真正掌握一种算法,最实际的方法,完全手写出来。
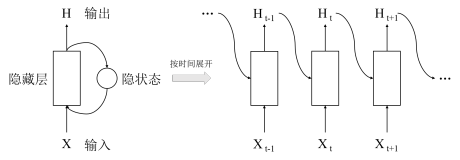
LSTM(Long Short Tem Memory)特殊递归神经网络,神经元保存历史记忆,解决自然语言处理统计方法只能考虑最近n个词语而忽略更久前词语的问题。用途:word representation(embedding)(词语向量)、sequence to sequence learning(输入句子预测句子)、机器翻译、语音识别等。
100多行原始python代码实现基于LSTM二进制加法器。https://iamtrask.github.io/2015/11/15/anyone-can-code-lstm/ ,翻译http://blog.csdn.net/zzukun/article/details/49968129 :
import copy, numpy as np
np.random.seed(0)最开始引入numpy库,矩阵操作。
def sigmoid(x):
output = 1/(1+np.exp(-x))
return output声明sigmoid激活函数,神经网络基础内容,常用激活函数sigmoid、tan、relu等,sigmoid取值范围[0, 1],tan取值范围[-1,1],x是向量,返回output是向量。
def sigmoid_output_to_derivative(output):
return output*(1-output)声明sigmoid求导函数。
加法器思路:二进制加法是二进制位相加,记录满二进一进位,训练时随机c=a+b样本,输入a、b输出c是整个lstm预测过程,训练由a、b二进制向c各种转换矩阵和权重,神经网络。
int2binary = {}声明词典,由整型数字转成二进制,存起来不用随时计算,提前存好读取更快。
binary_dim = 8largest_number = pow(2,binary_dim)
声明二进制数字维度,8,二进制能表达最大整数2^8=256,largest_number。
binary = np.unpackbits(
np.array([range(largest_number)],dtype=np.uint8).T,axis=1)
for i in range(largest_number):
int2binary[i] = binary[i]预先把整数到二进制转换词典存起来。
alpha = 0.1
input_dim = 2
hidden_dim = 16
output_dim = 1设置参数,alpha是学习速度,input_dim是输入层向量维度,输入a、b两个数,是2,hidden_dim是隐藏层向量维度,隐藏层神经元个数,output_dim是输出层向量维度,输出一个c,是1维。从输入层到隐藏层权重矩阵是216维,从隐藏层到输出层权重矩阵是161维,隐藏层到隐藏层权重矩阵是16*16维:
synapse_0 = 2*np.random.random((input_dim,hidden_dim)) - 1
synapse_1 = 2*np.random.random((hidden_dim,output_dim)) - 1
synapse_h = 2*np.random.random((hidden_dim,hidden_dim)) - 12x-1,np.random.random生成从0到1之间随机浮点数,2x-1使其取值范围在[-1, 1]。
synapse_0_update = np.zeros_like(synapse_0)
synapse_1_update = np.zeros_like(synapse_1)
synapse_h_update = np.zeros_like(synapse_h)声明三个矩阵更新,Delta。
for j in range(10000):进行10000次迭代。
a_int = np.random.randint(largest_number/2)
a = int2binary[a_int]
b_int = np.random.randint(largest_number/2)
b = int2binary[b_int]
c_int = a_int + b_int
c = int2binary[c_int]随机生成样本,包含二进制a、b、c,c=a+b,a_int、b_int、c_int分别是a、b、c对应整数格式。
d = np.zeros_like(c)d存模型对c预测值。
overallError = 0全局误差,观察模型效果。
layer_2_deltas = list()
存储第二层(输出层)残差,输出层残差计算公式推导公式http://deeplearning.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95 。
layer_1_values = list()
layer_1_values.append(np.zeros(hidden_dim))存储第一层(隐藏层)输出值,赋0值作为上一个时间值。
for position in range(binary_dim):遍历二进制每一位。
X = np.array([[a[binary_dim - position - 1],b[binary_dim - position - 1]]])
y = np.array([[c[binary_dim - position - 1]]]).TX和y分别是样本输入和输出二进制值第position位,X对于每个样本有两个值,分别是a和b对应第position位。把样本拆成每个二进制位用于训练,二进制加法存在进位标记正好适合利用LSTM长短期记忆训练,每个样本8个二进制位是一个时间序列。
layer_1 = sigmoid(np.dot(X,synapse_0) + np.dot(layer_1_values[-1],synapse_h))公式Ct = sigma(W0·Xt + Wh·Ct-1)
layer_2 = sigmoid(np.dot(layer_1,synapse_1))这里使用的公式是C2 = sigma(W1·C1),
layer_2_error = y - layer_2计算预测值和真实值误差。
layer_2_deltas.append((layer_2_error)*sigmoid_output_to_derivative(layer_2))反向传导,计算delta,添加到数组layer_2_deltas
overallError += np.abs(layer_2_error[0])计算累加总误差,用于展示和观察。
d[binary_dim - position - 1] = np.round(layer_2[0][0])存储预测position位输出值。
layer_1_values.append(copy.deepcopy(layer_1))存储中间过程生成隐藏层值。
future_layer_1_delta = np.zeros(hidden_dim)存储下一个时间周期隐藏层历史记忆值,先赋一个空值。
for position in range(binary_dim):遍历二进制每一位。
X = np.array([[a[position],b[position]]])取出X值,从大位开始更新,反向传导按时序逆着一级一级更新。
