
1、加密算法
1.1【问】请介绍一下你知道的加密算法
参考回答:
一般分类如下
- 对称加密
- 非对称加密
- 哈希摘要
- 电子签名
- 密码存储
其中
- 对称加密常见的有:DES、AES 等,国家标准有 SM4
- 非对称加密常见的有:RSA,ECDSA 等,国家标准有 SM2
- 哈希摘要有:MD5、SHA-2、SHA-3 等,国家标准有 SM3
- 电子签名有:通常会结合 RSA、ECDSA 和哈希摘要完成签名,或者是 HMAC
- 密码存储:直接使用哈希摘要作为密码存储、加盐存储、BCrypt
1.2【追问】解释对称加密、非对称加密、哈希摘要
- 对称加密
- 加密和解密的密钥使用同一个
- 因为密钥只有一个,所以密钥需要妥善保管
- 加解密速度快
- 非对称加密
- 密钥分成公钥、私钥,其中公钥用来加密、私钥用来解密
- 只需将私钥妥善保管,公钥可以对外公开
- 如果是双向通信保证传输数据安全,需要双方各产生一对密钥
- A 把 A公钥 给 B,B 把 B公钥 给 A,他们各自持有自己的私钥和对方的公钥
- A 要发消息给 B,用 B公钥 加密数据后传输,B 收到后用 B私钥 解密数据
- 类似的 B 要发消息给 A,用 A公钥 加密数据后传输,A 收到后用 A私钥 解密数据
- 相对对称加密、加解密速度慢
- 哈希摘要,摘要就是将原始数据的特征提取出来,它能够代表原始数据,可以用作数据的完整性校验
- 举个例子,张三对应着完整数据
- 描述张三时,会用它的特征来描述:他名叫张三、男性、30多岁、秃顶、从事 java 开发、年薪百万,这些特征就对应着哈希摘要,以后拿到这段描述,就知道是在说张三这个人
- 为什么说摘要能区分不同数据呢,看这段描述:还是名叫张三、男性、30多岁、秃顶、从事 java 开发、月薪八千,有一个特征不符吧,这时可以断定,此张三非彼张三
1.3【追问】解释签名算法
电子签名,主要用于防止数据被篡改。
先思考一下单纯用摘要算法能否防篡改?例如

- 发送者想把一段消息发给接收者
- 中途 message 被坏人改成了 massage(摘要没改)
- 但由于发送者同时发送了消息的摘要,一旦接收者验证摘要,就可以发现消息被改过了
坏人开始冒坏水

- 但摘要算法都其实都是公开的(例如 SHA-256),坏人也能用相同的摘要算法
- 一旦这回把摘要也一起改了发给接收者,接收者就发现不了
怎么解决?

- 发送者这回把消息连同一个密钥一起做摘要运算,密钥在发送者本地不随网络传输
- 坏人不知道密钥是什么,自然无法伪造摘要
- 密钥也可以是两把:公钥和私钥。私钥留给发送方签名,公钥给接收方验证签名,参考下图
- 注意:验签和加密是用对方公钥,签名和解密是用自己私钥。不要弄混

1.4【追问】你们项目中密码如何存储?
- 首先,明文肯定是不行的
- 第二,单纯使用 MD5、SHA-2 将密码摘要后存储也不行,简单密码很容易被彩虹表攻击,例如
- 攻击者可以把常用密码和它们的 MD5 摘要结果放在被称作【彩虹表】的表里,反查就能查到原始密码
加密结果 |
原始密码 |
e10adc3949ba59abbe56e057f20f883e |
123456 |
e80b5017098950fc58aad83c8c14978e |
abcdef |
... |
... |
因此
- 要么提示用户输入足够强度的密码,增加破解难度
- 要么我们帮用户增加密码的复杂度,增加破解难度
- 可以在用户简单密码基础上加上一段盐值,让密码变得复杂
- 可以进行多次迭代哈希摘要运算,而不是一次摘要运算
- 还有一种办法就是用 BCrypt,它不仅采用了多次迭代和加盐,还可以控制成本因子来增加哈希运算量,让攻击者知难而退
1.5【追问】比较一下 DES、AES、SM4
它们都是对称加密算法
- DES(数据加密标准)使用56位密钥,已经不推荐使用
- AES(高级加密标准)支持 128、192、256位密钥长度,在全球范围内广泛使用
- SM4(国家商用密码算法)支持 128位密钥,在中国范围内使用
1.6【追问】比较一下 RSA、ECDSA 和 SM2
它们都是非对称加密算法
- RSA 的密钥长度通常为 1024~4096,而 SM2 的密钥长度是 256
- SM2 密钥长度不需要那么长,是因为它底层依赖的是椭圆曲线、离散对数,反过来 RSA 底层依赖的是大数分解,前者在相同安全级别下有更快的运算效率
- SM2 是中国国家密码算法,在国内受政策支持和推广
- ECDSA 与 SM2 实现原理类似
2、排序
