
向量数据库的工作原理主要围绕高维向量数据的嵌入存储、索引构建和高效检索展开,其核心目标是通过优化数据结构和算法,在大规模高维数据场景下实现快速的相似性搜索。向量数据库通过向量索引技术(如HNSW、IVF-PQ)和近似最近邻搜索(ANN),解决了传统数据库无法高效处理高维向量数据的问题。其核心在于将非结构化数据转化为向量表示,并通过优化索引和算法实现快速相似性检索
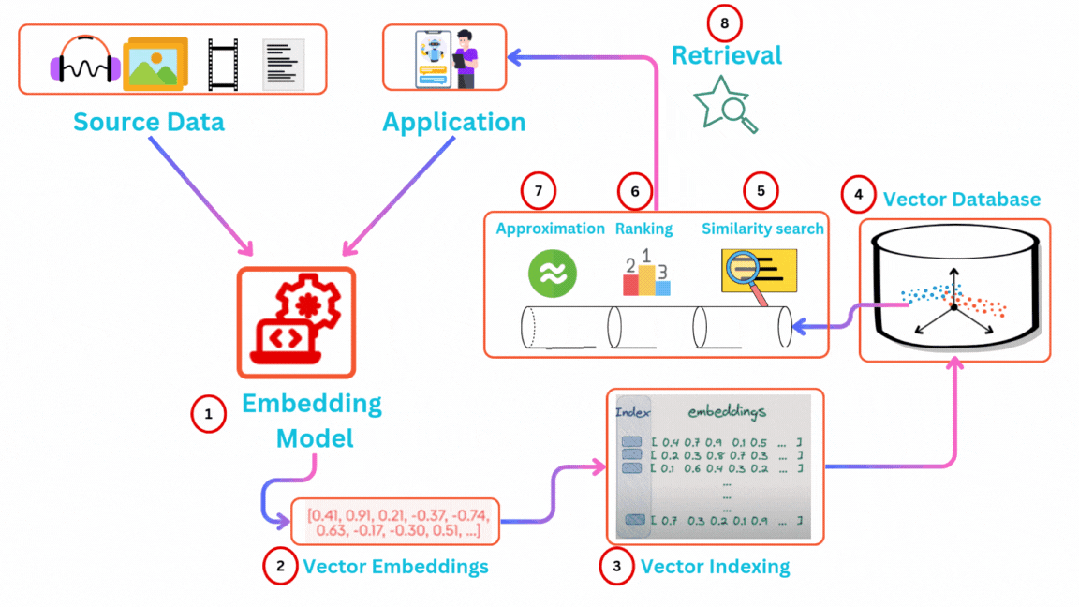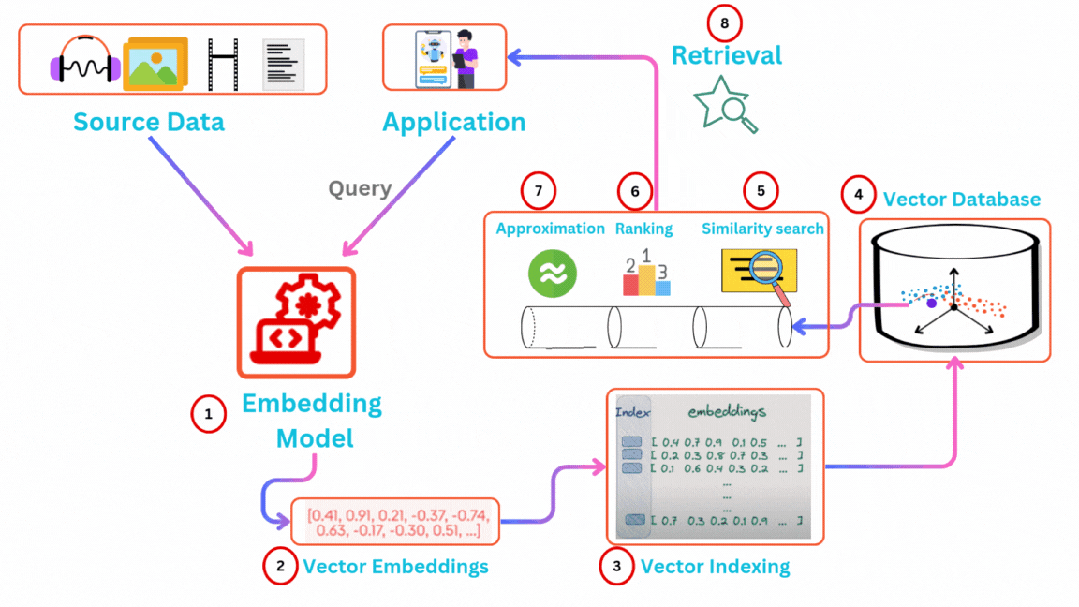