layer_1 = layer_1_values[-position-1]取出位对应隐藏层输出。
prev_layer_1 = layer_1_values[-position-2]取出位对应隐藏层上一时序输出。
layer_2_delta = layer_2_deltas[-position-1]取出位对应输出层delta。
layer_1_delta = (future_layer_1_delta.dot(synapse_h.T) + layer_2_delta.dot(synapse_1.T)) * sigmoid_output_to_derivative(layer_1)神经网络反向传导公式,加上隐藏层?值。
synapse_1_update += np.atleast_2d(layer_1).T.dot(layer_2_delta)累加权重矩阵更新,对权重(权重矩阵)偏导等于本层输出与下一层delta点乘。
synapse_h_update += np.atleast_2d(prev_layer_1).T.dot(layer_1_delta)前一时序隐藏层权重矩阵更新,前一时序隐藏层输出与本时序delta点乘。
synapse_0_update += X.T.dot(layer_1_delta)输入层权重矩阵更新。
future_layer_1_delta = layer_1_delta记录本时序隐藏层delta。
synapse_0 += synapse_0_update * alpha
synapse_1 += synapse_1_update * alpha
synapse_h += synapse_h_update * alpha权重矩阵更新。
synapse_0_update *= 0
synapse_1_update *= 0
synapse_h_update *= 0更新变量归零。
if(j % 1000 == 0):
print "Error:" + str(overallError)
print "Pred:" + str(d)
print "True:" + str(c)
out = 0
for index,x in enumerate(reversed(d)):
out += x*pow(2,index)
print str(a_int) + " + " + str(b_int) + " = " + str(out)
print "------------"每训练1000个样本输出总误差信息,运行时看收敛过程。
LSTM最简单实现,没有考虑偏置变量,只有两个神经元。
完整LSTM python实现。完全参照论文great intro paper实现,代码来源https://github.com/nicodjimenez/lstm ,作者解释http://nicodjimenez.github.io/2014/08/08/lstm.html ,具体过程参考http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 图。
import random
import numpy as np
import math
def sigmoid(x):
return 1. / (1 + np.exp(-x))声明sigmoid函数。
def rand_arr(a, b, *args):
np.random.seed(0)
return np.random.rand(*args) * (b - a) + a生成随机矩阵,取值范围[a,b),shape用args指定。
class LstmParam:
def __init__(self, mem_cell_ct, x_dim):
self.mem_cell_ct = mem_cell_ct
self.x_dim = x_dim
concat_len = x_dim + mem_cell_ct
# weight matrices
self.wg = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wi = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wf = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wo = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
# bias terms
self.bg = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bi = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bf = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bo = rand_arr(-0.1, 0.1, mem_cell_ct)
# diffs (derivative of loss function w.r.t. all parameters)
self.wg_diff = np.zeros((mem_cell_ct, concat_len))
self.wi_diff = np.zeros((mem_cell_ct, concat_len))
self.wf_diff = np.zeros((mem_cell_ct, concat_len))
self.wo_diff = np.zeros((mem_cell_ct, concat_len))
self.bg_diff = np.zeros(mem_cell_ct)
self.bi_diff = np.zeros(mem_cell_ct)
self.bf_diff = np.zeros(mem_cell_ct)
self.bo_diff = np.zeros(mem_cell_ct)LstmParam类传递参数,mem_cell_ct是lstm神经元数目,x_dim是输入数据维度,concat_len是mem_cell_ct与x_dim长度和,wg是输入节点权重矩阵,wi是输入门权重矩阵,wf是忘记门权重矩阵,wo是输出门权重矩阵,bg、bi、bf、bo分别是输入节点、输入门、忘记门、输出门偏置,wg_diff、wi_diff、wf_diff、wo_diff分别是输入节点、输入门、忘记门、输出门权重损失,bg_diff、bi_diff、bf_diff、bo_diff分别是输入节点、输入门、忘记门、输出门偏置损失,初始化按照矩阵维度初始化,损失矩阵归零。
def apply_diff(self, lr = 1):
self.wg -= lr * self.wg_diff
self.wi -= lr * self.wi_diff
self.wf -= lr * self.wf_diff
self.wo -= lr * self.wo_diff
self.bg -= lr * self.bg_diff
self.bi -= lr * self.bi_diff
self.bf -= lr * self.bf_diff
self.bo -= lr * self.bo_diff
