
高性能的任务流线程池
线程池使用mod
Thread
Lock
Task
Semaphore
Queue
优化:
Work Steal-任务偷窃机制
任务偷窃机制,顾名思义就是偷取任务。我们写任务流线程池,普通的做法是定义多个任务队列分别去执行一部分任务,但是我们需要知道的是,我们为每个队列分配任务的时候,不可能面面俱到使得所有的队列同时执行完毕。
换句话说,我们举一个极限情况的例子,我们的线程池中有两个任务队列A和B,分别都分配了5个任务,经过T后,A队列任务全部执行完毕,但是此时B队列的任务只执行完成了2个,也就是A完成的时候还要等待B继续完成剩下的3个任务。这就造成了资源和性能的浪费,这时就需要用到任务偷窃机制。
我们可以设置total任务队列(盛放所有的任务),其他的任务队列初始化为空,线程池开始的时候,每个队列从total中取任务,可以是批量取也可以单独取。
如下图:

但是Work Steal机制也可能成为线程池的累赘,为什么这么说呢?我明明感觉他很完美啊!
举一个例子,当我们的线程池中有100个任务,开了50个线程,当有49个线程都在工作时,此时还剩下一个任务没有执行,显而易见应当是剩下的那个线程去偷取剩下的一个任务,但是如果我们有30个任务组盛放了这100的任务,此时剩下的一个任务还不知道被放在哪里了呢。这个时候该空闲线程会去遍历这30个任务组去寻找这一个任务。就为了一个任务去循环30次是浪费的!
我们可以设置一个偷取范围。为每一个线程都设置一个偷取范围,指定每个线程可以偷取哪几个任务组的任务。换句话说,只扫门前雪:线程只关注自己的邻居的任务组可不可以拿任务,当拿不到的时候(就是没任务的时候)再去其他的地方取任务,这样就解决了大量循环的问题。
同样的方法,我们也可以为每个任务组设置一个编号,去检测每个任务组的任务数。当发生上述情况的时候,我们可以马上监测到剩余的任务在哪个任务组中,我们就不用去挨个遍历了。
代码见下(详细代码见于github):
//
// Created by 34435 on 2024/9/30.
//
/*
* @Description: 包含盗取功能的安全队列
* */
#ifndef MC_THREAD_POOL_WORKSTEALINGQUEUE_H
#define MC_THREAD_POOL_WORKSTEALINGQUEUE_H
#include <E:/Boost/boost_1_86_0/boost/core/noncopyable.hpp>
#include <mutex>
#include <queue>
#include <thread>
template<typename T>
class __attribute__((unused)) WorkStealingQueue : boost::noncopyable {
public:
/*
* @param: 偷取任务
* */
__attribute__((unused)) bool trySteal(T&& task) {
bool res = false;
if (!deque_.empty()) {
task = std::forward<T> (deque_.back());
deque_.pop_back();
res = true;
}
return res;
}
/*
* @param: 批量偷取任务
* */
__attribute__((unused)) bool trySteal(std::vector<T>&& tasks, int maxStealSize) {
bool res = false;
while (!deque_.empty() && maxStealSize-- >= 0) {
tasks.emplace_back(std::forward<T> (deque_.back()));
deque_.pop_back();
res = true;
}
return res;
}
__attribute__((unused)) bool push(T&& task) {
while (true) {
if (lock_.try_lock()) {
deque_.emplace_back(std::forward<T> (task));
lock_.unlock();
break;
}
else std::this_thread::yield();
}
}
__attribute__((unused)) bool push(std::vector<T>&& tasks) {
while (true) {
if (lock_.try_lock()) {
for (auto& task : tasks)
deque_.emplace_back(std::forward<T> (task));
lock_.unlock();
break;
}
else std::this_thread::yield();
}
}
__attribute__((unused)) bool tryPush(T&& task) {
bool res = false;
if (lock_.try_lock()) {
deque_.emplace_back(std::forward<T> (task));
lock_.unlock();
res = true;
}
return res;
}
__attribute__((unused)) bool tryPush(std::vector<T>&& tasks) {
bool res = false;
if (lock_.try_lock()) {
for (auto& task : tasks) {
deque_.emplace_back(std::forward<T> (task));
}
lock_.unlock();
res = true;
}
return res;
}
__attribute__((unused)) bool tryPop(T& task) {
bool res = false;
if (!deque_.empty() && lock_.try_lock()) {
task = std::forward<T> (deque_.front());
deque_.pop_front();
lock_.unlock();
res = true;
}
return res;
}
__attribute__((unused)) bool tryPop(std::vector<T>& taskArr, int maxLocalBatchSize) {
bool res = false;
if (!deque_.empty() && lock_.try_lock()) {
while (!deque_.empty() && maxLocalBatchSize-- >= 0) {
taskArr.emplace_back(std::forward<T> (deque_.front()));
deque_.pop_front();
res = true;
}
lock_.unlock();
}
return res;
}
WorkStealingQueue() = default;
private:
std::deque<T> deque_; // 存放任务的公共队列
std::mutex lock_;
};
#endif //MC_THREAD_POOL_WORKSTEALINGQUEUE_H
优先级任务
哈哈,想不到吧,线程池中的任务也可以群分以类聚。很明显任务可以分成不同的优先级,也就是执行顺序的不同,谁优先执行,谁后来执行。优化思路很简单,我们可以设置不同的队列盛放不同的优先级任务,但是这种方式会对Work Steal机制提出挑战,采用这种方式意味着我们需要用更多的性能开销去做队列的排序,这与我们的初衷是相反的。
如下图:

