互联网安全公司 Imperva Incapsula 公布的《2016年机器流量报告》(Bot Traffic Report 2016)显示恶意 bot 流量( bot :即“机器人”流量,即自动化程序流量)占整体网络流量的比例高达 28.9% 。
恶意 bot 流量造成的业务网站平台服务不可用、用户体验降低、网站漏洞安全问题、业务故障等问题,导致企业数据被爬、接口被刷、CC攻击导致服务不可用等,给企业带来极高的风险及难以估计的损失。
那么为了保障网站平台的正常运行,企业要如何防御恶意 bot 流量?
一.运营人员采用的方案
作为一个网站的运营技术人员,当网站受到恶意 bot 的攻击时,例如爬虫或者扫描类行为,一般有以下 2 种解决方法:
查看请求日志,如 apache 的 access 日志,人工扫描分析日志内容并发现异常,可识别出恶意 bot 。

限制源 IP 的请求速度。方案简单,但对阈值的设置要求很高,不适用于以下 4 种场景:
1)秒杀、抢购等业务导致的瞬间请求激增;
2)代理模式,如大多数高校机构以及手机运营商的网关;
3)存在大量的资源文件的页面,会导致请求该页面时的关联请求激增;
4)复杂业务本身会提供一些接口给其他服务,速率方面的浮动范围很大;
因此在没有理想阈值的条件下,限制源 IP 请求速度会导致较高的误报率,相比恶意 bot 带来的危害,高误报引起的后果对企业而言或许更加严重。
钓鱼。正常的 bot 会请求 robots.txt 文件,然后遵循 robots.txt 描述进行后续的 bot 行为(robots.txt是一种君子协议,对允许和不允许 bot 访问的内容进行标记)。借用此机制,如果在robots.txt中将一个不存在的url标注为拒绝,然后在网页中,内嵌这个隐藏的url连接,隐藏意味着human不会点击到这个连接,但是恶意的bot有很大概率会访问。事情变得简单很多,只需要在日志里过滤访问这个url的ip即可。但是这种防御方法仅能对抗低级的恶意bot,攻击者绕过此检测机制,仅需一行代码控制bot不请求上面提到的那个url即可。
IP 白名单。攻击者一般会将 ua 伪造成正常的搜索引擎的 ua 或者普通的浏览器的 ua 。白名单机制对前面一种伪造方式有效果。建立起一套 ua 和 ip 的白名单库,即可识别出伪造的ua。但是成本会提高很多,需要维护ua和ip的白名单库。而且对第二种伪造的普通的ua无效。
优点:成本低廉,操作简单,能抵御绝大多数低级的恶意 bot 。
缺点:适用性较差。
二.技术人员采用的方案:
作为技术人员,采用的方法则多依赖技术特征的局限性生效,一般有以下 5 种技术解决方案:
1. cookie支持
bot 是一个网络程序,如果这个程序写的简单,它往往不支持cookie,但 cookie 是浏览器支持的特性。利用这个特性可以通过在服务端写入 cookie ,然后检查请求所带来的 cookie 的方式来查证是否是 bot,但由于让 bot 支持 cookie 的时间成本很低,所以这个方法的效果比较有限。
2. JavaScript支持
由于 cookie 门槛低,所以大家想到的就是浏览器支持的 js 技术。如果一个普通的 bot 程序支持 js ,问题则会复杂很多,但也可以实现。
3. 设备指纹技术(浏览器指纹)
设备指纹技术会计算关于浏览器的 50+ 以上属性参数的 hash 值,甚至更高级的收集客户端的动作,比如鼠标点击信息、返回等。近期流行的画布 (canvas) 指纹技术,基本含义就是调用设备接口生成一个复杂定义的图像,由于硬件配置、软件版本等因素的影响,生成的图像在像素级别存在一定区别,以此可作为一种指纹。