# reset diffs to zero
self.wg_diff = np.zeros_like(self.wg)
self.wi_diff = np.zeros_like(self.wi)
self.wf_diff = np.zeros_like(self.wf)
self.wo_diff = np.zeros_like(self.wo)
self.bg_diff = np.zeros_like(self.bg)
self.bi_diff = np.zeros_like(self.bi)
self.bf_diff = np.zeros_like(self.bf)
self.bo_diff = np.zeros_like(self.bo)定义权重更新过程,先减损失,再把损失矩阵归零。
class LstmState:
def __init__(self, mem_cell_ct, x_dim):
self.g = np.zeros(mem_cell_ct)
self.i = np.zeros(mem_cell_ct)
self.f = np.zeros(mem_cell_ct)
self.o = np.zeros(mem_cell_ct)
self.s = np.zeros(mem_cell_ct)
self.h = np.zeros(mem_cell_ct)
self.bottom_diff_h = np.zeros_like(self.h)
self.bottom_diff_s = np.zeros_like(self.s)
self.bottom_diff_x = np.zeros(x_dim)LstmState存储LSTM神经元状态,包括g、i、f、o、s、h,s是内部状态矩阵(记忆),h是隐藏层神经元输出矩阵。
class LstmNode:
def __init__(self, lstm_param, lstm_state):
# store reference to parameters and to activations
self.state = lstm_state
self.param = lstm_param
# non-recurrent input to node
self.x = None
# non-recurrent input concatenated with recurrent input
self.xc = NoneLstmNode对应样本输入,x是输入样本x,xc是用hstack把x和递归输入节点拼接矩阵(hstack是横拼矩阵,vstack是纵拼矩阵)。
def bottom_data_is(self, x, s_prev = None, h_prev = None):
# if this is the first lstm node in the network
if s_prev == None: s_prev = np.zeros_like(self.state.s)
if h_prev == None: h_prev = np.zeros_like(self.state.h)
# save data for use in backprop
self.s_prev = s_prev
self.h_prev = h_prev
# concatenate x(t) and h(t-1)
xc = np.hstack((x, h_prev))
self.state.g = np.tanh(np.dot(self.param.wg, xc) + self.param.bg)
self.state.i = sigmoid(np.dot(self.param.wi, xc) + self.param.bi)
self.state.f = sigmoid(np.dot(self.param.wf, xc) + self.param.bf)
self.state.o = sigmoid(np.dot(self.param.wo, xc) + self.param.bo)
self.state.s = self.state.g * self.state.i + s_prev * self.state.f
self.state.h = self.state.s * self.state.o
self.x = x
self.xc = xcbottom和top是两个方向,输入样本从底部输入,反向传导从顶部向底部传导,bottom_data_is是输入样本过程,把x和先前输入拼接成矩阵,用公式wx+b分别计算g、i、f、o值,激活函数tanh和sigmoid。
每个时序神经网络有四个神经网络层(激活函数),最左边忘记门,直接生效到记忆C,第二个输入门,依赖输入样本数据,按照一定“比例”影响记忆C,“比例”通过第三个层(tanh)实现,取值范围是[-1,1]可以正向影响也可以负向影响,最后一个输出门,每一时序产生输出既依赖输入样本x和上一时序输出,还依赖记忆C,设计模仿生物神经元记忆功能。
def top_diff_is(self, top_diff_h, top_diff_s):
# notice that top_diff_s is carried along the constant error carousel
ds = self.state.o * top_diff_h + top_diff_s
do = self.state.s * top_diff_h
di = self.state.g * ds
dg = self.state.i * ds
df = self.s_prev * ds
# diffs w.r.t. vector inside sigma / tanh function
di_input = (1. - self.state.i) * self.state.i * di
df_input = (1. - self.state.f) * self.state.f * df
do_input = (1. - self.state.o) * self.state.o * do
dg_input = (1. - self.state.g ** 2) * dg
# diffs w.r.t. inputs
self.param.wi_diff += np.outer(di_input, self.xc)
self.param.wf_diff += np.outer(df_input, self.xc)
self.param.wo_diff += np.outer(do_input, self.xc)
self.param.wg_diff += np.outer(dg_input, self.xc)
self.param.bi_diff += di_input
self.param.bf_diff += df_input
self.param.bo_diff += do_input
self.param.bg_diff += dg_input
# compute bottom diff
dxc = np.zeros_like(self.xc)
dxc += np.dot(self.param.wi.T, di_input)
dxc += np.dot(self.param.wf.T, df_input)
dxc += np.dot(self.param.wo.T, do_input)
dxc += np.dot(self.param.wg.T, dg_input)
