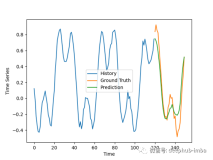
在视频目标跟踪领域,如何充分利用时间序列信息以提高跟踪精度一直是研究的关键。长短期记忆网络(LSTM)因其独特的结构和对时间序列数据的强大处理能力,在这方面展现出了显著优势。
LSTM的核心在于其门控机制,包括遗忘门、输入门和输出门。遗忘门决定了从记忆细胞中遗忘多少过去的信息。在视频目标跟踪中,随着视频帧的不断推进,一些早期帧中的目标信息可能不再对当前跟踪有帮助,遗忘门可以根据当前的输入和之前的隐藏状态,决定是否丢弃这些信息,从而避免无关信息的干扰。例如,当目标短暂离开视野后又重新出现时,遗忘门可以帮助模型忘记目标离开期间的一些噪声信息,专注于目标重新出现后的特征。
输入门则决定了有多少新的信息要加入到记忆细胞中。在视频中,每一帧都包含着关于目标的新信息,如位置、外观等。输入门通过对当前帧的特征进行筛选,将重要的新信息整合到记忆细胞中,更新对目标的描述。比如,当目标的外观因为光照变化或姿态改变而发生变化时,输入门能够及时将这些新的外观特征信息纳入模型的记忆,使得模型能够适应目标的动态变化。
输出门控制着从记忆细胞中输出多少信息到隐藏状态,进而影响模型的预测结果。它根据记忆细胞的状态和当前的输入,决定哪些信息对于当前的目标跟踪是最关键的,并将这些信息输出。例如,在复杂的背景下,输出门可以突出目标的关键特征,抑制背景噪声的干扰,从而更准确地预测目标的位置。
此外,LSTM的细胞状态作为信息的主要载体,允许信息跨越多个时间步骤传递。在视频目标跟踪中,这一特性使得模型能够捕捉到目标在较长时间段内的运动模式和特征变化。例如,目标可能在一段时间内呈现出特定的运动轨迹或行为模式,LSTM通过细胞状态可以记住这些长期依赖关系,即使在目标被部分遮挡或出现短暂的外观变化时,也能根据之前学习到的模式进行准确的跟踪。
在实际应用中,通常将LSTM与目标检测算法结合使用。例如,先利用YOLO等算法对视频序列中的每一帧图像进行目标检测,获取目标的位置、类别、置信度以及外观特征等信息。然后,将这些信息输入到LSTM网络中,LSTM通过学习这些时间序列数据中的模式和依赖关系,预测视频中下一帧目标的位置,并实现帧与帧之间的目标匹配与关联。通过这种方式,LSTM能够充分利用视频中的时间序列信息,对目标进行连续、准确的跟踪。