引言
本系列讲解 空间转录组学 (Spatial Transcriptomics) 相关基础知识与数据分析教程,持续更新,欢迎关注,转发,文末有交流群!
归一化
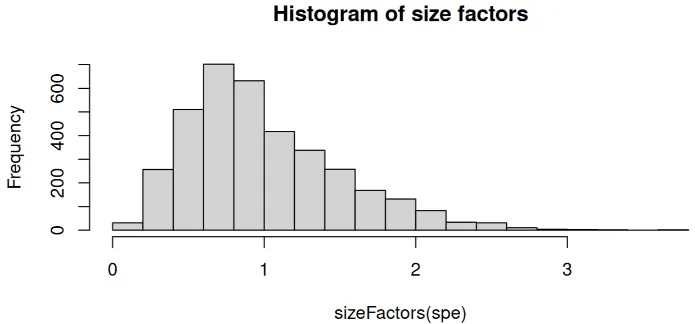
使用 library size normalization 计算经过对数变换的归一化计数(logcounts)。我们使用来自 scater 和 scran 包的方法,做出简化假设,即 spots 可以被视作等同于 single cells。
# calculate library size factors
spe <- computeLibraryFactors(spe)
summary(sizeFactors(spe))
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.1330 0.6329 0.8978 1.0000 1.2872 3.7820
hist(sizeFactors(spe), breaks = 20, main = "Histogram of size factors")
# calculate logcounts
spe <- logNormCounts(spe)
assayNames(spe)
## [1] "counts" "logcounts"
特征选择(HVGs)
应用特征选择方法以识别一组顶级高变异基因(HVGs)。我们使用 scran包的方法,再次做出简化假设,即 spots 可以被视作等同于 single cells。
我们还首先移除线粒体基因,因为这些基因通常表达非常高,且不是主要生物学关注点。
# remove mitochondrial genes
spe <- spe[!is_mito, ]
dim(spe)
## [1] 33525 3614
# fit mean-variance relationship, decomposing variance into
# technical and biological components
dec <- modelGeneVar(spe)
# select top HVGs
top_hvgs <- getTopHVGs(dec, prop = 0.1)
# number of HVGs selected
length(top_hvgs)
## [1] 1424
降维
接下来,我们使用主成分分析(PCA)对顶级高变异基因(HVGs)进行降维。我们保留前 50 个主成分(PCs)以供后续下游分析。这样做既能减少噪声,也能提高计算效率。我们还在前 50 个 PCs 上运行 UMAP,并保留前 2 个 UMAP 成分用于可视化。
我们使用 scater 包中计算高效的 PCA 实现,该实现使用随机化,因此需要设置随机种子以保证可重复性。
# using scater package
set.seed(123)
spe <- runPCA(spe, subset_row = top_hvgs)
spe <- runUMAP(spe, dimred = "PCA")
reducedDimNames(spe)
## [1] "PCA" "UMAP"
dim(reducedDim(spe, "PCA"))
## [1] 3614 50
dim(reducedDim(spe, "UMAP"))
## [1] 3614 2
# update column names for plotting
colnames(reducedDim(spe, "UMAP")) <- paste0("UMAP", 1:2)
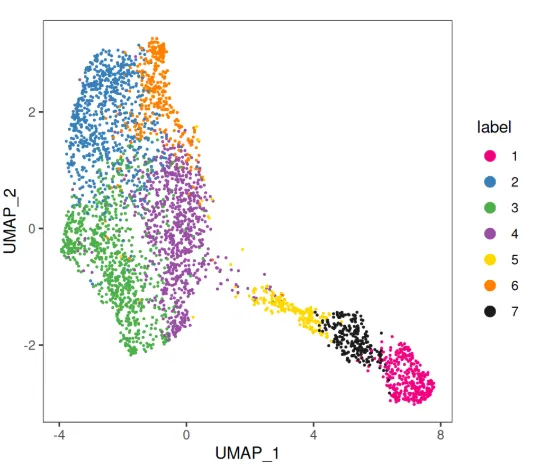
聚类
接下来,我们应用聚类算法以识别细胞类型或空间域。请注意,在此示例中,我们仅使用分子特征(基因表达)作为聚类的输入。
在此,我们使用基于图的聚类,采用 scran 中实现的 Walktrap 方法,应用于上述基于顶级高变异基因(HVGs)计算出的前 50 个主成分(PCs)。
# graph-based clustering
set.seed(123)
k <- 10
g <- buildSNNGraph(spe, k = k, use.dimred = "PCA")
g_walk <- igraph::cluster_walktrap(g)
clus <- g_walk$membership
table(clus)
## clus
## 1 2 3 4 5 6 7
## 365 765 875 803 198 370 238
# store cluster labels in column 'label' in colData
colLabels(spe) <- factor(clus)
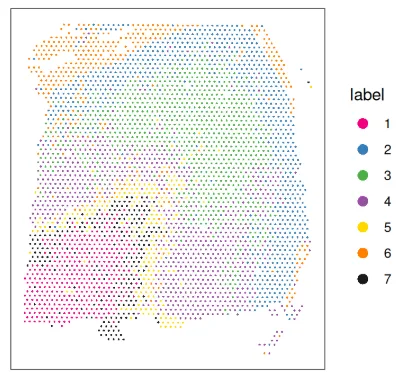
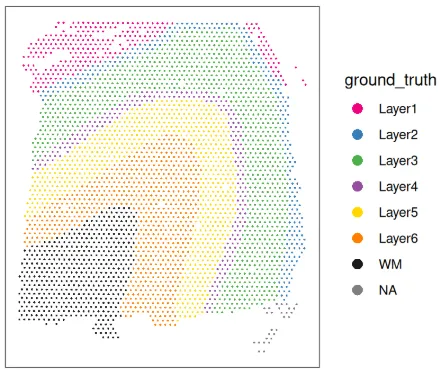
通过在X-Y空间中绘制群集标签,并与该数据集可用的手动注释参考标签(ground_truth)一起绘制。
# plot cluster labels in x-y space
plotCoords(spe, annotate = "label", pal = "libd_layer_colors")
# plot manually annotated reference labels
plotCoords(spe, annotate = "ground_truth", pal = "libd_layer_colors")
# plot clusters labels in UMAP dimensions
plotDimRed(spe, plot_type = "UMAP", annotate = "label",
pal = "libd_layer_colors")