# save bottom diffs
self.state.bottom_diff_s = ds * self.state.f
self.state.bottom_diff_x = dxc[:self.param.x_dim]
self.state.bottom_diff_h = dxc[self.param.x_dim:]反向传导,整个训练过程核心。假设在t时刻lstm输出预测值h(t),实际输出值是y(t),之间差别是损失,假设损失函数为l(t) = f(h(t), y(t)) = ||h(t) - y(t)||^2,欧式距离,整体损失函数是L(t) = ∑l(t),t从1到T,T表示整个事件序列最大长度。最终目标是用梯度下降法让L(t)最小化,找到一个最优权重w使得L(t)最小,当w发生微小变化L(t)不再变化,达到局部最优,即L对w偏导梯度为0。
dL/dw表示当w发生单位变化L变化多少,dh(t)/dw表示当w发生单位变化h(t)变化多少,dL/dh(t)表示当h(t)发生单位变化时L变化多少,(dL/dh(t)) * (dh(t)/dw)表示第t时序第i个记忆单元w发生单位变化L变化多少,把所有由1到M的i和所有由1到T的t累加是整体dL/dw。
第i个记忆单元,h(t)发生单位变化,整个从1到T时序所有局部损失l的累加和,是dL/dh(t),h(t)只影响从t到T时序局部损失l。
假设L(t)表示从t到T损失和,L(t) = ∑l(s)。
h(t)对w导数。
L(t) = l(t) + L(t+1),dL(t)/dh(t) = dl(t)/dh(t) + dL(t+1)/dh(t),用下一时序导数得出当前时序导数,规律推导,计算T时刻导数往前推,在T时刻,dL(T)/dh(T) = dl(T)/dh(T)。
class LstmNetwork():
def __init__(self, lstm_param):
self.lstm_param = lstm_param
self.lstm_node_list = []
# input sequence
self.x_list = []
def y_list_is(self, y_list, loss_layer):
"""
Updates diffs by setting target sequence
with corresponding loss layer.
Will *NOT* update parameters. To update parameters,
call self.lstm_param.apply_diff()
"""
assert len(y_list) == len(self.x_list)
idx = len(self.x_list) - 1
# first node only gets diffs from label ...
loss = loss_layer.loss(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h = loss_layer.bottom_diff(self.lstm_node_list[idx].state.h, y_list[idx])
# here s is not affecting loss due to h(t+1), hence we set equal to zero
diff_s = np.zeros(self.lstm_param.mem_cell_ct)
self.lstm_node_list[idx].top_diff_is(diff_h, diff_s)
idx -= 1
### ... following nodes also get diffs from next nodes, hence we add diffs to diff_h
### we also propagate error along constant error carousel using diff_s
while idx >= 0:
loss += loss_layer.loss(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h = loss_layer.bottom_diff(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h += self.lstm_node_list[idx + 1].state.bottom_diff_h
diff_s = self.lstm_node_list[idx + 1].state.bottom_diff_s
self.lstm_node_list[idx].top_diff_is(diff_h, diff_s)
idx -= 1
return lossdiff_h(预测结果误差发生单位变化损失L多少,dL(t)/dh(t)数值计算),由idx从T往前遍历到1,计算loss_layer.bottom_diff和下一个时序bottom_diff_h和作为diff_h(第一次遍历即T不加bottom_diff_h)。
loss_layer.bottom_diff:
def bottom_diff(self, pred, label):
diff = np.zeros_like(pred)
diff[0] = 2 * (pred[0] - label)
return diffl(t) = f(h(t), y(t)) = ||h(t) - y(t)||^2导数l'(t) = 2 * (h(t) - y(t))
。当s(t)发生变化,L(t)变化来源s(t)影响h(t)和h(t+1),影响L(t)。
h(t+1)不会影响l(t)。
左边式子(dL(t)/dh(t)) * (dh(t)/ds(t)),由t+1到t来逐级反推dL(t)/ds(t)。
神经元self.state.h = self.state.s self.state.o,h(t) = s(t) o(t),dh(t)/ds(t) = o(t),dL(t)/dh(t)是top_diff_h。
top_diff_is,Bottom means input to the layer, top means output of the layer. Caffe also uses this terminology. bottom表示神经网络层输入,top表示神经网络层输出,和caffe概念一致。
def top_diff_is(self, top_diff_h, top_diff_s):
top_diff_h表示当前t时序dL(t)/dh(t), top_diff_s表示t+1时序记忆单元dL(t)/ds(t)。
ds = self.state.o * top_diff_h + top_diff_s
do = self.state.s * top_diff_h
di = self.state.g * ds
dg = self.state.i * ds
df = self.s_prev * ds前缀d表达误差L对某一项导数(directive)。
ds是在根据公式dL(t)/ds(t)计算当前t时序dL(t)/ds(t)。
do是计算dL(t)/do(t),h(t) = s(t) o(t),dh(t)/do(t) = s(t),dL(t)/do(t) = (dL(t)/dh(t)) (dh(t)/do(t)) = top_diff_h * s(t)。