2.1 【问】请介绍一下你知道的排序算法有哪些
初级答法
常见的排序算法有:冒泡排序、选择排序、插入排序、快速排序、归并排序、堆排序等
P.S.
- 适合对以上排序算法一知半解,不太自信的同学,所谓言多必失,回答基本的就行
- 但要对接下来【各种排序的时间复杂度】的追问做到心中有数,这个必须背一背(参考后面的表格)
进阶答法
排序算法大致可分为两类:
- A. 基于比较的排序算法
- B. 非比较排序算法
比较排序算法有:快排、归并、堆排序、插入排序等
非比较排序算法有:计数排序、桶排序、基数排序等
比较排序算法中
- 快排、归并、堆排序能够达到 $$O(n \cdot \log{n})$$的(平均)时间复杂度
- 而插入排序的(平均)时间复杂度是 $$O(n^2$$
- 但并不是说复杂度高的算法就差,这要看数据规模和数据有序度,例如
- 数据量小,或是有序度高的数据就适合用插入排序
- 同样是数据量大的数据排序,如果数据的有序度高,归并优于快排
- 快排虽然是比较排序中最快的算法,但若是分区选取不好,反而会让排序效率降低
- 工业级的排序都是混合多种排序算法,例如 java 排序的实现就是混合了插入、归并与快排,不同的数据规模、不同场景下切换不同的排序算法
至于计数、桶、基数可以达到进一步让时间复杂度降至$$O(n$$,当然这与被排序数字的位数、范围等都有关系,您想知道的话,咱们可以细聊。
P.S.
- 适合对这些排序算法非常熟悉的同学,这时应注重回答的条理性
- 首先,对算法进行简单分类,让答案更为清晰
- 其次,不要等面试官来继续追问,而是主动回答各个算法的时间复杂度和适用场景,体现你对它们的熟悉
- 第三,一定要对各个算法的细节有充分准备,否则问到答不出来就尴尬了,这时不如降级为【初级答法】
2.2【问】请说说 XX 算法最好、平均、最差时间复杂度、是否稳定 ...
此时的回答参考下面两张表
表A 比较排序算法
算法 |
最好 |
最坏 |
平均 |
空间 |
稳定 |
思想 |
注意事项 |
冒泡 |
n |
n^2 |
n^2 |
1 |
是 |
比较 |
数据有序,就能达到最好情况 |
选择 |
n^2 |
n^2 |
n^2 |
1 |
否 |
选择 |
交换次数一般少于冒泡 |
堆 |
n * log n |
n * log n |
n * log n |
1 |
否 |
选择 |
|
插入 |
n |
n^2 |
n^2 |
1 |
是 |
比较 |
数据有序,就能达到最好情况 |
希尔 |
n * log n |
|
|
1 |
否 |
插入 |
有多种步长序列,它们的时间复杂度略有差异 |
归并 |
n * log n |
n * log n |
n * log n |
n |
是 |
分治 |
|
快速 |
n * log n |
n^2 |
n * log n |
log n |
否 |
分治 |
快排通常用递归实现,空间复杂度中的 $$\log{n}$$ 就是递归栈所花费的额外空间 |


表B 非比较排序算法
计数排序
- 平均时间复杂度:O(n+r),其中 r 是数字的范围
- 空间复杂度: O(n+r)
桶排序
- 最糟时间复杂度:所有数字放入一个桶,此时又变成了一个桶内的比较排序,时间复杂度取决于桶内排序算法
- 平均时间复杂度:
 ,若桶的个数 k ≈ n,则可以认为整体时间复杂度为 O(n)
,若桶的个数 k ≈ n,则可以认为整体时间复杂度为 O(n) - 空间复杂度:O(n+k)
基数排序
- 一般配合桶排序实现,因此也会涉及到桶个数 k
- 平均时间复杂度:
 ,其中 w 是待排序数字的位数
,其中 w 是待排序数字的位数 - 空间复杂度:与桶排序空间复杂度相同,每次按位排序时,桶可以重用
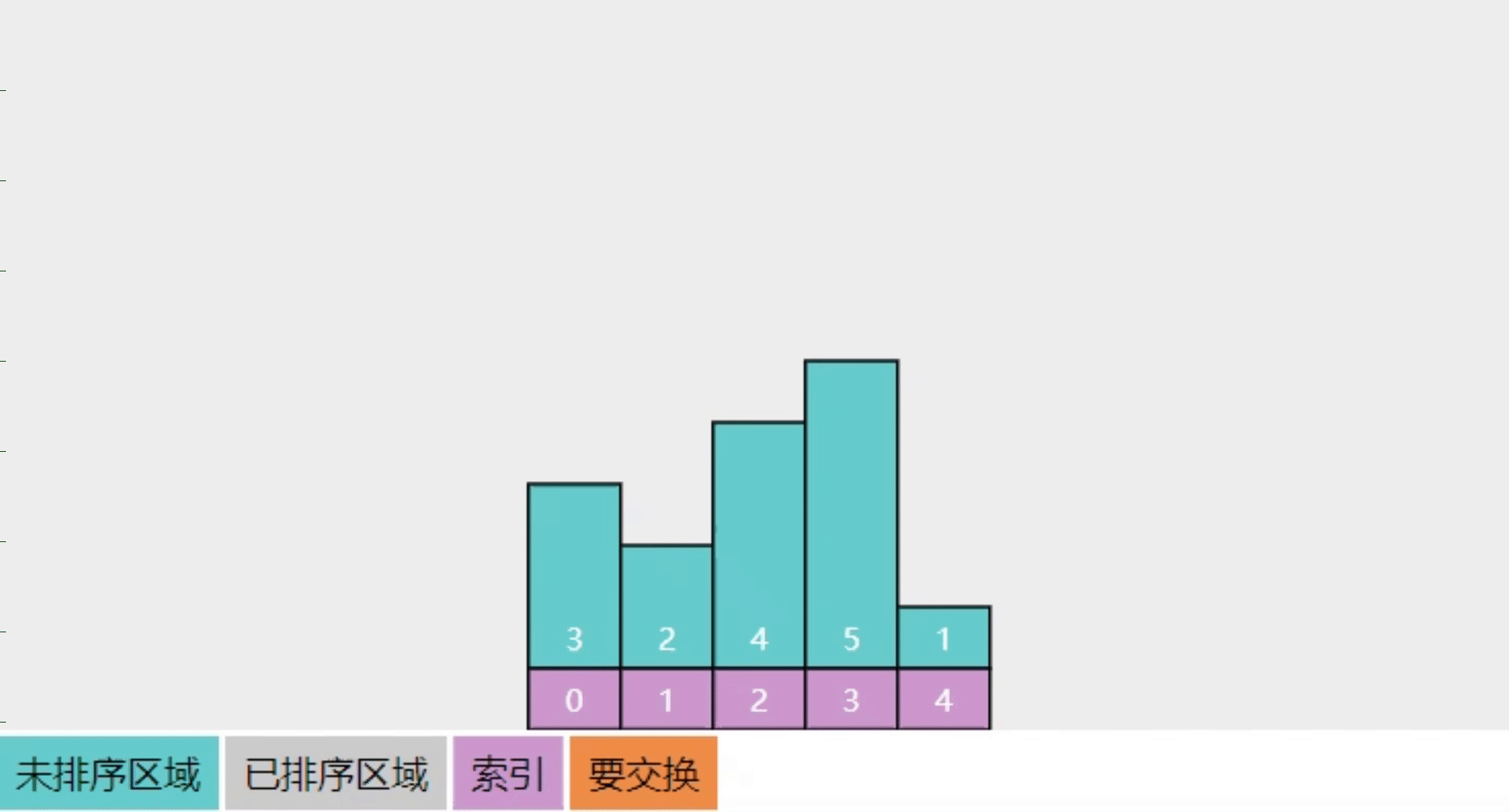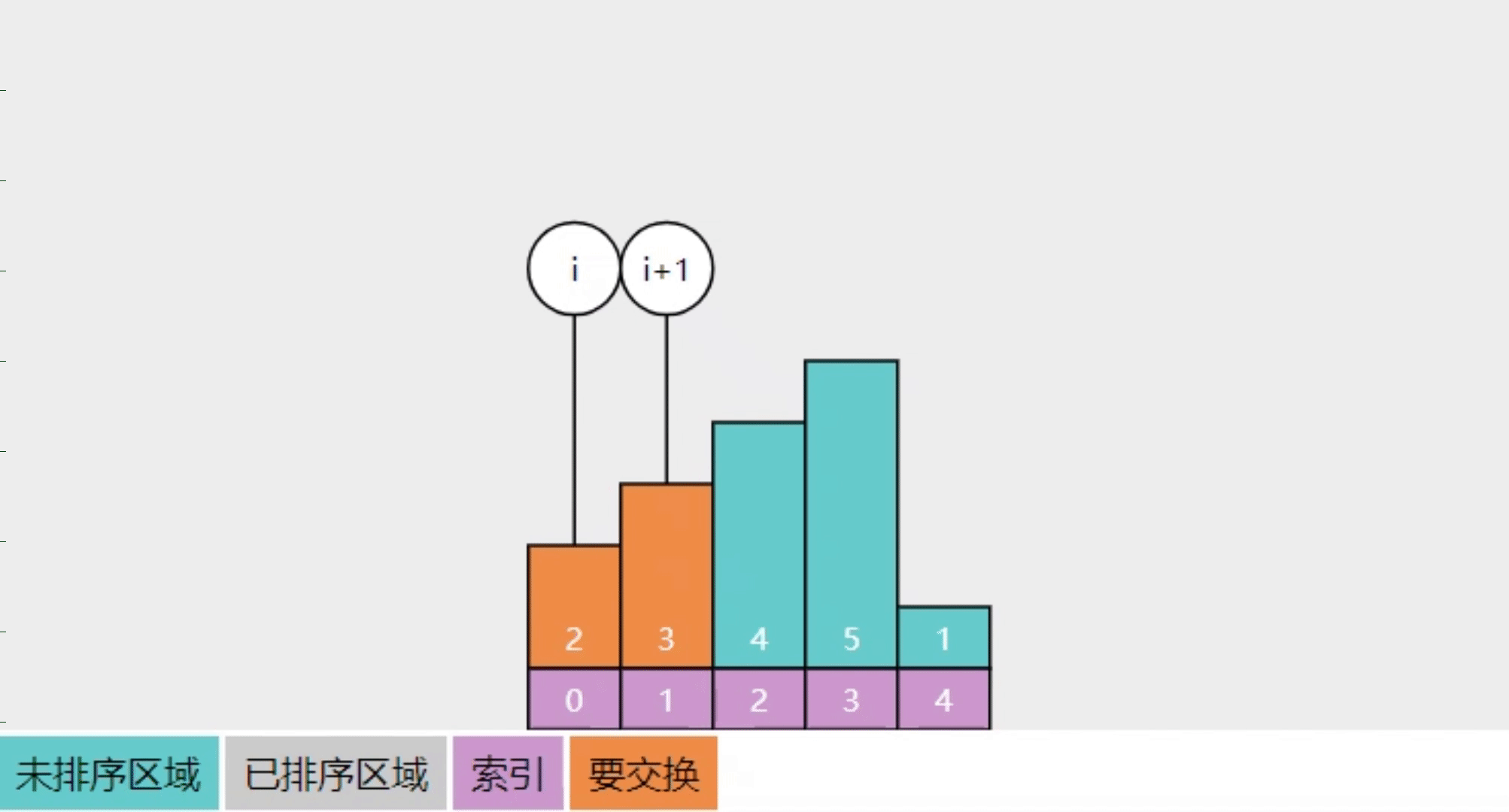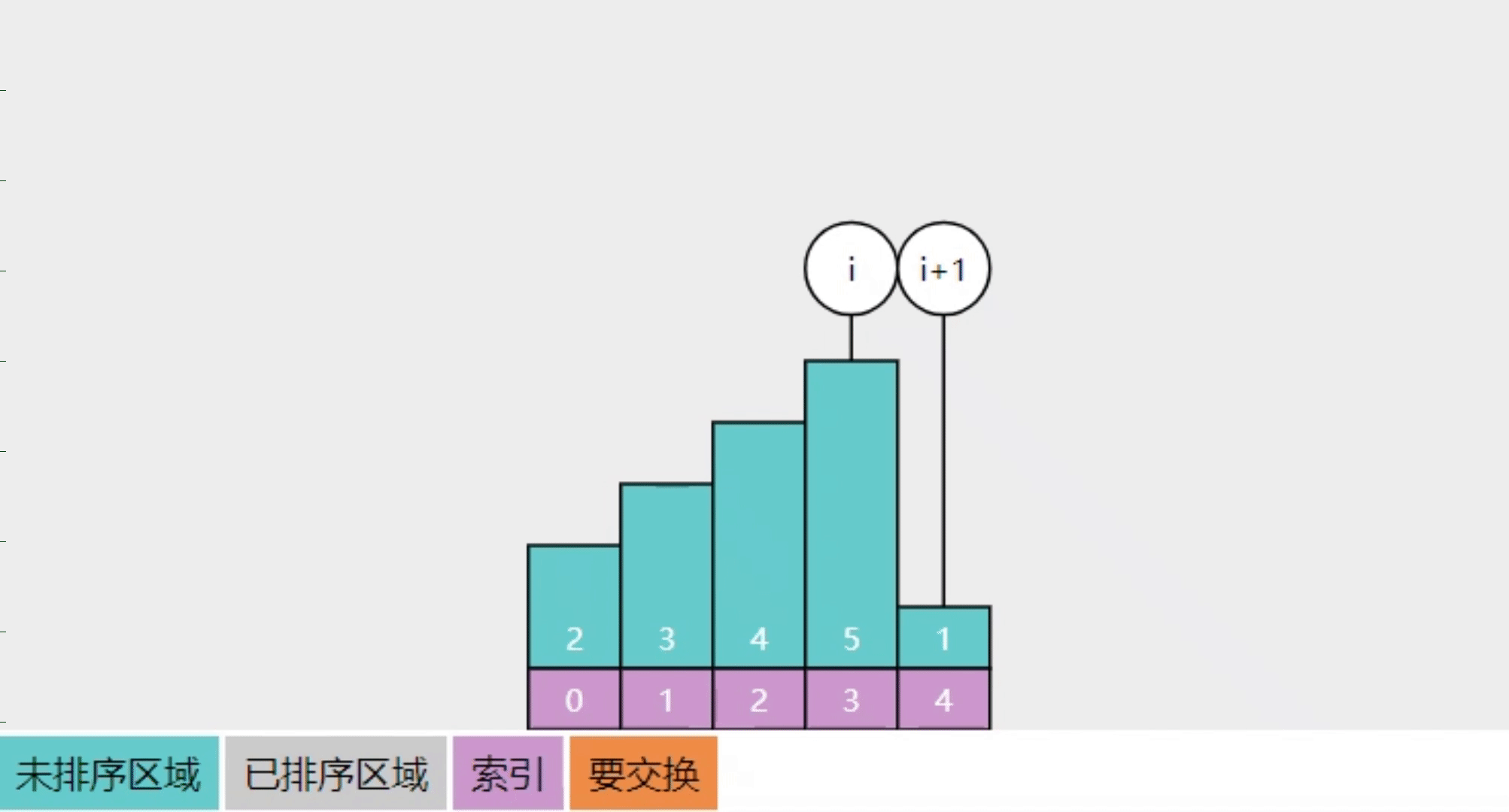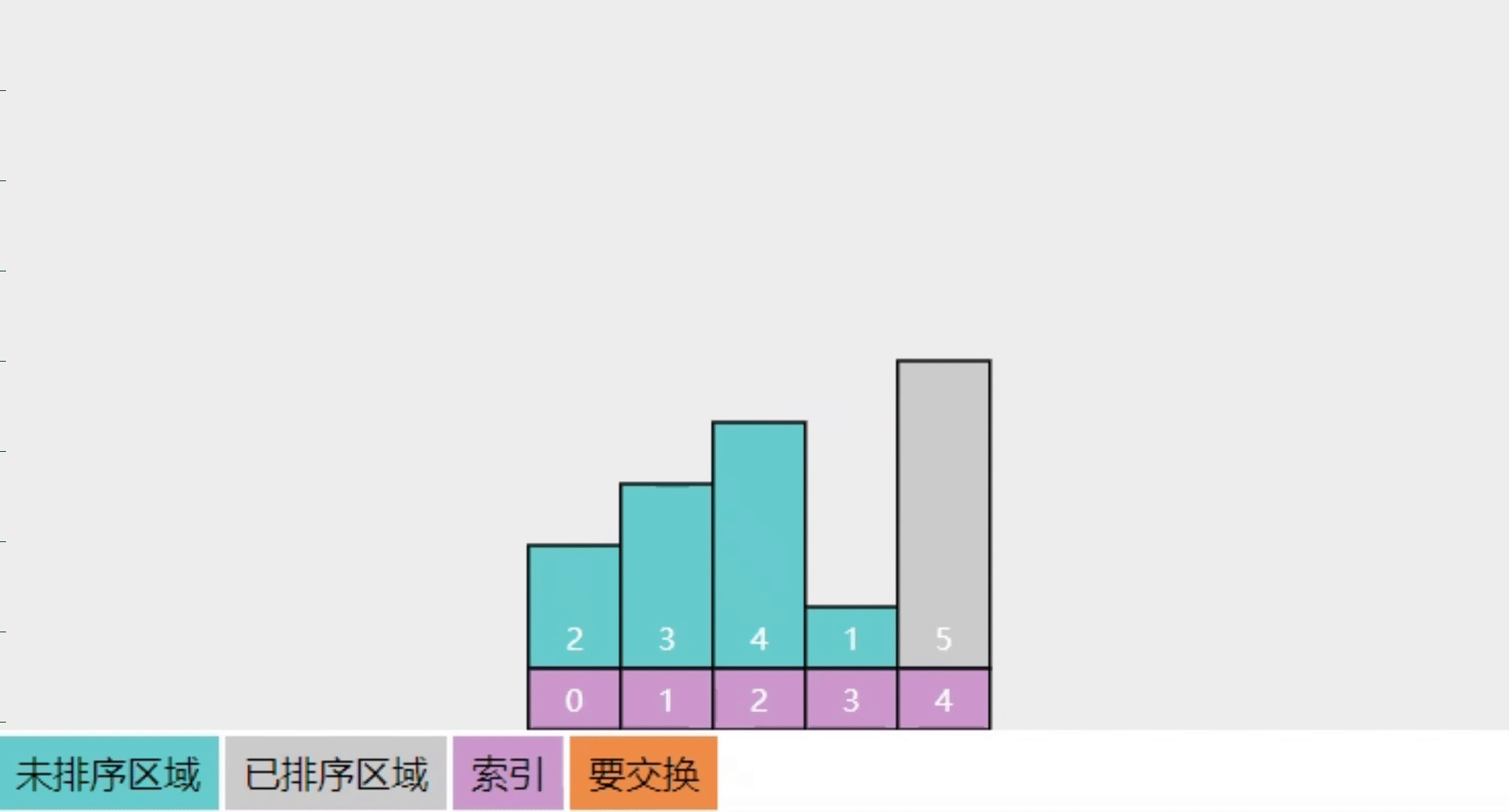
2.3【问】冒泡排序的实现思路
参考下图
- 将整个数组分成【未排序】和【已排序】两个区域
- 每一轮冒泡在【未排序】中从左向右,相邻两数进行比较(图中的 i 与 i+1 处),若它们逆序则交换位置,当这一轮结束时,【未排序】中最大的数会交换至【已排序】
- 这样进行多轮冒泡操作,【已排序】逐渐扩大,而【未排序】逐渐缩小,直至缩减为一,算法结束
P.S.
