
概率性 · 黑盒性 · 非确定性 · 从功能验证到质量评估
在传统软件测试中,有一个几乎不被质疑的逻辑:
输入确定 → 输出确定 → 断言成立。
但当测试对象变成大模型系统、RAG 应用、Agent 系统时——
这个逻辑开始松动。
问题不是断言错了。
问题是:
系统本身已经不是“确定性系统”。
测试工程正在经历一次结构性变革。
目录
AI 系统测试为什么是一个新问题
传统软件测试的确定性结构
AI 系统的结构性差异
断言思维为何天然失效
AI 系统的三大核心特征
大模型系统的测试分层模型
AI 测试的评测指标体系
从功能测试到概率系统评估
- AI 系统测试为什么是一个新问题
当前企业系统越来越多接入:
大模型能力
RAG 知识检索
Agent 决策逻辑
MCP 工具调用
测试对象已经不再是单一规则系统。
而是:
规则系统 + 概率模型 + 检索系统 + 工具执行链路。
测试复杂度不是线性增加,而是结构升级。
- 传统软件测试的确定性结构
传统系统的结构非常清晰:
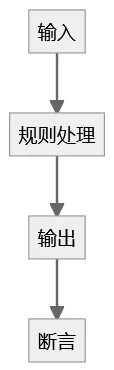
特征:
输入结构化
规则可追溯
输出可预测
断言明确
测试人员的核心能力:
验证规则是否正确实现。
- AI 系统的结构性差异
AI 系统结构更接近:
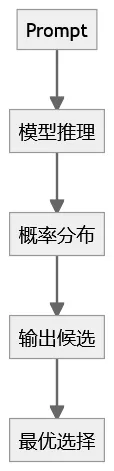
区别在于:
输出来自概率分布
同样输入可能多种结果
推理路径不可解释
这不是异常,这是设计本身。
- 断言思维为何天然失效
在传统系统中:
assert actual == expected
在大模型系统中:
expected 可能不是唯一。
例如:
输入:“写一首唐诗。”
测试难点:
内容是否符合唐诗体裁?
是否押韵?
是否符合平仄?
是否真实存在?
断言逻辑不再是“等于判断”。
而是:
质量判断。
这就是结构变化带来的根本影响。
- AI 系统的三大核心特征
1)概率性
模型输出是概率分布中的一个结果。
多次运行可能不同。
2)黑盒性
内部决策路径不可解释。
测试只能基于输入输出分析。
3)非确定性
相同输入,在不同温度、不同上下文下可能产生不同输出。
这三个特征直接打破传统测试假设。
- 大模型系统的测试分层模型
如果从工程视角看,AI 系统测试可以分三层。
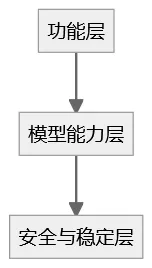
第一层:功能层
接口是否可用
参数是否传递正确
工具调用是否成功
这一层仍然可以用传统方法测试。
第二层:模型能力层
意图识别准确率
语义理解正确率
RAG 检索命中率
幻觉率统计
这一层必须引入数据集测试。
第三层:安全与稳定层
Prompt 注入测试
越权访问测试
长上下文稳定性
输出合规性
这一层属于 AI 专项测试。
- AI 测试的评测指标体系
如果没有指标,只是体验式测试。
建议至少建立:
准确率(Accuracy)
一致率(Consistency Rate)
幻觉率(Hallucination Rate)
意图识别成功率
RAG 命中率
输出稳定波动率
示意:
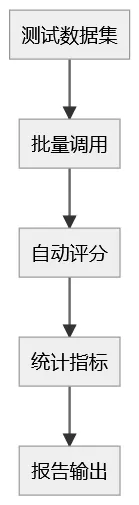
AI 测试的核心不是单次执行。
而是统计。
- 从功能测试到概率系统评估
传统测试工程关注:
规则正确性。
AI 测试工程关注:
概率系统质量。
测试角色从:
断言编写者
转变为:
评测体系设计者。
这意味着测试工程的能力重心改变:
数据集构建能力
评测框架设计能力
指标建模能力
风险识别能力
这不是工具升级。
这是思维升级。
结语
大模型时代,断言没有消失。
它只是从“相等判断”变成“质量评估”。
测试对象从规则系统变为概率系统。
如果测试方法不升级, 测试结论就会失真。
未来真正有竞争力的测试工程师,不是最会写断言的人。
而是:
最理解概率系统结构的人。