di是计算dL(t)/di(t)。s(t) = f(t) s(t-1) + i(t) g(t)。dL(t)/di(t) = (dL(t)/ds(t)) (ds(t)/di(t)) = ds g(t)。
dg是计算dL(t)/dg(t),dL(t)/dg(t) = (dL(t)/ds(t)) (ds(t)/dg(t)) = ds i(t)。
df是计算dL(t)/df(t),dL(t)/df(t) = (dL(t)/ds(t)) (ds(t)/df(t)) = ds s(t-1)。
di_input = (1. - self.state.i) * self.state.i * di
df_input = (1. - self.state.f) * self.state.f * df
do_input = (1. - self.state.o) * self.state.o * do
dg_input = (1. - self.state.g ** 2) * dgsigmoid函数导数,tanh函数导数。di_input,(1. - self.state.i) * self.state.i,sigmoid导数,当i神经元输入发生单位变化时输出值有多大变化,再乘di表示当i神经元输入发生单位变化时误差L(t)发生多大变化,dL(t)/d i_input(t)。
self.param.wi_diff += np.outer(di_input, self.xc)
self.param.wf_diff += np.outer(df_input, self.xc)
self.param.wo_diff += np.outer(do_input, self.xc)
self.param.wg_diff += np.outer(dg_input, self.xc)
self.param.bi_diff += di_input
self.param.bf_diff += df_input
self.param.bo_diff += do_input
self.param.bg_diff += dg_inputw_diff是权重矩阵误差,b_diff是偏置误差,用于更新。
dxc = np.zeros_like(self.xc)
dxc += np.dot(self.param.wi.T, di_input)
dxc += np.dot(self.param.wf.T, df_input)
dxc += np.dot(self.param.wo.T, do_input)
dxc += np.dot(self.param.wg.T, dg_input)累加输入xdiff,x在四处起作用,四处diff加和后作xdiff。
self.state.bottom_diff_s = ds * self.state.f
self.state.bottom_diff_x = dxc[:self.param.x_dim]
self.state.bottom_diff_h = dxc[self.param.x_dim:]bottom_diff_s是在t-1时序上s变化和t时序上s变化时f倍关系。dxc是x和h横向合并矩阵,分别取两部分diff信息bottom_diff_x和bottom_diff_h。
def x_list_clear(self):
self.x_list = []
def x_list_add(self, x):
self.x_list.append(x)
if len(self.x_list) > len(self.lstm_node_list):
# need to add new lstm node, create new state mem
lstm_state = LstmState(self.lstm_param.mem_cell_ct, self.lstm_param.x_dim)
self.lstm_node_list.append(LstmNode(self.lstm_param, lstm_state))
# get index of most recent x input
idx = len(self.x_list) - 1
if idx == 0:
# no recurrent inputs yet
self.lstm_node_list[idx].bottom_data_is(x)
else:
s_prev = self.lstm_node_list[idx - 1].state.s
h_prev = self.lstm_node_list[idx - 1].state.h
self.lstm_node_list[idx].bottom_data_is(x, s_prev, h_prev)添加训练样本,输入x数据。
def example_0():
# learns to repeat simple sequence from random inputs
np.random.seed(0)
# parameters for input data dimension and lstm cell count
mem_cell_ct = 100
x_dim = 50
concat_len = x_dim + mem_cell_ct
lstm_param = LstmParam(mem_cell_ct, x_dim)
lstm_net = LstmNetwork(lstm_param)
y_list = [-0.5,0.2,0.1, -0.5]
input_val_arr = [np.random.random(x_dim) for _ in y_list]
for cur_iter in range(100):
print "cur iter: ", cur_iter
for ind in range(len(y_list)):
lstm_net.x_list_add(input_val_arr[ind])
print "y_pred[%d] : %f" % (ind, lstm_net.lstm_node_list[ind].state.h[0])
loss = lstm_net.y_list_is(y_list, ToyLossLayer)
print "loss: ", loss
lstm_param.apply_diff(lr=0.1)
lstm_net.x_list_clear()初始化LstmParam,指定记忆存储单元数为100,指定输入样本x维度是50。初始化LstmNetwork训练模型,生成4组各50个随机数,分别以[-0.5,0.2,0.1, -0.5]作为y值训练,每次喂50个随机数和一个y值,迭代100次。
lstm输入一串连续质数预估下一个质数。小测试,生成100以内质数,循环拿出50个质数序列作x,第51个质数作y,拿出10个样本参与训练1w次,均方误差由0.17973最终达到了1.05172e-06,几乎完全正确:
import numpy as np
import sys
from lstm import LstmParam, LstmNetwork
class ToyLossLayer:
"""
Computes square loss with first element of hidden layer array.
