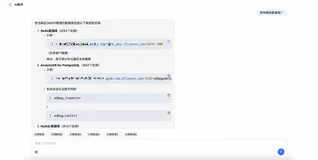
User表通常是我们在写“XX管理系统”项目时必须要用到的,有的情况下人员的分类属于树形结构,就是除了最高层和最低层,中间层都有相对的父和子,设计数据库的时候,我们通常会加一个parent_id这样的字段。这样我们就可以通过当前用户的user_id查询出他的直接下属有哪些,或者通过parent_id查询出他的直接上司是谁。
但是当我们想通过user_id去查询出其所有下属的时候,就不是能用一条简单的sql能实现的了。如果项目要是.Net Framework3.5以下的,就是没有Linq的时候,通常会在数据库里写一个函数,然后在写sql的时候直接调用函数就能得到一个筛选出来的结果集。如果是Linq呢?我想应该就是要写一个静态方法了,正好自己遇到了一个这样的问题,也是刚接触Linq,所以试着写了一下。
不过无论是在数据库中写函数还是在项目中写一个静态方法,我想都是要用到递归去实现的。
我的思路就是传入当前的user_id然后返回它的所有下属的结果集。最后在这个结果集上去根据条件查询。但是,在写这个方法的过程中还是遇到了几个问题:
1、如何将查询出来的结果集var类型,转换成List<T>类型
最开始我是这样去写的
|
1
2
3
4
|
/*大错特错*/
var
list =
from
.......
where
....
select
...;
.....
return
list.ToList<T>();
|
现在看看我还是挺有创造力的哈,居然能写出这么个东西。
首先不说list.ToList<T>();本身就画红线,为什么我要在最后 return 的时候才去ToList()呢?原因是我知道var 可以用“+=”运算符。这样递归的时候将深一层的返回值直接+到一起,用起来方便一些。
啊~真是大错特错了,首先,按照我的思路,深一层返回的值已经是ToList类型了,所以不能再用+=运算符了.其次,好吧,我承认,我还是没有太了解var是个什么东西。其实在程序运行之后,list就会有一个明确的类型,是系统去自动判定出来的。var只是使我们编程的时候更方便一些,有点像程序蜜糖(忘记是从哪听来的了),也就是说系统应该能识别出list是一个T类型对象的集合,而我这么写就有点画蛇添足的意味了。
正解:
|
1
2
3
|
var
list = (
from
.......
where
....
select
...).ToList();
.....
return
list;
|
这样,list 就会变成我想要的List<T>类型了,因为函数的返回值就是这个类型,所以正是我想要的。
2、提示报错:Collection was modified; enumeration operation may not execute.
这个错误的原因是因为用foreach遍历的时候,对Collection(这里的temp)这个数据集进行了Add/Remove操作。这样就有可能在未遍历到最后的时候,就把这个Collection给修改了,随之就报错了。解决办法有说用for代替foreach的,但是我还是觉得foreach要好些,所以创建了一个Collection这个结果集副本,然后一个用作遍历,一个用作Add/Remove操作,当然,返回的是用后者。
注意创建副本的时候一定新new一个对象,而不是直接声明之后赋值,否则跟没写一样。
|
1
2
3
|
List<T> tmpList = list;
//错误
List<T> tmpList =
new
List<T>(list);
//正确
|
最后完整的代码为:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
contextdata ctdt =
new
contextdata();
public
static
List<db_userinfo> findallchildren(
int
parentid)
{
var
list = (
from
c
in
ctdt.db_userinfo
where
c.parent_id == parentid
select
c).ToList();
List<db_userinfo> tmpList =
new
List<db_userinfo>(list);
foreach
(db_userinfo single
in
temp)
{
List<db_userinfo> tmpChildren = findallchildren(single.user_id);
if
(tmpChildren.Count != 0)
{
list.AddRange(tmpChildren);
}
}
return
list;
}
|
这样,在页面的后台代码.cs文件中,就可以直接把这个方法的返回值作为条件查询中基础数据集。如
|
1
|
var
result =
from
c
in
findallchildren(userid)
where
.....
select
....;
|
应该还有更好的方法,希望比较懂的朋友能多传授一下,欢迎盖楼!~