- 本图只展示了第一轮冒泡
- 上述回答话术偏向书面化,实际回答时应当更自由、更口语化一些,这样可以避免回答时刻板、雷同,但回答中的关键点不能少,这些关键点列举如下:
- 强调把数组分成两个区域:已排序、未排序
- 强调每轮冒泡是从左向右,两两比较
- 每轮冒泡的结果:会将本次最大的数字交换到右侧
- 参考代码
2.4【追问】冒泡排序如何优化
怎么优化呢?每次循环时,若能给【未排序区】确定更合适的边界,则可以减少冒泡轮数
看下面的图
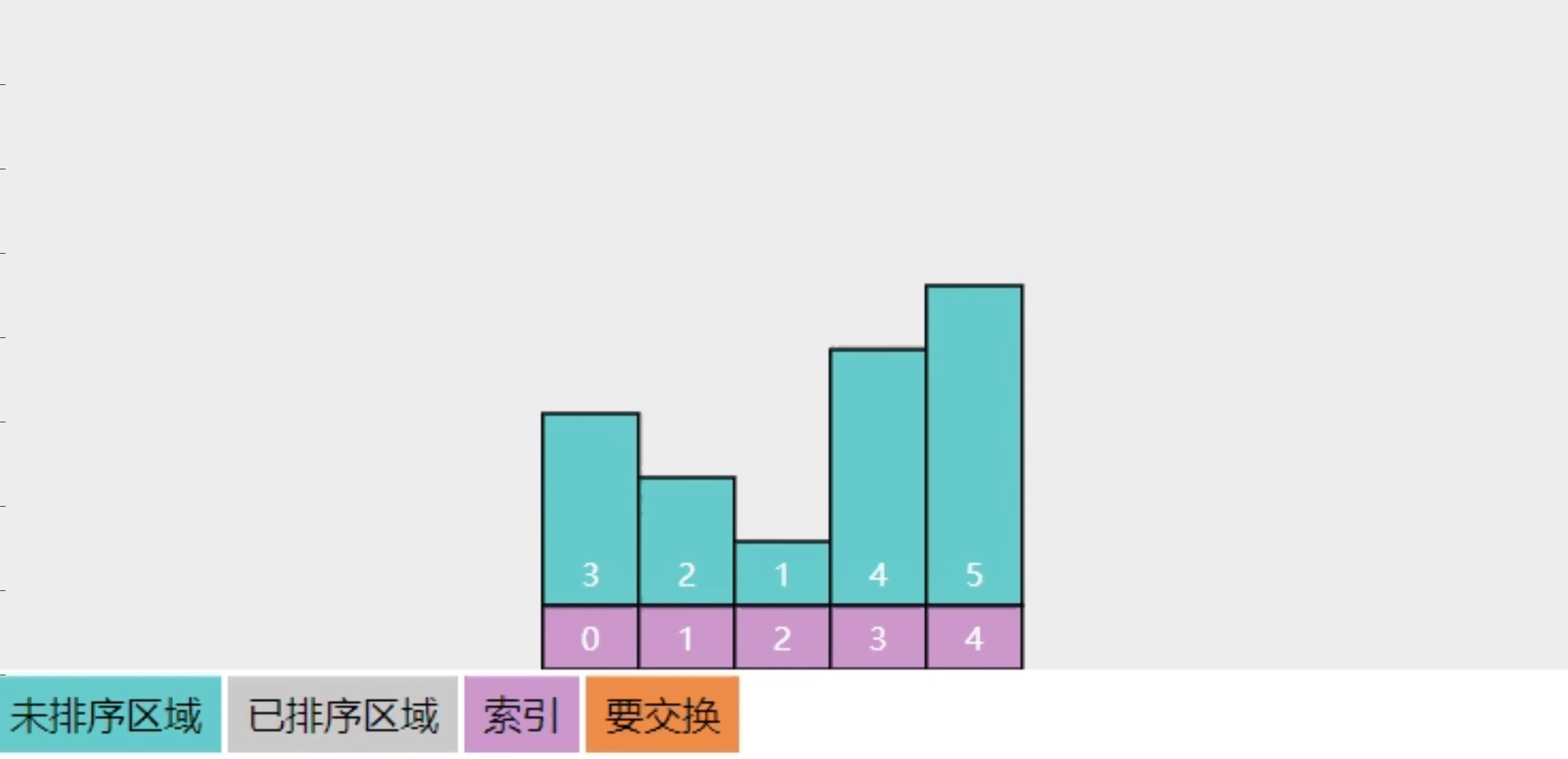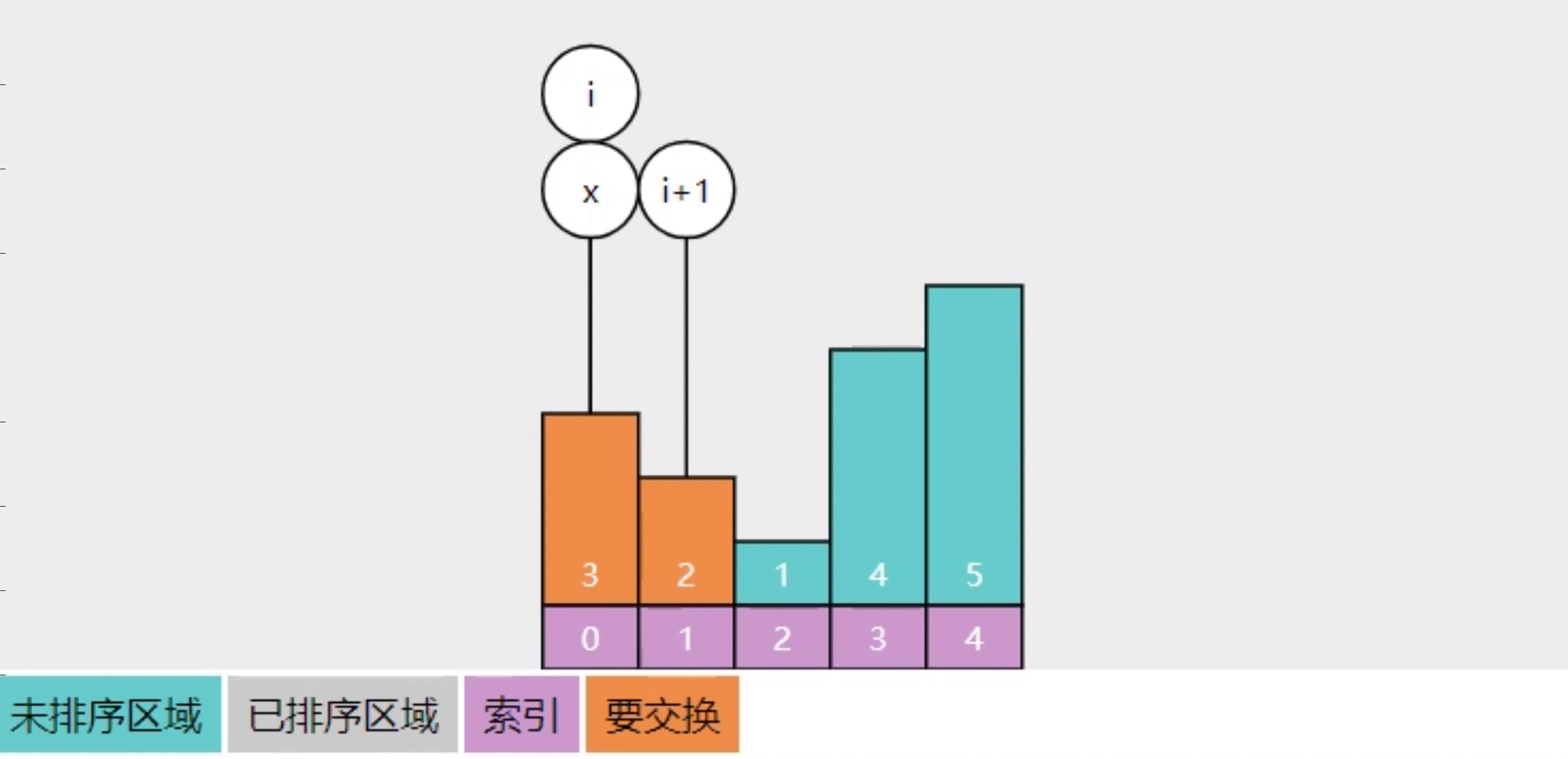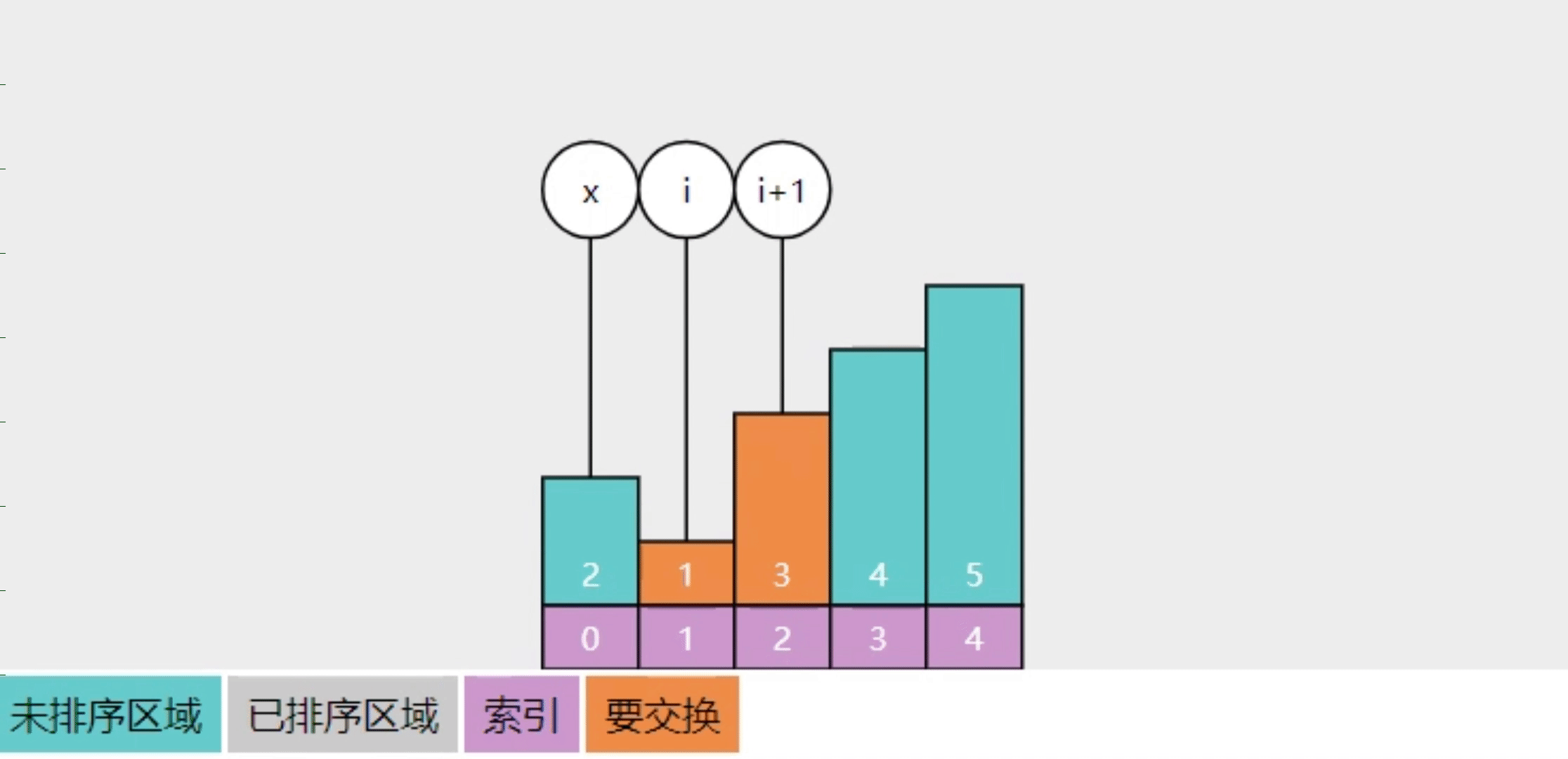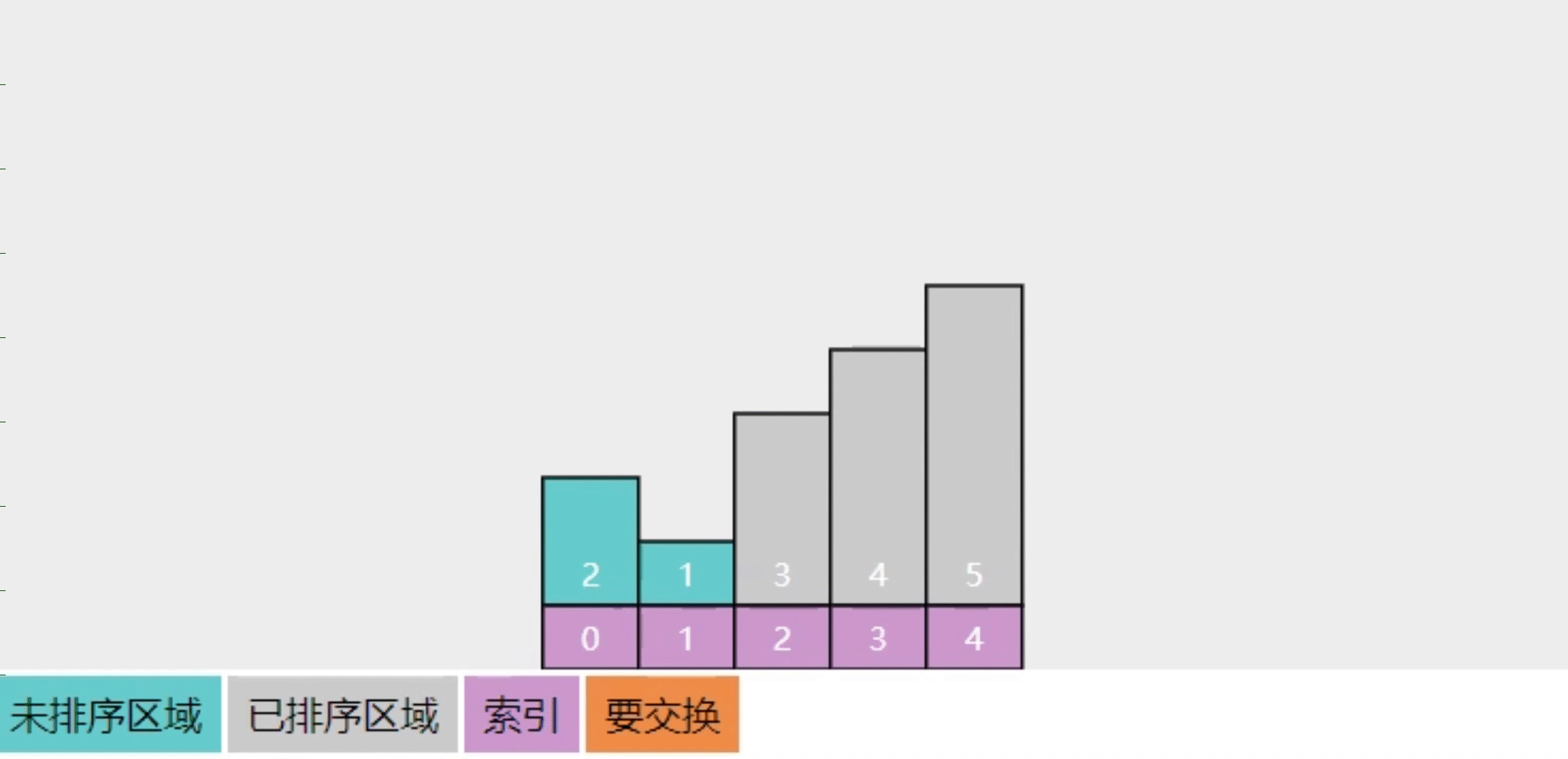