"""
@classmethod
def loss(self, pred, label):
return (pred[0] - label) ** 2
@classmethod
def bottom_diff(self, pred, label):
diff = np.zeros_like(pred)
diff[0] = 2 * (pred[0] - label)
return diff
class Primes:
def __init__(self):
self.primes = list()
for i in range(2, 100):
is_prime = True
for j in range(2, i-1):
if i % j == 0:
is_prime = False
if is_prime:
self.primes.append(i)
self.primes_count = len(self.primes)
def get_sample(self, x_dim, y_dim, index):
result = np.zeros((x_dim+y_dim))
for i in range(index, index + x_dim + y_dim):
result[i-index] = self.primes[i%self.primes_count]/100.0
return result
def example_0():
mem_cell_ct = 100
x_dim = 50
concat_len = x_dim + mem_cell_ct
lstm_param = LstmParam(mem_cell_ct, x_dim)
lstm_net = LstmNetwork(lstm_param)
primes = Primes()
x_list = []
y_list = []
for i in range(0, 10):
sample = primes.get_sample(x_dim, 1, i)
x = sample[0:x_dim]
y = sample[x_dim:x_dim+1].tolist()[0]
x_list.append(x)
y_list.append(y)
for cur_iter in range(10000):
if cur_iter % 1000 == 0:
print "y_list=", y_list
for ind in range(len(y_list)):
lstm_net.x_list_add(x_list[ind])
if cur_iter % 1000 == 0:
print "y_pred[%d] : %f" % (ind, lstm_net.lstm_node_list[ind].state.h[0])
loss = lstm_net.y_list_is(y_list, ToyLossLayer)
if cur_iter % 1000 == 0:
print "loss: ", loss
lstm_param.apply_diff(lr=0.01)
lstm_net.x_list_clear()
if __name__ == "__main__":
example_0()质数列表全都除以100,这个代码训练数据必须是小于1数值。
torch是深度学习框架。1)tensorflow,谷歌主推,时下最火,小型试验和大型计算都可以,基于python,缺点是上手相对较难,速度一般;2)torch,facebook主推,用于小型试验,开源应用较多,基于lua,上手较快,网上文档较全,缺点是lua语言相对冷门;3)mxnet,Amazon主推,主要用于大型计算,基于python和R,缺点是网上开源项目较少;4)caffe,facebook主推,用于大型计算,基于c++、python,缺点是开发不是很方便;5)theano,速度一般,基于python,评价很好。
torch github上lstm实现项目比较多。
在mac上安装torch。https://github.com/torch/torch7/wiki/Cheatsheet#installing-and-running-torch 。
git clone https://github.com/torch/distro.git ~/torch --recursive
cd ~/torch; bash install-deps;
./install.shqt安装不成功问题,自己单独安装。
brew install cartr/qt4/qt安装后需要手工加到~/.bash_profile中。
. ~/torch/install/bin/torch-activatesource ~/.bash_profile后执行th使用torch。
安装itorch,安装依赖
brew install zeromq
brew install openssl
luarocks install luacrypto OPENSSL_DIR=/usr/local/opt/openssl/
git clone https://github.com/facebook/iTorch.git
cd iTorch
luarocks make
用卷积神经网络实现图像识别。
创建pattern_recognition.lua:
require 'nn'
require 'paths'
if (not paths.filep("cifar10torchsmall.zip")) then
os.execute('wget -c https://s3.amazonaws.com/torch7/data/cifar10torchsmall.zip')
os.execute('unzip cifar10torchsmall.zip')
end
trainset = torch.load('cifar10-train.t7')
testset = torch.load('cifar10-test.t7')
classes = {'airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck'}
setmetatable(trainset,
{__index = function(t, i)
return {t.data[i], t.label[i]}
end}
);
trainset.data = trainset.data:double() -- convert the data from a ByteTensor to a DoubleTensor.