bot 支持 js ,但不是浏览器,或者 bot 的 ua 和指纹不匹配,这种都很容易识别。但对于一些高级的 bot ,这个方案也有局限性:
1. 很多 bot 作为浏览器插件方式工作,或者通过修改浏览器而实现,因此同样会返回正确的设备指纹来伪造成一个真实的浏览器或者移动终端;
2. bot 篡改指纹信息返回,服务器端无法校验指纹信息的伪造性。这种机制很容易被开发 bot 的团队绕过,因为目前 ssl 体系主要用的是服务器的身份校验,绝大多数网站还没使用 https ,如果引入非对称体系的加密通信,或客户端的身份校验,在现阶段还无法实现。当然,如果有一天客户端身份都能被验证,安全问题就简单多了;很多公司拥有专门的爬虫团队和反爬虫团队,用于爬取竞争对手数据和反竞争对手爬自己的数据;
3. 设备指纹冲突概率较高,代理机器很多是云主机或者其他方式统一装机的机器。完全相同的硬件,操作系统版本,软件版本导致算出来的指纹是一样的,因此会使得误报率增高。
4. 行为分析技术
上面提到,bot 会使用浏览器插件模拟人的请求行为,例如鼠标的点击等,单纯的判断鼠标是否点击不足以判断恶意 bot 。恶意 bot 最终都会请求 web 服务。恶意表现的是在“行为”上,行为是一个抽象概念,因此难度也很高。
恶意 bot 访问目标的 url 资源,以及它提交的这些参数构成本质上的“恶意行为”,上面提到的很多恶意 bot 的技术都是为此目标服务的。越来越多的移动终端,对服务请求的表现本身就已经不是浏览器行为,如果不使用行为分析技术,这些都会触发误报。
行为分析技术一般都是安全类公司的实现方案,具体方案上存在一定区别。有简单分析客户点击节奏、时间等属性的,也有比较复杂的学习模型。作为乙方公司,一般难以实现到行为分析模型这个级别,主要是成本和技术上的考量。
5. IP 情报技术
IP 情报的价值在于一个简单的道理:正常的 IP(客户端)在相近时间范围内表现出的活动多为正常的,异常的 IP 则相反。例如被用来发起 ddos 攻击或者 cc 攻击的代理或者肉鸡,并不会只发起一次攻击,而是会长期的到处发起攻击。
国内方面,微步在线作为一个威胁情报提供商。 IP 威胁情报多作为辅助技术使用,而且很方便, 对于发现的潜在威胁,结合 IP 情报信息使判断更准确。对于网络恶意 bot 而言,攻击方几乎都是使用代理或者肉鸡来请求数据,情报的价值是非常有用的。
攻击方使用自己关联的 IP ,容易被追踪而导致法律起诉的问题,目前依据国内法律和此方面的起诉经验,爬数据这类能够胜诉需要被爬方保留足够的证据外加一些运气成分。
三.解决方案
1. 行为分析技术
“行为”是有时间维度上属性的,发生的行为是一系列动作在时间维度上的偏序关系,动作是客户端发起的请求的抽象。行为分析模型首先会动态追踪活动的会话,模型会智能的选择合适的检测时机触发评估逻辑。
例如一个爬虫 bot ,不论它做深度优先还是广度优先的遍历,或者改进的针对特定模式 url 的爬虫时,不论它访问频率是高是低,请求资源表现出的偏序关系是异常的。这种偏序关系里即包含了“异常”的来源。

