
一、什么是epub
epub是一个完全开放和免费的电子书标准。它可以“自动重新编排”的内容。
Epub文件后缀名:.epub
二、 epub组成
Epub内部使用XHTML(或者DTBook)来展现文件的内容;用一系列css来定义格式和版面设计; 然后把所有的文件压缩成zip包。
Epub格式中包含了DRM相关功能(目前epub引擎暂时不考虑drm相关信息)
EPub包括三项主要规格:
开放出版结构(Open Publication Structure,OPS)2.0,以定义内容的版面;
开放包裹格式(Open Packaging Format,OPF)2.0,定义以XML为基础的.epub档案结构; OEBPS容纳格式(OEBPS Container Format,OCF)1.0,将所有相关文件收集至ZIP压缩档案之中。
1. OPS:
用XHTML(或者DTBook)来构筑书的内容。
用一系列css来定义书的格式和版面设计。
支持 png、jpeg、gif、svg的图片格式。
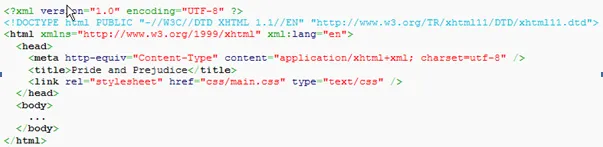
2. OPF:
OPF 文件是 EPUB 规范中最复杂的元数据。它用来定义ops一系列内容组合到一起的机制,并为ebook提供了一些额外的结构和内容。Opf包含四个子元素:metadata, manifest, spine, guide。在OEBPS中的opf包含两个XML: .opf和.ncx

(一).opf
OPF包括以下内容:
1)metadata:epub的元数据,如title、language、identifier、cover等。其中,title 和 identifier这两个数据是必须的。
按照EPUB规范,identifier由数字图书的创建者定义,必须唯一。对于图书出版商来说,这个字段一般包括ISBN或者Library of Congress编号;也可以使用URL或者随机生成的唯一用户ID。注意:unique-identifier 的值必须和 dc:identifier 元素的 ID 属性匹配。

2)manifest:列出了package中所包含的所有文件(xhtml、css、png、ncx等)。EPUB 鼓励使用 CSS 设定图书内容的样式,因此 manifest 中也包含 CSS。注意:进入数字图书的所有文件都必须在 manifest 中列出。
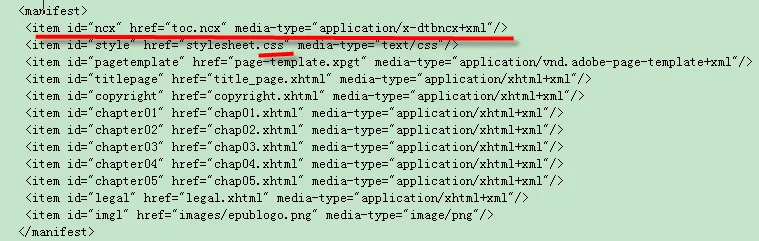
3)spine:所有xhtml文档的线性阅读顺序。其中,spine的TOC属性必须包含在manifest列出来的.ncx的id。可以将 OPF spine 理解为是书中 “页面” 的顺序,解析的时候按照文档顺序从上到下依次读取 spine。
在spine中的每个 itemref 元素都需要有一个 idref 属性,这个属性和 manifest 中的某个 ID 匹配。
spine 中的 linear 属性表明该项是作为线性阅读顺序中的一项,还是和先后次序无关。有些阅读器可以将spine中linear=no的项作为辅助选项处理,有些阅读器则选择忽略这个属性。例如在下边的实例中,支持辅助选项处理的阅读器会依次列出titlepage、chapter01、chapter05,chapter02、chapter03、chapter04只在点击到(或者其他开启动作)之后才会显示。
但是对于支持打印的阅读器,需要忽略linear=no的属性,保证能够最完全的展示ops中的内容。
好的阅读器需要同时提供两种选择给用户。

