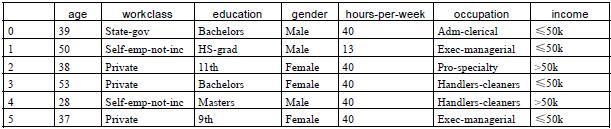
最近想要把学的机器学习算法用起来,所以开始看看kaggle上的比赛。看了两个新人入门赛泰坦尼克号生还预测和房屋价格预测。总结一下看代码的一些经验吧。
总体感觉是,在建立特征工程上耗费的时间,要远远大于训练模型和调参的过程。可见特征的重要性。而且,在数据科学的比赛中,用xgboost方法的占到大多数,这里再次膜拜一下陈天奇大神······
Import pakages
pandas和numpy
数据的一般格式都是.csv文件,处理用的包是pandas。其基本的数据结构为dataframe和series.
import pandas as pd
import numpy as np
#创建dataframe对象
df1 = pd.DataFrame({'col1':[1,3],'col2':[2,4]},index = ['a','b'])
df2 = pd.DataFrame(np.array([[1,3,5],[2,4,6]]),columns = ['col1','col2'])#大小2*3
#如果不加index,默认行索引为0,1,2...数字
#创建dataframe对象的数据可以为列表,字典,数组。#基本操作:
#1.索引操作
df1.index#行
df2.columns#列
df1.loc['a']#索引这一行的数据
#df.loc[]与df.iloc[]的区别:.loc[]索引的是行名,.iloc[]索引的是行数字
df2['col1']#访问列数据
#支持组合选择
df2[['col1','col2']]
#行列索引
df2.iloc[2]['a']
#2.数据合并
#三种方法:join,concat,append,merge
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
#concat可横向,可纵向,axis = 0,表示横向,axis=1,表示纵向。
#join:{inner,outer}:合并方式,默认为outer,表示并集,inner表示交集
#ignore_index:{False,True},是否忽略原index,默认为不忽略
#keys:为原始dataframe添加一个键,默认为无
df1 = df1.append(df2)
#横向和纵向同时扩充
df1.join(df2,how = 'inner')
#3.丢弃数据
#drop方法
df1 = df1.drop('a',axis = 1)#丢掉列matplotlib,seaborn
用于数据的可视化scipy
统计模块
from scipy import stats
from scipy.stats import skew, norm
from scipy.special import boxcox1p
from scipy.stats.stats import pearsonr#皮尔森相关系数矩阵- sklearn
这是主要的模块。里面包含各种机器学习算法,数据预处理方法,模型选择、特征选择方法等。
import data
pd.read_csv(filename)data preparation
- 缺失值处理
首先通过concat方法,把训练集和数据集连接在一起处理。
# First of all, save the length of the training and test data for use later
ntrain = train.shape[0]
ntest = test.shape[0]
# Also save the target value, as we will remove this
y_train = train.SalePrice.values
# concatenate training and test data into all_data
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)主要两种处理方法,要不就删去,要不就补全。所以要观察缺失值缺的是啥,为什么会缺失。
比如:大量的缺失,可能是因为这个不重要,或者大多数不存在,所以可以酌情删除这个特征。如果缺失的数量较少,那么观察这个数值类型,是数值型还是标签类型。是不是可以用众数、中位数、或者均值来进行填充。
异常值处理(outlier)
可以通过plot的方式,看看是否存在明显的异常值或者离群值,然后手动剔除就行。常用方法
data.groupby():groupby可以通过传入需要分组的参数实现对数据的分组.groupby之后的数据并不是DataFrame格式的数据,而是特殊的groupby类型,此时,可以通过size()方法返回分组后的记录数目统计结果,该结果是Series类型.通过groupby完成对数据的分组后,可以通过get_group方法来获取某一制定分组的结果data.isnull():判断是否包含空值。可再使用sum方法计算空值数量。data.isnull().sum()统计出来的结果是每一列的空值总数。data.fillna():填充空值data analysis and feature engineering
接下来到了重要且费时的部分了。分析数据之间的关系,通过去除或合并冗余特征,降维等方式,建立特征工程。选择到一组好的特征,即使与别人用相同的学习方法,也能得到秒杀众人的结果。所以在数据科学的比赛中,我感觉特征是第一重要,其次才是机器学习方法和参数。
通过前面的处理,把缺失值补全,而且异常值也去除。接下来,首先对所有数据之间的相关性进行总体的预览。这就用到了计算相关系数的方法。
DataFrame.corr(method='pearson', min_periods=1)Compute pairwise correlation of columns, excluding NA/null values.这里默认用pearson相关系数
然后可以用seaborn的热力图进行显示。
sns.heatmap(corr, cmap="RdYlBu", vmax=1, vmin=-0.6, center=0.2, square=True, linewidths=0, cbar_kws={"shrink": .5}, annot = True);也可以用seaborn的pairplot方法:
Plot pairwise relationships in a dataset.
seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, kind='scatter', diag_kind='hist', markers=None, size=2.5, aspect=1, dropna=True, plot_kws=None, diag_kws=None, grid_kws=None)¶有了对数据之间的相关性的初步了解,接下来就是建立特征工程了。这一部分比较方法比较个性化感觉,但大概意思应该是一一分析,两两之间通过画图直观观察可能有怎样的相关性,是线性关系,平方关系还是什么的。最终确定应用到学习算法中的数据有哪些。
这里常用到的一些方法总结如下:
sns.boxplot()
sns.stripplot()
sns.barplot()
sns.regplot()

- 将数值型转化为标签型,即将数值离散化
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
#for example
>>> pd.cut(np.array([.2, 1.4, 2.5, 6.2, 9.7, 2.1]),
... 3, labels=["good", "medium", "bad"])
...
>>> [good, good, good, medium, bad, good]
Categories (3, object): [good < medium < bad]- 哑变量
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
#for example
s = pd.Series(list('abca'))
>>> pd.get_dummies(s)
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0Convert categorical variable into dummy/indicator variables.
在很多数据处理中,我们都需要对数据进行哑变量处理。例如,某个数据中的月份用1-12进行表示,但是月份的值本身并没有数值上的意义,比方说2月份比1月份多,这显然是不合理的。
对目标变量的处理:
这里主要是对目标变量分布所做的一点变换。因为大部分机器学习算法在正态分布上可能应用的更好/但是通过观察数据的频率分布直方图,可以看出他们是偏态分布,此时需要做一点变换,使之与正态分布相近,这样可以的到更好的预测效果。但是,需要注意的是,当做出变换之后,在最后的时候,还要变换回来。这里以房价预测中所应用的方法为例:
g = sns.distplot(train['SalePrice'], fit=norm, label = "Skewness : %.2f"%(train['SalePrice'].skew()));
#观察到分布为正偏态。
#We use the numpy fuction log1p which applies log(1+x) to all elements of the column
train["SalePrice"] = np.log1p(train["SalePrice"])以上为对目标变量的变换。
对于数值类型为数值的特征变量,也需要进行类似的变换。通过统计每一变量的skew值(偏度/偏态值,越接近0,越符合正态分布。大于0为正偏态,小于0为负偏态),对绝对值大于0.5的进行boxcox变换。
box - cox变换
可以使线性回归模型满足线性性、独立性、方差齐性以及正态性的同时,又不丢失信息,此种变换称之为Box—Cox变换。这种变换是对变量y进行变换
误差与y相关,不服从正态分布,于是给线性回归的最小二乘估计系数的结果带来误差
使用Box-Cox变换族一般都可以保证将数据进行成功的正态变换,但在二分变量或较少水平的等级变量的情况下,不能成功进行转换,此时,我们可以考虑使用广义线性模型,如LOGUSTICS模型、Johnson转换等。
Box-Cox变换后,残差可以更好的满足正态性、独立性等假设前提,降低了伪回归的概率
scipy里面的变换公式为:
其中 x 代表需要变换的数据,y代表数据变换后的结果
Modeling
此处先按下不表,以后再详细写
submission
将dataframe生成.csv文件,然后提交就OK啦!
dataframe.to_csv('final_submission.csv',index=False)