- 以前的实现,每轮只能冒泡一个数字
- 用 x 记录最后一次交换时 i 的位置(索引1处),白话讲就是未排序区的右侧
- 后续比较 3与4 未交换、4与5 未交换,说明它们都有序,相当于一轮就冒泡了3个数字
- 实施此优化后,遇到有序数组,则排序时间复杂度可以降至$$O(n$$
2.5【追问】冒泡排序与其它排序算法比较
- 与选择比
- 时间复杂度:都是 O(n^2)
- 交换
- 冒泡在相邻元素两两比较时,遇到逆序元素,立刻就要进行交换
- 选择可以每轮的结束时,把最大元素交换到已排序区
- 选择的交换次数(或者说元素的移动次数)更少
- 稳定性
- 冒泡是稳定排序
- 选择是不稳定排序
- 对有序数组排序
- 冒泡可以优化,时间复杂度能降至O(n)
- 选择不能优化
- 与插入比
- 时间复杂度:都是 O(n^2)
- 交换
- 插入的交换次数更少
- 稳定性
- 二者都是稳定排序算法
- 对有序数组排序
- 都可以只比较一轮,无需交换,时间复杂度达到$$O(n$$
- 与剩余的排序算法比较
- 时间复杂度不在同一级别,无可比性
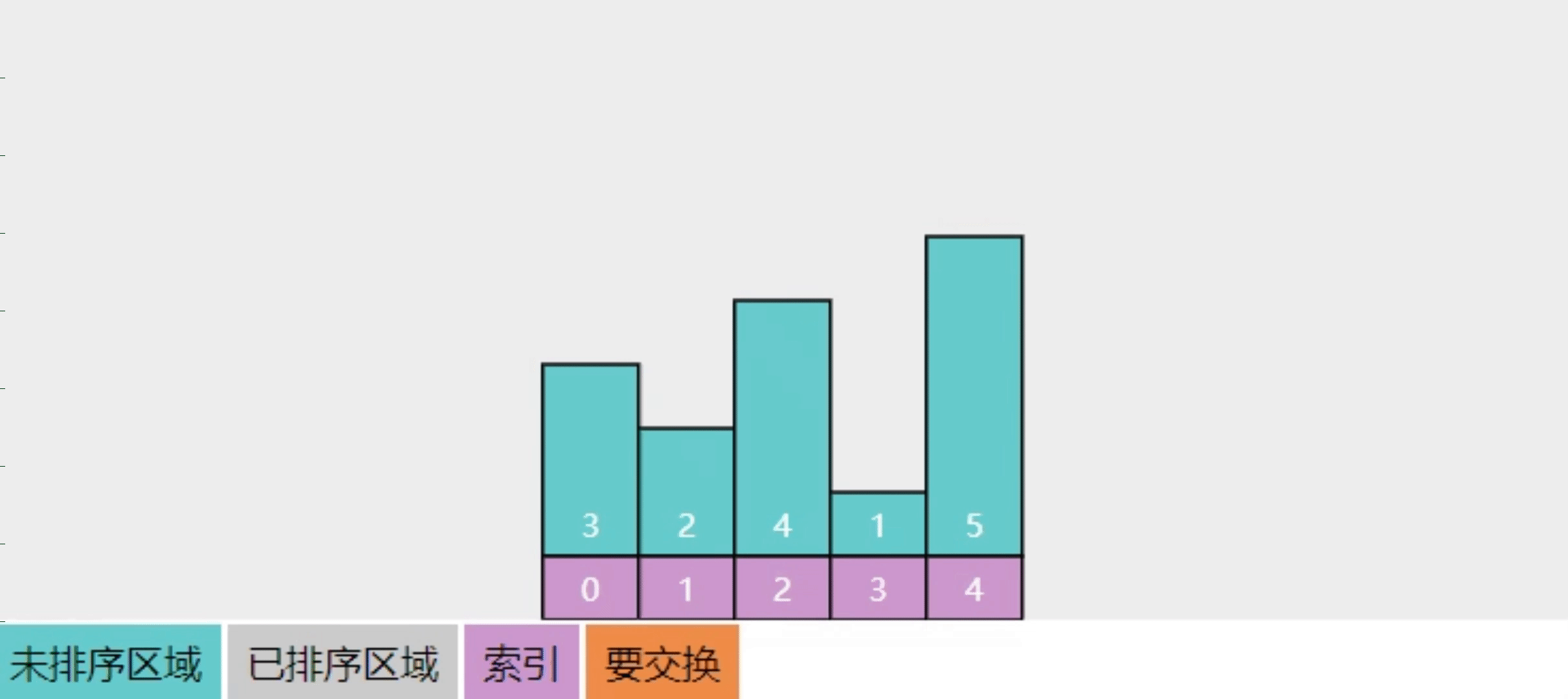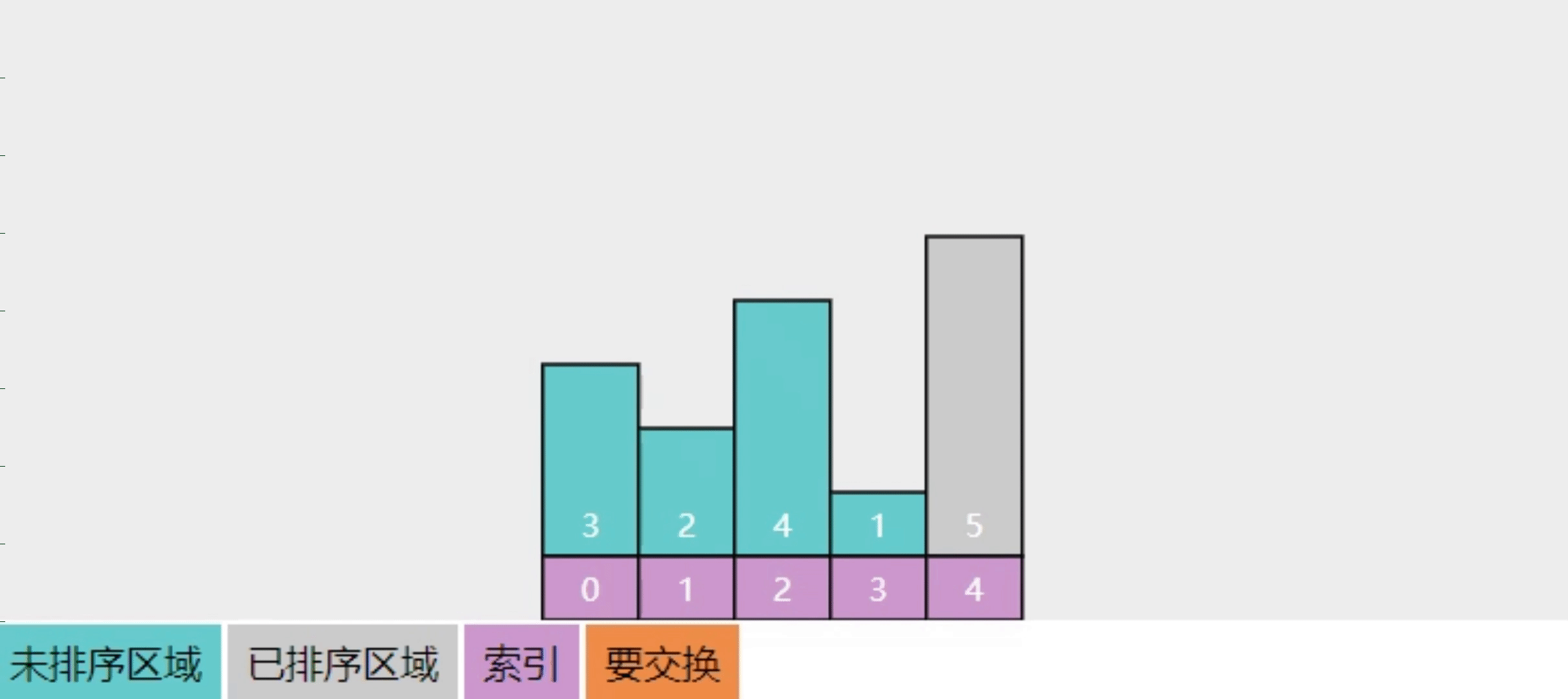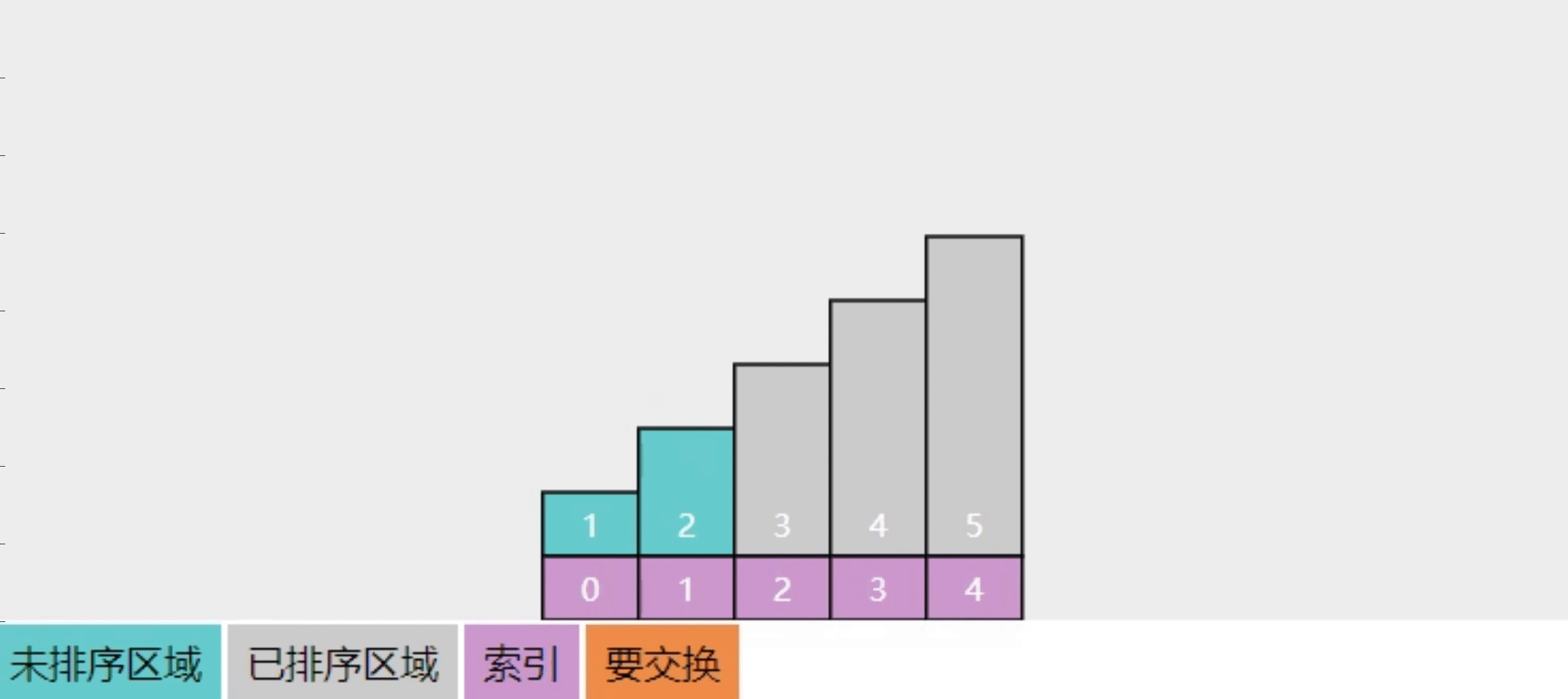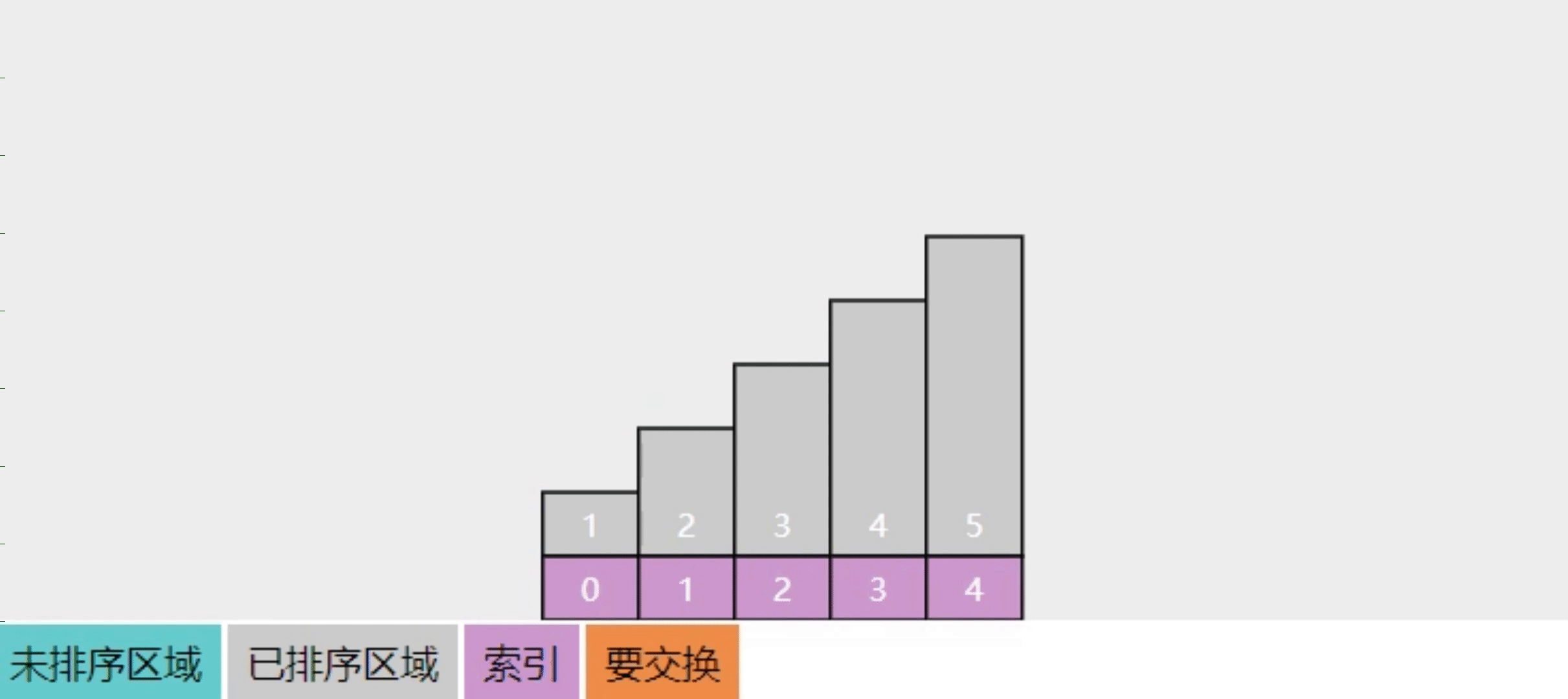
2.6【问】选择排序的实现思路
参考下图
- 将整个数组分成【未排序】和【已排序】两部分
- 每一轮选出【未排序】中最大的元素,交换到【已排序】
- 这样进行多轮选择操作,【已排序】逐渐扩大,而【未排序】逐渐缩小,直至缩减为一,算法结束
P.S.