(二).ncx
NCX 定义了数字图书的目录表。复杂的图书中,目录表通常采用层次结构,包括嵌套的内容、章和节。包含了TOC(tablet of content,提供了分段的一些信息)。
NCX的
标记中包含四个 meta 元素:- uid: 数字图书的惟一 ID。该元素应该和 OPF 文件中的 dc:identifier 对应。
- depth:反映目录表中层次的深度。
- totalPageCount 和 maxPageNumber:仅用于纸质图书,保留 0 即可。
docTitle/text 的内容是图书的标题,和 OPF 中的 dc:title 匹配。
navMap 是 NCX 文件中最重要的部分,定义了图书的目录。navMap 包含一个或多个 navPoint 元素,每个 navPoint 都要包含下列元素:
- playOrder:说明文档的阅读顺序。和 OPF spine 中 itemref 元素的顺序相同。
- navLabel/text :给出该章节的标题。通常是章的标题或者数字。
- content :它的 src 属性指向包含这些内容的物理资源。就是 OPF manifest 中声明的文件。
- 还可以有一个或多个 navPoint 元素。NCX 使用嵌套的导航点表示层次结构的文档

(三)NCX 和 OPF spine 有什么不同?
两者很容易混淆,因为两个文件都描述了文档的顺序和内容。要说明两者的区别,最简单的办法就是拿印刷书来打比方:OPF spine 描述了书中的各个章节是如何实际连接起来的,比方说翻过第一章的最后一页就看到第二章的第一页。NCX 在图书的一开始描述了目录,目录肯定会包含书中主要的章节,但是还可能包含没有单独分页的小节。
一条法则是 NCX 包含的 navPoint 元素通常比 OPF spine 中的 itemref 元素多。实际上,spine 中的所有项都会出现在 NCX 中,但 NCX 可能更详细。
3. OCF:
OCF定义了文件是如何被打包成ZIP的,并且有两个额外的信息:
1)ASCII格式的mimetype文件。该文件必须包含application/epub+zip字符串,并且是ZIP压缩包的第一个文件。Mimetype要求是非压缩格式。
2)一个命名为META-INF的文件夹。这个文件夹中需要包含container.xml文件
4. Drm——需要在META-INF文件夹中包含rights.xml
总结起来,一个epub电子书的zip包含以下东西:
1、mimetype 文件,必须是压缩包的第一个文件。注意,Mimetype必须是非压缩格式。
2、meta-inf目录,里面至少包含一个container.xml 文件。
3、OEBPS目录(可以是别的名字,但建议用这个名字),包含了:
a) image子目录(不一定总有)存放了所有的图片文件
b) content.opf 文件名可以是其它的,扩展名一定是opf,就是一个xml格式的包内的文件列表
c) toc.ncx 目录文件,一个“逻辑目录”, 浏览控制文件.
d) 一些xhtml或html文件。就是书的内容。
简单 EPUB 档案的目录和文件结构:
mimetype
META-INF/
container.xml
OEBPS/
content.opf
title.html
content.html
stylesheet.css
toc.ncx
images/
cover.png

三、Epub电子图书获取网站
Feedbooks: http://www.feedbooks.com/books/top?range=month
掌上书苑: http://www.cnepub.com/index
COAY: http://www.coay.com
博酷网: http://www.pockoo.com/books/?format=EPUB&orderby=lastedit
新浪ipad数码资源 http://myphoto.tech.sina.com.cn/forumdisplay.php?fid=398
EpubBooks: http://www.epubbooks.com/books
四、Epub电子图书阅读器(比较软件)
Adobe digital Edition: http://www.adobe.com/products/digitaleditions/
Calibre: 开放源代码的电子书管理工具,支持windows、linux、osx等平台。也能在各种格式之间转换。http://calibre-ebook.com/
Aldiko:android上的epub阅读器。 http://www.aldiko.com/
五、 Epub电子图书编辑软件
epubBuilder:epubbuilder是国人自做软件,手工制作时还是很好用的,尤其是每个章节的制作和目录,比较方便,还提供了导入chm,txt,html文件的功能,比较人性化
l Calibre
l Stanza
l Web2FB2
六、创建一个EPUB文件
参考资料:http://www.ibm.com/developerworks/cn/xml/tutorials/x-epubtut/section3.html
1. 先建一个空的zip文件,可以取为任何名字,最好和你的书同名。
2、拷贝mimetype文件到包内,注意所谓拷贝,就是这个文件不要用压缩模式。
3、把其它的目录和文件用压缩模式放入zip包。
4、改文件扩展名为.epub
ok!一本epub电子书就制成了。
七、完整的EPUB规范
OPF规范:http://www.idpf.org/2007/opf/OPF_2.0_final_spec.html
OPS规范:http://www.idpf.org/2007/ops/OPS_2.0_final_spec.html
OEBPS规范:http://www.idpf.org/ocf/ocf1.0/download/ocf10.htm
本文转自Work Hard Work Smart博客园博客,原文链接:http://www.cnblogs.com/linlf03/archive/2011/12/13/2286218.html,如需转载请自行联系原作者