function trainset:size()
return self.data:size(1)
end
mean = {} -- store the mean, to normalize the test set in the future
stdv = {} -- store the standard-deviation for the future
for i=1,3 do -- over each image channel
mean[i] = trainset.data[{ {}, {i}, {}, {} }]:mean() -- mean estimation
print('Channel ' .. i .. ', Mean: ' .. mean[i])
trainset.data[{ {}, {i}, {}, {} }]:add(-mean[i]) -- mean subtraction
stdv[i] = trainset.data[{ {}, {i}, {}, {} }]:std() -- std estimation
print('Channel ' .. i .. ', Standard Deviation: ' .. stdv[i])
trainset.data[{ {}, {i}, {}, {} }]:div(stdv[i]) -- std scaling
end
net = nn.Sequential()
net:add(nn.SpatialConvolution(3, 6, 5, 5)) -- 3 input image channels, 6 output channels, 5x5 convolution kernel
net:add(nn.ReLU()) -- non-linearity
net:add(nn.SpatialMaxPooling(2,2,2,2)) -- A max-pooling operation that looks at 2x2 windows and finds the max.
net:add(nn.SpatialConvolution(6, 16, 5, 5))
net:add(nn.ReLU()) -- non-linearity
net:add(nn.SpatialMaxPooling(2,2,2,2))
net:add(nn.View(16*5*5)) -- reshapes from a 3D tensor of 16x5x5 into 1D tensor of 16*5*5
net:add(nn.Linear(16*5*5, 120)) -- fully connected layer (matrix multiplication between input and weights)
net:add(nn.ReLU()) -- non-linearity
net:add(nn.Linear(120, 84))
net:add(nn.ReLU()) -- non-linearity
net:add(nn.Linear(84, 10)) -- 10 is the number of outputs of the network (in this case, 10 digits)
net:add(nn.LogSoftMax()) -- converts the output to a log-probability. Useful for classification problems
criterion = nn.ClassNLLCriterion()
trainer = nn.StochasticGradient(net, criterion)
trainer.learningRate = 0.001
trainer.maxIteration = 5
trainer:train(trainset)
testset.data = testset.data:double() -- convert from Byte tensor to Double tensor
for i=1,3 do -- over each image channel
testset.data[{ {}, {i}, {}, {} }]:add(-mean[i]) -- mean subtraction
testset.data[{ {}, {i}, {}, {} }]:div(stdv[i]) -- std scaling
end
predicted = net:forward(testset.data[100])
print(classes[testset.label[100]])
print(predicted:exp())
for i=1,predicted:size(1) do
print(classes[i], predicted[i])
end
correct = 0
for i=1,10000 do
local groundtruth = testset.label[i]
local prediction = net:forward(testset.data[i])
local confidences, indices = torch.sort(prediction, true) -- true means sort in descending order
if groundtruth == indices[1] then
correct = correct + 1
end
end
print(correct, 100*correct/10000 .. ' % ')
class_performance = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0}
for i=1,10000 do
local groundtruth = testset.label[i]
local prediction = net:forward(testset.data[i])
local confidences, indices = torch.sort(prediction, true) -- true means sort in descending order
if groundtruth == indices[1] then
class_performance[groundtruth] = class_performance[groundtruth] + 1
end
end
for i=1,#classes do
print(classes[i], 100*class_performance[i]/1000 .. ' %')
end
执行th pattern_recognition.lua。
首先下载cifar10torchsmall.zip样本,有50000张训练用图片,10000张测试用图片,分别都标注,包括airplane、automobile等10种分类,对trainset绑定__index和size方法,兼容nn.Sequential使用,绑定函数看lua教程:http://tylerneylon.com/a/learn-lua/ ,trainset数据正规化,数据转成均值为1方差为1的double类型张量。初始化卷积神经网络模型,包括两层卷积、两层池化、一个全连接以及一个softmax层,进行训练,学习率为0.001,迭代5次,模型训练好后对测试机第100号图片做预测,打印出整体正确率以及每种分类准确率。https://github.com/soumith/cvpr2015/blob/master/Deep%20Learning%20with%20Torch.ipynb 。
torch可以方便支持gpu计算,需要对代码做修改。
比较流行的seq2seq基本都用lstm组成编码器解码器模型实现,开源实现大都基于one-hot embedding(没有词向量表达信息量大)。word2vec词向量 seq2seq模型,只有一个lstm单元机器人。
下载《甄环传》小说原文。上网随便百度“甄环传 txt”,下载下来,把文件转码成utf-8编码,把windows回车符都替换成n,以便后续处理。
对甄环传切词。切词工具word_segment.py到github下载,地址在https://github.com/warmheartli/ChatBotCourse/blob/master/word_segment.py 。
python ./word_segment.py zhenhuanzhuan.txt zhenhuanzhuan.segment