- 图中展示了 4 轮选择,直至有序
- 还是建议在理解了关键点的基础上自由发挥,用自己语言描述算法
- 回答关键点
- 两个区域:已排序、未排序
- 每次选中未排序区域中最大元素(也可以选最小元素),交换至已排序区域
- 参考代码
2.7【追问】解释什么是不稳定排序
什么是稳定及不稳定排序算法,参照下图进行回答
- 有两个排序时取值相等的元素,比如图中的红桃五和黑桃五
- 如果这些相等元素排序前后的相对位置没有改变(都是红五前、黑五后)那么该排序算法是稳定的
- 如果这些相等元素排序前后的相对位置发生了改变(排序后变成了黑五前、红五后)那么该排序算法不稳定

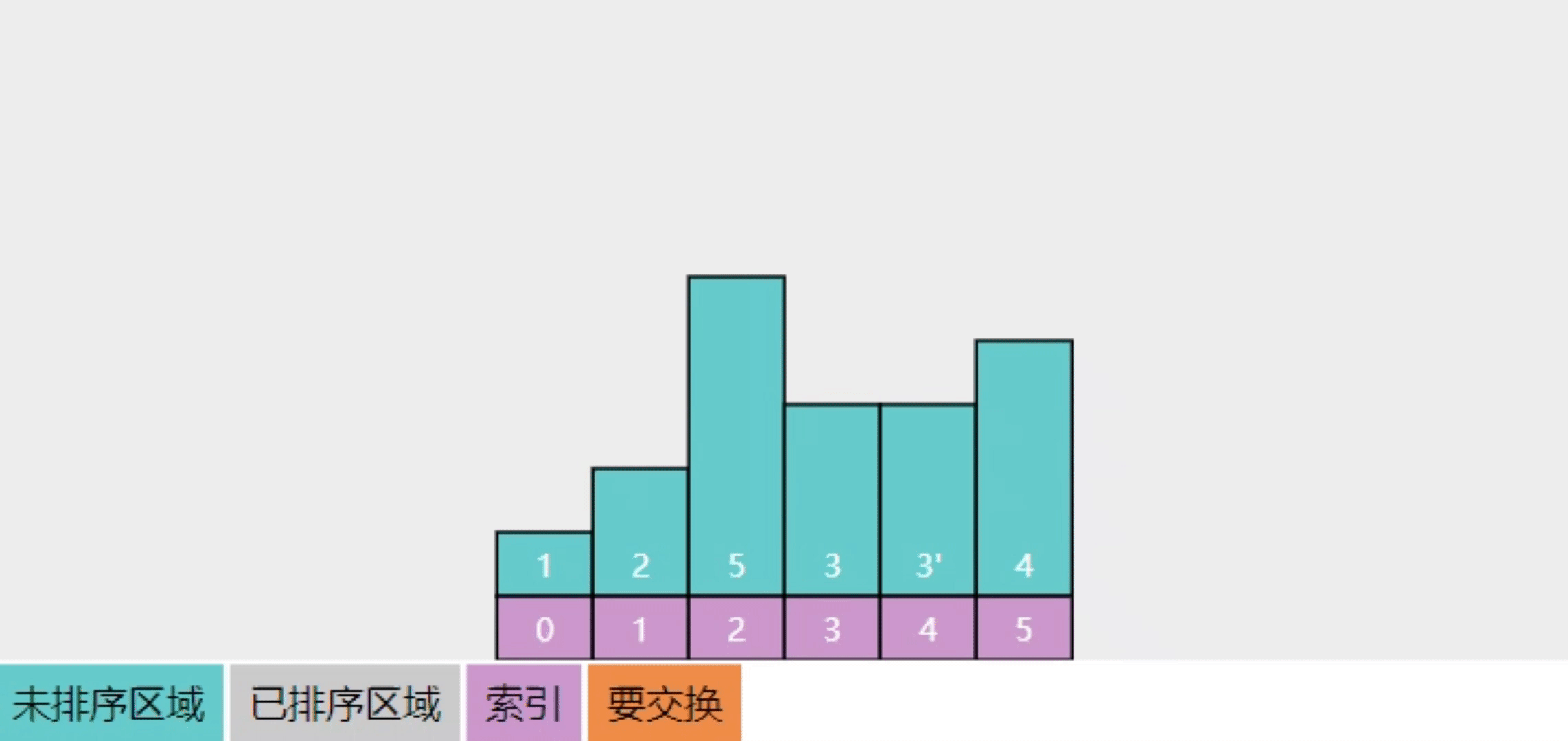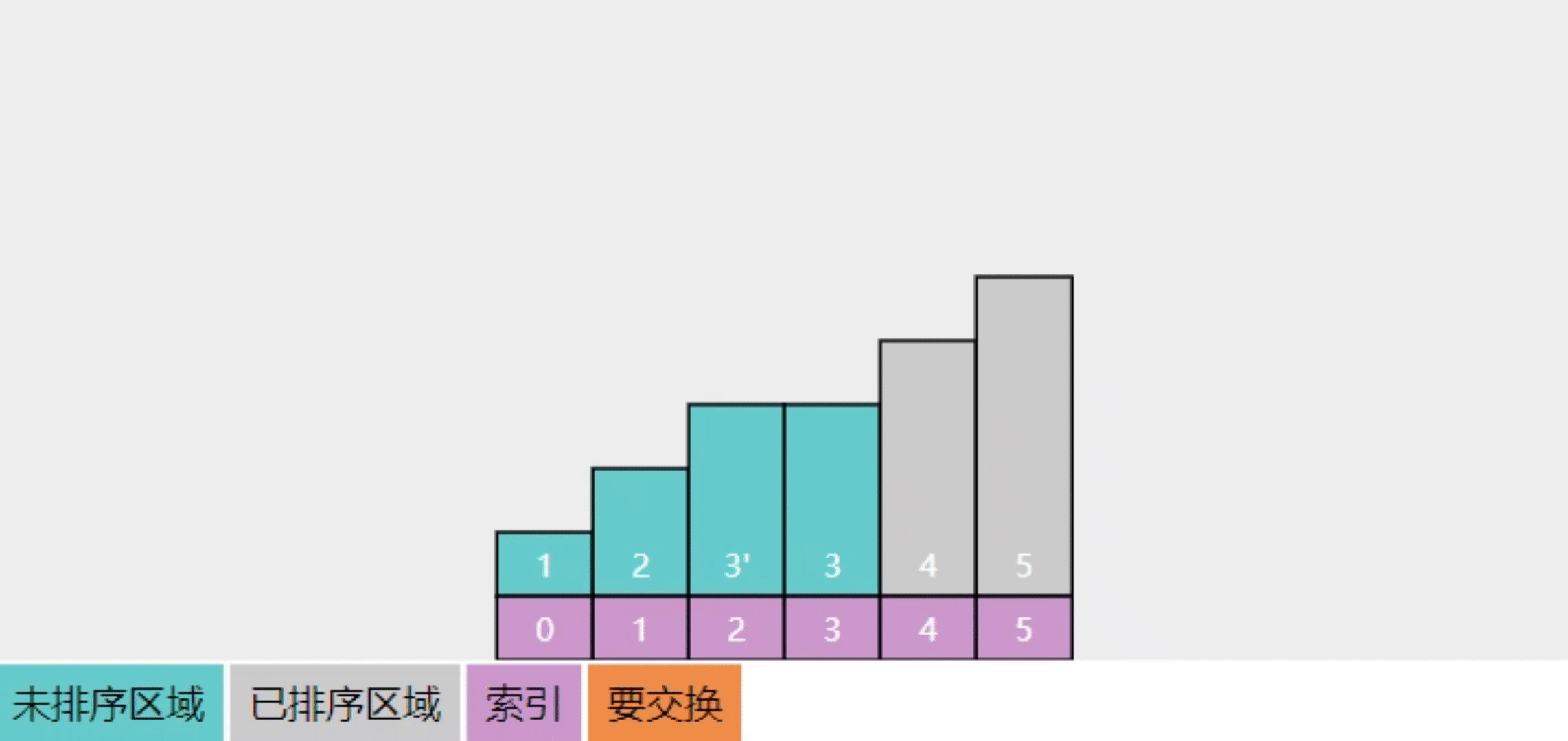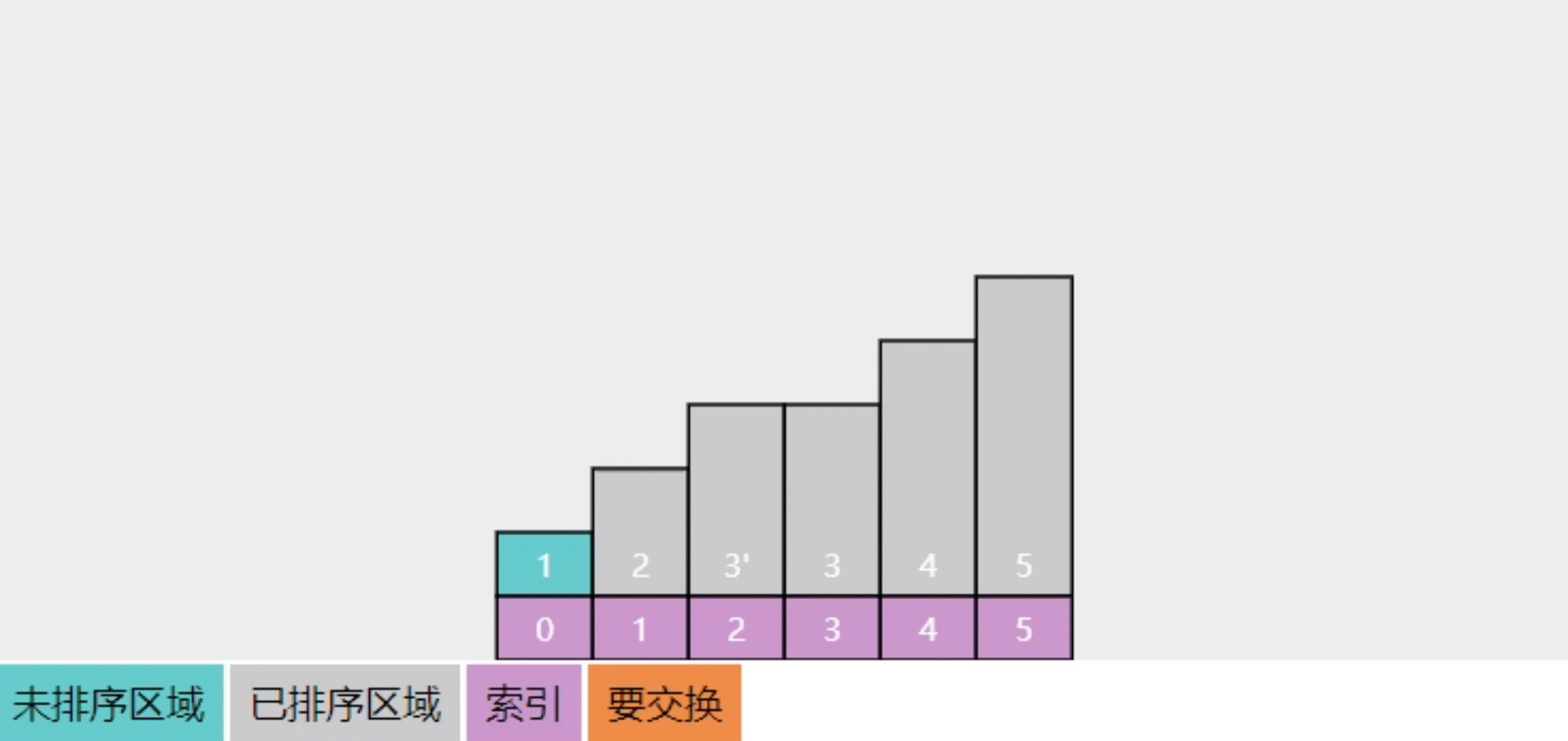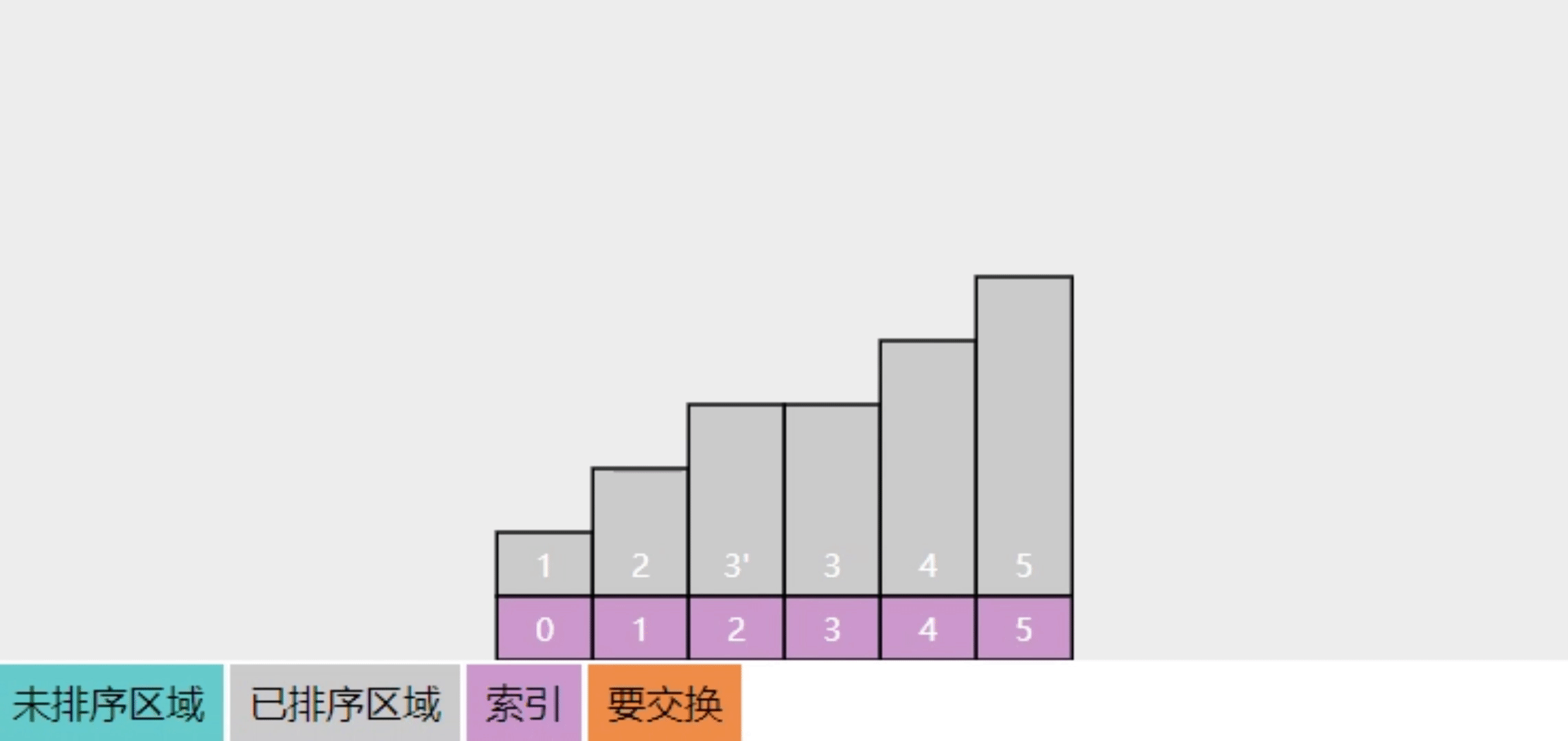
