
一、逻辑回归简介
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。
logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。
其公式如下:
![]()
其图像如下:

我们通过观察上面的图像可以发现,逻辑回归的值域为(0, 1),当输入为0时,其输出为0.5;当输入小于0,并且越来越小时,其输出越来越接近于0;相反的,当其输入大于0,并且越来越大时,其输出越来越接近于1。
通常我们使用线性回归来预测值,但逻辑回归随有“回归”二字,却通常是用来解决二分类问题的。
当其输出大于0.5时,我们可以认为该样本属于甲类;小于0.5时,认为该样本属于已类。
但是由于一个样本数据通常会有多个特征,我们不能将其直接带入logistic回归公式中,所以,就需要借助之前所介绍的线性回归,使该样本的多个特征值生成一个特定的值,在带入公式中,对其分类,所以z的表达式如下:
![]()
即可得到对于一个数据关于逻辑回归的详细表达式:

通过上式,我们就可以对一个任意数据进行逻辑回归分析了,但是这当中存在一个问题,即关于θ的取值,只有公式中的θ已知,我们才能对一个未分类的数据运用此公式,那么该如何求得θ呢?
请看下面的公式推导。
二、Logistic Regression公式推导
在上面,我们得到 ![]() 后,需要求得θ,关于如何求得θ,将在此进行详细分析。
后,需要求得θ,关于如何求得θ,将在此进行详细分析。
通常在机器学习中,我们常常有一个过程叫训练,所谓训练,即通过已知分类(或标签)的数据,求得一个模型(或分离器),然后使用这个模型对未知标签的数据打上标签(或者对其进行分类)。
所以,我们使用样本(即已知分类的数据),进行一系列的估算,得到θ。这个过程在概率论中叫做参数估计。
在此,我们将使用极大似然估计的推导过程,求得关于计算θ的公式:
(1) 首先我们令:

(2) 将上述两式整合:
![]()
(3) 求其似然函数:

(4) 对其似然函数求对数:

(5) 当似然函数为最大值时,得到的θ即可认为是模型的参数。求似然函数的最大值,我们可以使用一种方法,梯度上升,但我们可以对似然函数稍作处理,使之变为梯度下降,然后使用梯度下降的思想来求解此问题,变换
的表达式如下:
![]() (由于乘了一个负的系数,所以梯度上升变梯度下降。)
(由于乘了一个负的系数,所以梯度上升变梯度下降。)
(6) 因为我们要使用当前的θ值通过更新得到新的θ值,所以我们需要知道θ更新的方向(即当前θ是加上一个数还是减去一个数离最终结果近),所以得到J(θ)后对其求导便可得到更新方向(为什么更新方向这么求?以及得到更新方向后为什么按照下面的式子处理?请看下方的梯度下降公式的演绎推导),求导过程如下:

(7) 得到更新方向后便可使用下面的式子不断迭代更新得到最终结果。
![]()
三、梯度下降公式的演绎推导
关于求解函数的最优解(极大值和极小值),在数学中我们一般会对函数求导,然后让导数等于0,获得方程,然后通过解方程直接得到结果。但是在机器学习中,我们的函数常常是多维高阶的,得到导数为0的方程后很难直接求解(有些时候甚至不能求解),所以就需要通过其他方法来获得这个结果,而梯度下降就是其中一种。
对于一个最简单的函数: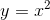 , 我们该如何求出y最小是x的值呢(不通过解2x = 0的方法)?
, 我们该如何求出y最小是x的值呢(不通过解2x = 0的方法)?

(1) 首先对x任取一个值,比如x = -4,可以得到一个y值。

(2) 求得更新方向(如果不求更新方向对x更新,比如x-0.5,或x+0.5,得到图像如下)。

可以发现,我们如果是向负方向更新x,那么我就偏离了最终的结果,此时我们应该向正方向更新,所以我们在对x更新前需要求得x的更新方向(这个更新方向不是固定的,应该根据当前值确定,比如当x=4时,应向负方向更新)
求其导函数在这一点的值,y' = 2x,x = -4, y' = -8,那么它的更新方向就是y',对x更新我们只需x:=x-α·y'(α(大于0)为更新步长,在机器学习中,我们叫它学习率)。
PS:之前说了是多维高阶方程,无法求解,而不是不能对其求导,所以可以对其求导,然后将当前x带入。
(3) 不断重复之前的(1),(2)步,直到x收敛。
梯度下降方法:
对于这个式子![]() ,如果:
,如果:
(1) m是样本总数,即每次迭代更新考虑所有的样本,那么就叫做批量梯度下降(BGD),这种方法的特点是很容易求得全局最优解,但是当样本数目很多时,训练过程会很慢。当样本数量很少的时候使用它。
(2)当m = 1,即每次迭代更新只考虑一个样本,公式为![]() ,叫做随机梯度下降(SGD),这种方法的特点是训练速度快,但是准确度下降,并不是全局最优。比如对下列函数(当x=9.5时,最终求得是区部最优解):
,叫做随机梯度下降(SGD),这种方法的特点是训练速度快,但是准确度下降,并不是全局最优。比如对下列函数(当x=9.5时,最终求得是区部最优解):

(3) 所以综上两种方法,当m为所有样本数量的一部分(比如m=10),即我们每次迭代更新考虑一小部分的样本,公式为![]() ,叫做小批量梯度下降(MBGD),它克服了上述两种方法的缺点而又兼顾它们的优点,在实际环境中最常被使用。
,叫做小批量梯度下降(MBGD),它克服了上述两种方法的缺点而又兼顾它们的优点,在实际环境中最常被使用。