生成词向量。用word2vec,word2vec源码 https://github.com/warmheartli/ChatBotCourse/tree/master/word2vec 。make编译即可执行。
./word2vec -train ./zhenhuanzhuan.segment -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
生成一个vectors.bin文件,基于甄环传原文生成的词向量文件。
训练代码。
# -*- coding: utf-8 -*-
import sys
import math
import tflearn
import chardet
import numpy as np
import struct
seq = []
max_w = 50
float_size = 4
word_vector_dict = {}
def load_vectors(input):
"""从vectors.bin加载词向量,返回一个word_vector_dict的词典,key是词,value是200维的向量
"""
print "begin load vectors"
input_file = open(input, "rb")
# 获取词表数目及向量维度
words_and_size = input_file.readline()
words_and_size = words_and_size.strip()
words = long(words_and_size.split(' ')[0])
size = long(words_and_size.split(' ')[1])
print "words =", words
print "size =", size
for b in range(0, words):
a = 0
word = ''
# 读取一个词
while True:
c = input_file.read(1)
word = word + c
if False == c or c == ' ':
break
if a < max_w and c != 'n':
a = a + 1
word = word.strip()
vector = []
for index in range(0, size):
m = input_file.read(float_size)
(weight,) = struct.unpack('f', m)
vector.append(weight)
# 将词及其对应的向量存到dict中
word_vector_dict[word.decode('utf-8')] = vector
input_file.close()
print "load vectors finish"
def init_seq():
"""读取切好词的文本文件,加载全部词序列
"""
file_object = open('zhenhuanzhuan.segment', 'r')
vocab_dict = {}
while True:
line = file_object.readline()
if line:
for word in line.decode('utf-8').split(' '):
if word_vector_dict.has_key(word):
seq.append(word_vector_dict[word])
else:
break
file_object.close()
def vector_sqrtlen(vector):
len = 0
for item in vector:
len += item * item
len = math.sqrt(len)
return len
def vector_cosine(v1, v2):
if len(v1) != len(v2):
sys.exit(1)
sqrtlen1 = vector_sqrtlen(v1)
sqrtlen2 = vector_sqrtlen(v2)
value = 0
for item1, item2 in zip(v1, v2):
value += item1 * item2
return value / (sqrtlen1*sqrtlen2)
def vector2word(vector):
max_cos = -10000
match_word = ''
for word in word_vector_dict:
v = word_vector_dict[word]
cosine = vector_cosine(vector, v)
if cosine > max_cos:
max_cos = cosine
match_word = word
return (match_word, max_cos)
def main():
load_vectors("./vectors.bin")
init_seq()
xlist = []
ylist = []
test_X = None
#for i in range(len(seq)-100):
for i in range(10):
sequence = seq[i:i+20]
xlist.append(sequence)
ylist.append(seq[i+20])
if test_X is None:
test_X = np.array(sequence)
(match_word, max_cos) = vector2word(seq[i+20])
print "right answer=", match_word, max_cos
X = np.array(xlist)
Y = np.array(ylist)
net = tflearn.input_data([None, 20, 200])
net = tflearn.lstm(net, 200)
net = tflearn.fully_connected(net, 200, activation='linear')
net = tflearn.regression(net, optimizer='sgd', learning_rate=0.1,
loss='mean_square')
model = tflearn.DNN(net)
model.fit(X, Y, n_epoch=500, batch_size=10,snapshot_epoch=False,show_metric=True)
model.save("model")
predict = model.predict([test_X])
#print predict
#for v in test_X:
# print vector2word(v)
(match_word, max_cos) = vector2word(predict[0])
print "predict=", match_word, max_cos
main()
load_vectors从vectors.bin加载词向量,init_seq加载甄环传切词文本并存到一个序列里,vector2word求距离某向量最近词,模型只有一个lstm单元。
经过500个epoch训练,均方损失降到0.33673,以0.941794432002余弦相似度预测出下一个字。
强大gpu,调整参数,整篇文章都训练,修改代码predict部分,不断输出下一个字,自动吐出甄环体。基于tflearn实现,tflearn官方文档examples实现seq2seq直接调用tensorflow中的tensorflow/python/ops/seq2seq.py,基于one-hot embedding方法,一定没有词向量效果好。
参考资料:
《Python 自然语言处理》
http://www.shareditor.com/blogshow?blogId=116
http://www.shareditor.com/blogshow?blogId=117
http://www.shareditor.com/blogshow?blogId=118
欢迎推荐上海机器学习工作机会,我的微信:qingxingfengzi

![人工智能创新挑战赛:海洋气象预测Baseline[4]完整版(TensorFlow、torch版本)含数据转化、模型构建、MLP、TCNN+RNN、LSTM模型训练以及预测](https://ucc.alicdn.com/fnj5anauszhew_20230607_83592c071f9241edb19dec6aabfa5f4e.png?x-oss-process=image/resize,h_160,m_lfit)