,所以我们要保证某些节点不可用的情况下系统依然可用。
虽然我们可用通过添加节点避免单点故障来提升整个系统的可用性,但是显而易见的是我们依然不能保证100%可用,我们只能提升小数点后九的位数(99.999...%)。所以绝对的可用是无法达到的,话说只要一说“绝对”好像都不靠谱。
1.3 分区容错性
- 分区容错性(Partition tolerance):当系统中有节点因网络原因无法通信时,系统依然可以继续运行。分布式系统由多个节点组成,节点间的网络通信总是不可靠的,所有我们总是要保证分布式系统节点间产生网络分区的情况下,这样分布式系统才有存在的意义。
这里需要注意的是,节点故障是否属于网络分区?这个问题确实容易让人产生误解。假设我们有一个由三个节点组成的系统,其中一个节点down了,如果我们认为这种情况下产生了网络分区,那么我们只能在可用性和一致性做出选择。但是我们发现根据可用性定义,故障的节点并不影响可用性,而且故障节点已经不会相应任何请求了,其他节点可以很容易地进行补偿(例如主备模式),弥补了可用性和一致性。所以如果节点故障属于网络分区,我们就得到一个违背CAP定理的结论——C、A、P我们可以同时保证。至此我们从反面证明了网络故障不属于网络分区。
2、可用性和容错性的区别
可用性容易与分区容错性相混淆,这两个概念都是保证系统可以持续对外提供服务。但是两个概念侧重点不同,可用性是保证系统中某些节点故障的情况下系统可用,而分区容错性是保证系统出现网络分区即某些节点相互通信失败的情况下,系统依然可用。
3、CAP三者取舍
CAP定理定义了这三个属性之间的相互关系:根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。这样就产生三种取舍情况:CA(withoutP)、CP(withoutA)、AP(withoutC)。
- CA:这种情况相当于只满足可用性和一致性,不在满足分区容错性。在现实世界中,分布式系统中节点之间的网络异常不可避免。所以如果不保证分区容错性,除非节点间永不发生网络异常,显然这样不可能【注2】。或者极端一点的假设是不存在网络通信,那整个节点就变成单一节点的单机系统。所以,单纯的CA分布式系统并不存在。现在互联网应用的场景中,系统节点众多,节点之间网络异常不可避免,所以要保证系统正常运行必须保证分区容错性,那根据CAP定理,就要在可用性和一致性间做出选择,从实际业务的角度上,这种选择更像是一种权衡,就是说我们更倾向于可用性多一些或者更倾向于一致性多一些。
CP:当系统中出现网络分区的情况时,我们选择保证一致性,这时请求就会等待,直到问题节点网络异常恢复。传统数据库的分布式事务大多采用这种模式,众所周知XA事务最大的缺点就在于超时问题上,如果对一个资源管理器的事务提交操作因为网络原因等待,参与分布式事务其他节点都需要等待延时节点,致使系统变慢并最终导致不可用。
AP:当系统出现网络分区的情况时,我们选择保证可用性,此时所有节点可以正常响应请求,但由于节点之间不能相互联络,节点只能用本地数据响应请求,此时节点间本地数据有可能不同步,为了保证高可用,我们放弃了一致性
。MySQL主从复制模式就是典型的AP应用场景,当主从节点产生网络延时致使从节点数据不能及时同步时,我们无需等待网络恢复,依然可以继续访问从节点获取数据。
总结
在当下互联网业务场景中,我们更多的时候是在可用性和一致性之间做出选择。在实际的业务中,单纯保证一致性不但无法达到也会严重的影响系统的效率,同理可证,想要绝对的可用性也是不现实的,任何业务流程也不会允许大量的非一致性数据出现,这样就造成了整体业务逻辑失败。分布式系统的可用性和一致性就如同太极阴阳两面,你中有无,我中有你,作为架构师我们努力在业务场景寻找一致性和可用性的平衡点,对于架构师而言,“最”不重要,“合适”更好。
备注:
注1:单机系统依然会产生一致性问题,只是与CAP中一致性不是一个问题,故不在此展开。
注2:这里还有一种情况比较特殊,这种情况是“CA”集群,这种集群极少发生网络分区情况,且一旦发生分区,就让分区中的所有节点停止工作。这样操作相当于舍弃了有问题节点,系统中其他正常节点就不存在分区问题了。我们并没有在存在分区的系统中继续工作,我们很粗暴的解决了网络分区的情况。从某种意义上说,这是可以实现的,但是实现起来非常麻烦,需要实时监控系统中节点是否出现网络分区并且在一旦出现分区即可将分区内的节点全部下线。说到这里你一定有一个疑惑,如果我们将节点下线的难道不会影响CA中的可用性吗?根据可用性定义可知,故障节点并不影响可用性,因为可用性需要保证非故障节点有响应。所以此处将分区节点下线以解决分区问题并不会影响可用性。