2.8【追问】为啥说选择排序是不稳定的
初始状态如下

- 最初 3 在 3' 的左边
- 第一轮选中最大的5,交换4
- 第二轮选中最大的4,交换了 3'
- ...
- 排序结束,3' 跑到了 3 的左侧
过程可以参考下面的动画效果
2.9【追问】选择排序与其它排序算法比较
- 同级别像插入、冒泡等都是稳定排序算法,而选择属于不稳定排序算法
- 它们的时间复杂度都一样,平均时间复杂度都是O(n^2),不咋地
- 选择排序还应当与堆排序比较
- 相似点:都是每轮选出最大元素,交换至已排序区域
- 不同点:数据结构不同,选择排序底层是线性结构,而堆排序结构是大顶堆,这就造成每次选择的效率是堆结构更高
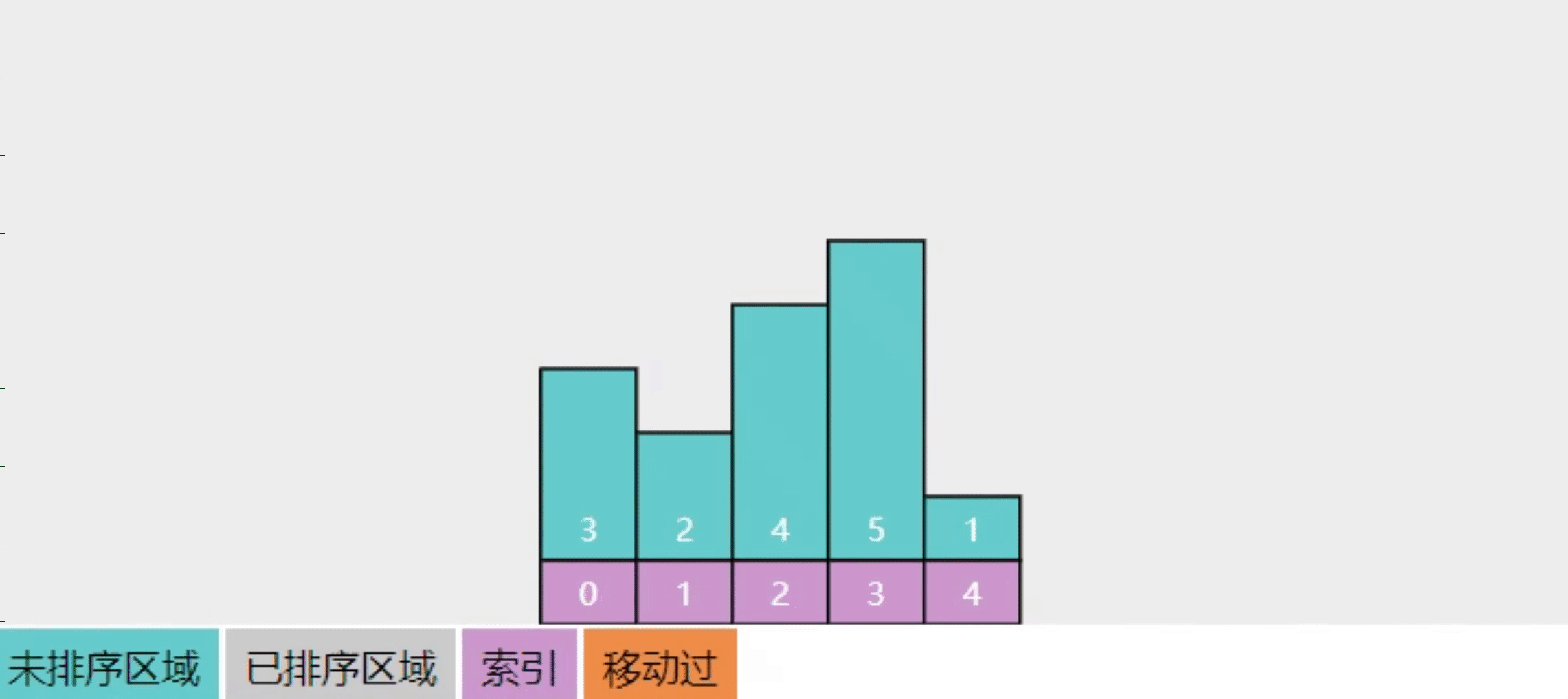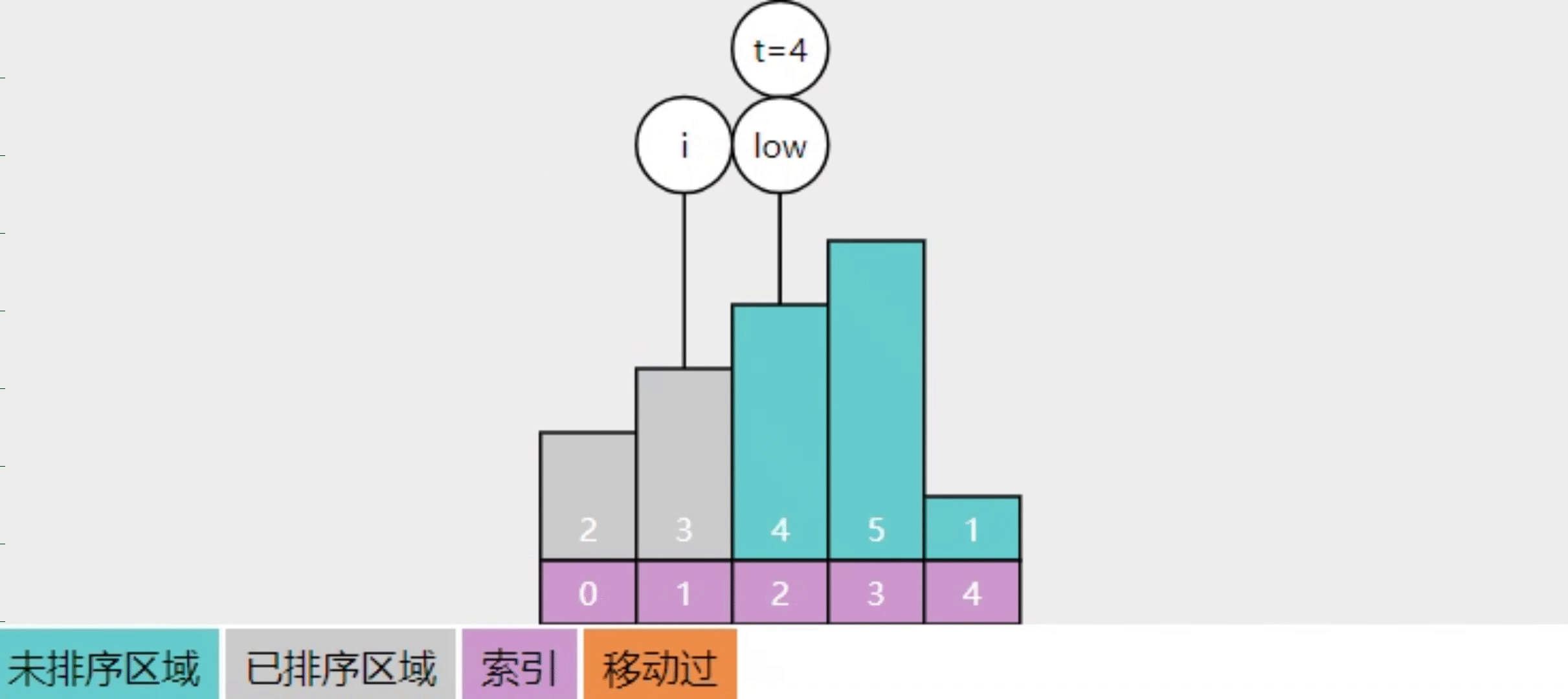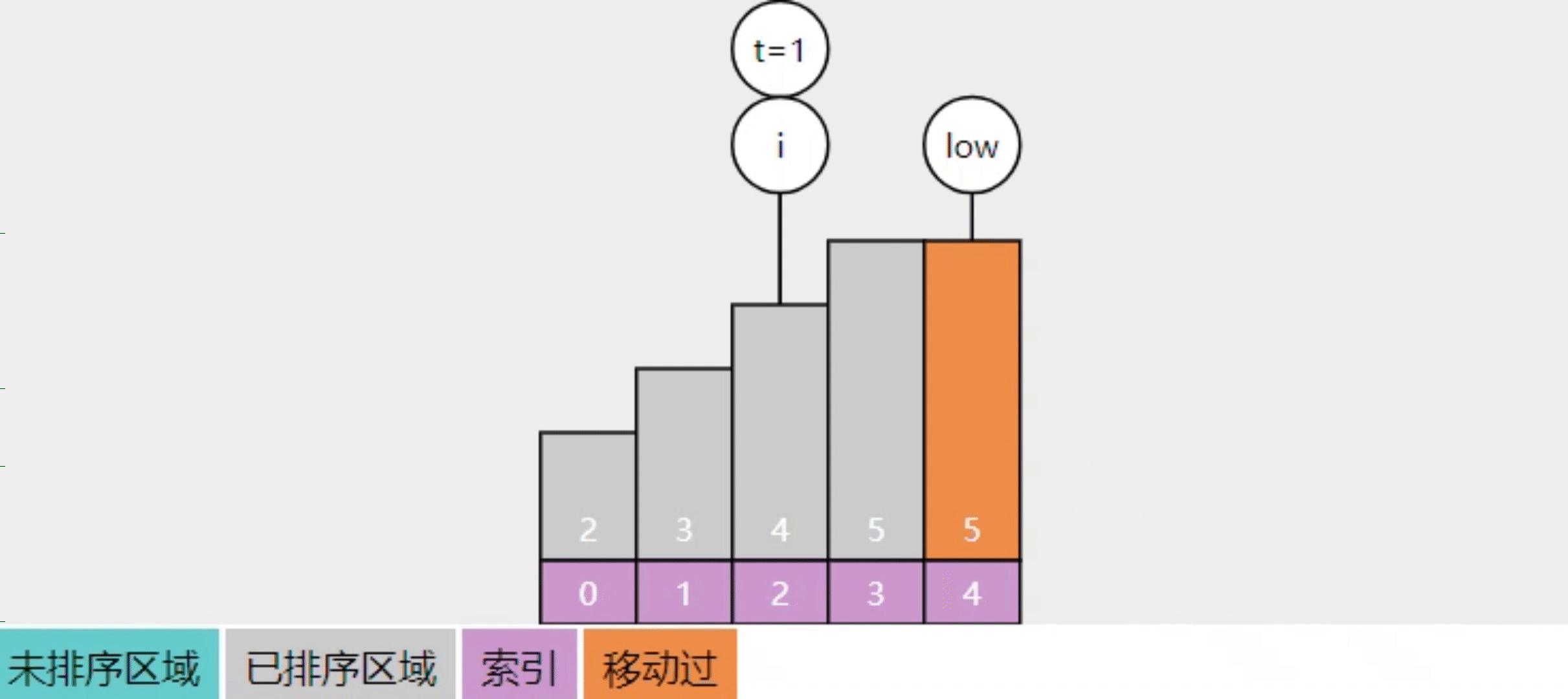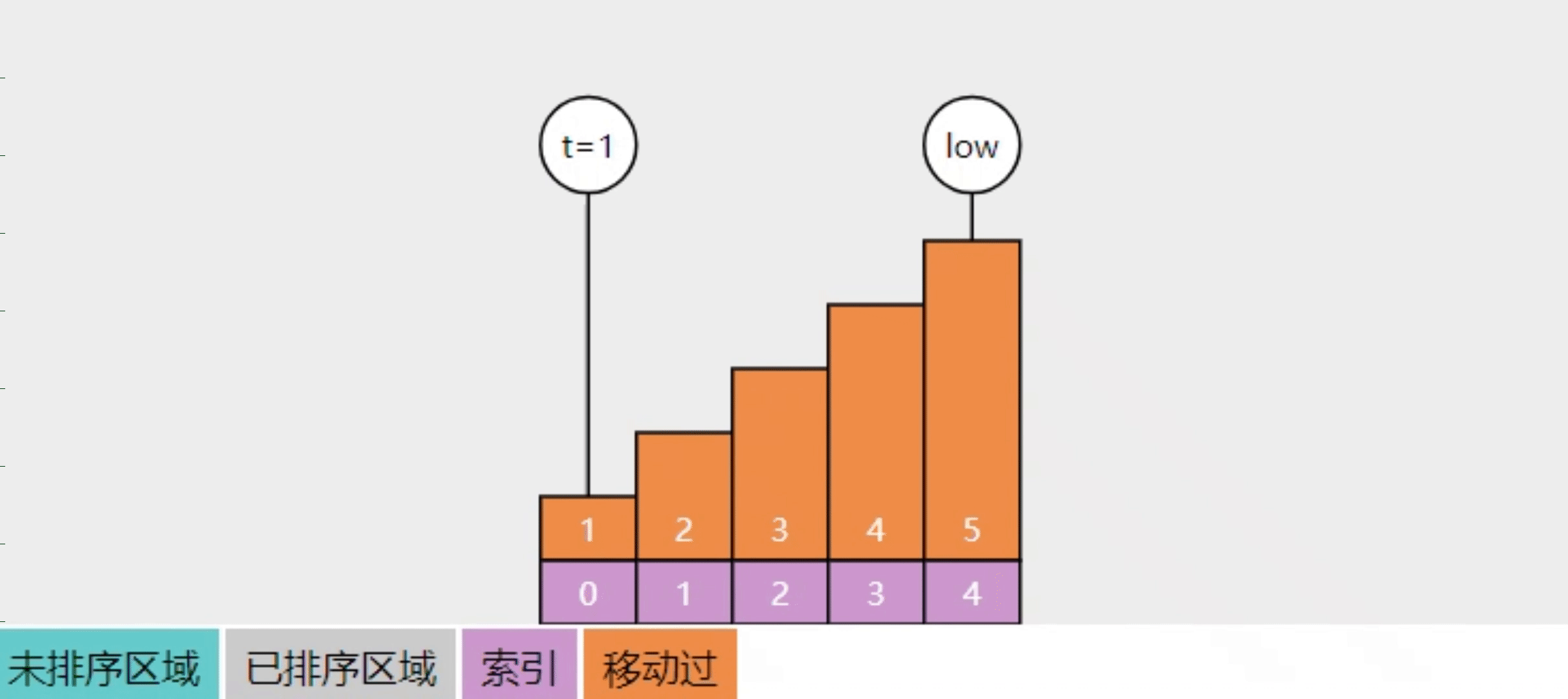
2.10【问】插入排序的实现思路
参考下图
- 将数组分成【已排序】(左边)和【未排序】(右边)两个区域
- 每次从【未排序】的最左边拿出一个数,与已排序的数自右向左比较,直至找到合适位置,插入即可
- 这样进行多轮插入操作,直至【未排序】中没有数,算法结束
P.S.
- 图中 low 指向的是【未排序】区域的最左侧,t 的值即要插入的值
- 回答前想一想自己平时是怎么摸牌、打牌的
- 手上已经有 2、3、4、5 这几张排好的牌,又摸到一张 A,此时应该把它插到哪?
- 手上的牌就是已排序区域,摸的新牌来自未排序区,从右找的话,那么就找比新牌小的那个位置插入
- 参考代码