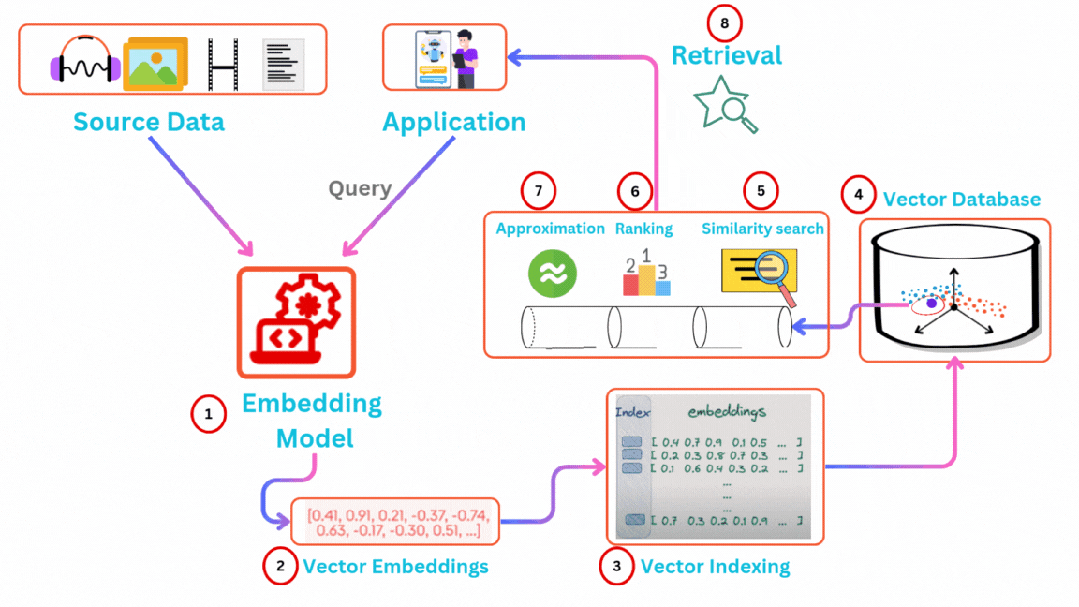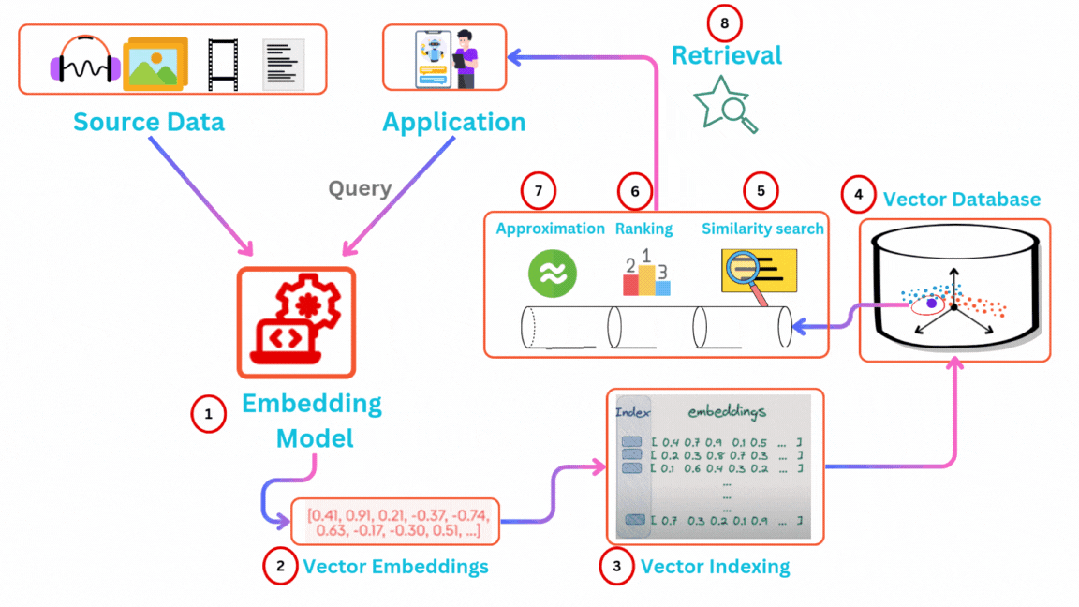
向量数据库的工作原理主要围绕高维向量数据的嵌入存储、索引构建和高效检索展开,其核心目标是通过优化数据结构和算法,在大规模高维数据场景下实现快速的相似性搜索。向量数据库通过向量索引技术(如HNSW、IVF-PQ)和近似最近邻搜索(ANN),解决了传统数据库无法高效处理高维向量数据的问题。其核心在于将非结构化数据转化为向量表示,并通过优化索引和算法实现快速相似性检索