将访问的 url 看成随机变量,大家知道 http referer 表示当前页面是从哪个页面链接过来的。因此直观上,url 的转换是一阶马尔科夫过程。也可以当做多阶马尔科夫过程,本质上是多阶马尔科夫过程,但是为了简单化,一阶也足够。
形象化描述就是比如一个购物网站,用户访问的路径可能为先登录,或者不登录直接进入主页搜索商品,或者逛街一样的浏览首页上的商品,查看类似商品选择购买或者不购买,最后退出。这就是一个合理的访问。假如一个访问一直在访问某类商品的价格,它是一个不合理的访问。如何度量这种合理和不合理呢? 隐马尔科夫的预测问题即可描述。
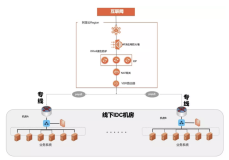
隐马尔科夫原理图示:
url 通过抽象泛化为标识,如果不泛化会导致观测状态数量巨大,降低模型速度同时也会导致过拟合。隐马尔科夫的学习过程是无监督的,极大的方便了行为模型基线的建立,此学习过程是随着时间持续进行的。
在学习过程中,有异常数据混入怎么办?其实这并不影响基线数据的建立,基线最终的阈值可以使用数学方法进行去除异常点。正常的东西总是很相近,但是异常的东西之间存在很大差异,模型基线的建立是允许有噪音数据的。模型用于异常检测,并不是直接输出 bot 的标识,后续还有异常的分类识别。
行为分析采取的技术可不限于隐马尔科夫模型,例如贝叶斯网络,马尔科夫随机场这种学习的概率模型都可以完成这个任务。概率模型的一个巨大优势是计算性能高,可以将识别过程实时化处理。
2. 创新的信息熵检测机制
信息熵可以用来衡量离散随机事件的出现概率。对于网络资源的访问,这里被当成一个离散事件。网络 bot 请求资源时,时间间隔上存在不同:人是依据主观需求对目标资源进行点击触发,而 bot 是程序设定好的,例如间隔多久,或者伪造随机时间触发等。
人在请求资源的时候,下一个请求和上一个请求是否存在关联?答案是肯定的,因为正常的人不会随机乱请求 url 资源。因此这也会导致时间间隔随机变量和上一个值也是存在关联性。本质上,至少是一阶马尔科夫过程。如果认为当前的请求和前面的多个请求都有关系,那就是多阶马尔科夫过程。
这里,我们用创新的信息熵算法来检测会话的异常值度量。如果攻击者 bot 使用伪随机的时间间隔发起请求,该算法还能检测出来么?答案是的。大家可能疑惑,随机请求肯定会导致熵的增加,代表着系统的规律信息的减少。但是我们的熵算法也是会学习进化的,同样能检测出这种 bot 的请求。请看下面测试数据:

左图是检测出的恶意 bot 的会话的熵值,右图是正常人访问的熵值,纵坐标表示熵值,横坐标是迭代次数。很容易区分这两者的区别。不仅在值上区别明显,而且模式上也有很显著的区分度。重点说明,左图下面的 3 条线分别对应着完全随机 bot 30s/20s/10s 随机的时间间隔发起请求的熵值,算法取得了很好的效果。(涉及技术算法保密性问题,这里不透露具体实现细节)
攻击者需要绕过这两种检测方法比较困难。极大的提高 bot 的成本,也是 bot 检测的目标之一。

X 轴是时间,Y 轴是访问的 url 的抽象标识
接下来就是识别 bot 是正常的还是恶意的。对于bot行为的细分,涉及到一些领域知识的结合。例如爬虫的行为和 cc 的行为有明显的区别,这属于分类器的问题,这里就不全部介绍了。 对于爬虫行为,UCloud 使用的 IP 情报中心识别出正常的 bot 。你可以对识别结果进行标记,bot 的检测不存在绝对的正确,例如很多人使用的网站的监控工具,识别出来,可能会被分类为监控,但是如果你自己的配置不正确,监控请求量非常高,可能会被标记为异常结果。
随着机器技术在图像识别方面的成功应用,这类接口的bot自动完成也成为可能。分类器还可以智能的识别出注册,登录,验证码,手机短信等等这类敏感接口的异常访问,及时告知客户此类安全风险。
3. ip威胁情报技术

四.结束语
本文综合介绍了在保障网站平台正常运行时,企业的运营和技术人员通常会采用的一些恶意 bot 流量防御方案。