另一个可行的方案就是项目中所写的,我们可以多设置一个参数用于排列任务优先级,这里设置一个int整数作为优先级排序标志。代码如下(详细代码见于github):
//
// Created by 34435 on 2024/9/28.
//
/*
* @Description: 线程安全的优先队列
* */
#ifndef MC_THREAD_POOL_ATOMICPRIORITYQUEUE_HPP
#define MC_THREAD_POOL_ATOMICPRIORITYQUEUE_HPP
#include <E:/Boost/boost_1_86_0/boostcore/noncopyable.hpp>
#include <queue>
#include <mutex>
#include <condition_variable>
#include "QueueDefine.h"
#include "../../../SBasic/Operator.h"
template<typename T>
class __attribute__((unused)) AtomicPriorityQueue : boost::noncopyable {
AtomicPriorityQueue() = default;
public:
/*
* @param: 检测队列是否为空
* */
__attribute__((unused)) bool empty() {
std::lock_guard<std::mutex> lock(mutex_);
return priority_queue_.empty();
}
/*
* @param: 向队列中添加一个任务
* */
__attribute__((unused)) bool push(char priority, std::unique_ptr<T>& ptr) {
{
std::unique_lock<std::mutex> lock(mutex_);
priority_queue_.push(priority, std::move(ptr));
}
cv_.notify_one();
}
/*
* @param: 尝试弹出一个任务
* */
__attribute__((unused)) bool tryPop(T& value) {
std::unique_lock<std::mutex> lock(mutex_);
if (priority_queue_.empty()) {
return false;
}
value = std::move(priority_queue_.top().second);
priority_queue_.pop();
return true;
}
/*
* @param: 尝试弹出一组任务
* */
__attribute__((unused)) bool tryPop(std::vector<T>& values, int maxPoolBatchSize) {
std::unique_lock<std::mutex> lock(mutex_);
if (priority_queue_.empty()) {
return false;
}
while (!priority_queue_.empty() && maxPoolBatchSize-- >= 0) {
values.emplace_back(priority_queue_.top().second);
priority_queue_.pop();
}
return true;
}
private:
std::mutex mutex_;
std::priority_queue<char, std::unique_ptr<T>, Compare> priority_queue_;
std::condition_variable cv_;
};
#endif //MC_THREAD_POOL_ATOMICPRIORITYQUEUE_HPP
缓存机制
参考java的线程池缓存机制,这里和java的原理类似。
考虑到任务流工作的需要,我们在写入任务的时候,不免有时会传入大量的任务,甚至远超出程序的承载力,那么如何提升程序的负载能力呢,大家有学过python的应该知道python中的迭代器,当然不止python,c++等很多语言也有。迭代器是通过将传入的数据写入缓存,当需要时系统会从缓存中加载入内存中,这样就避免了大量传入数据直接进入内存造成的负载。
同样的c++线程池我们也可以实现一下。承载线程池缓存的容器,显而易见就几个-结构体-vector容器-queue队列,选哪个好?考虑到我们需要便捷的写入和读出任务,所以我们当采用queue队列才能实现效率和性能的最大化。
写一个AtomicRingBufferQueue(环形缓存队列)。线程池运行时,我们向里面传入任务缓存起来,那么我们可以无限放入嘛?缓存没有上限嘛?当然不是,我们可以设置一个缓存空间的最大任务数量,当传入的任务缓存满时,我们可以让后面的任务等一等不要着急,当任务队列中的任务减少的时候,我们就让缓存队列中的任务读出加入任务队列,同时写入新的任务。
如下图:

当缓存队列满时,我们可以继续写入任务去覆盖tail的旧任务。代码如下:
//
// Created by 34435 on 2024/9/30.
//
/*
* @Description: 仅支持单入单出模式的队列
* */
#ifndef MC_THREAD_POOL_ATOMICRINGBUFFERQUEUE_H
#define MC_THREAD_POOL_ATOMICRINGBUFFERQUEUE_H
#include <E:/Boost/boost_1_86_0/boost/core/noncopyable.hpp>
#include <queue>
#include <mutex>
#include "QueueDefine.h"
#include <condition_variable>
template<typename T>
class __attribute__((unused)) AtomicRingBufferQueue : boost::noncopyable {
public:
__attribute__((unused)) explicit AtomicRingBufferQueue(size_t size = 20) : buffer_(size), head_(0), tail_(0), full_(false), empty_(false) {}
__attribute__((unused)) bool push(std::unique_ptr<T>& value) {
{
std::unique_lock<std::mutex> lock(mutex_);
if (full_) {
head_ = (head_ + 1) % MAX_BUFFER_SIZE;
tail_ = (tail_ + 1) % MAX_BUFFER_SIZE;
buffer_[tail_] = std::move(value);
}
tail_ += 1;
buffer_[tail_] = std::move(value);
if (tail_ % MAX_BUFFER_SIZE == head_ % MAX_BUFFER_SIZE) full_ = true;
}
cv_.notify_one();
return true;
}
__attribute__((unused)) bool tryPop(T& value) {
std::unique_lock<std::mutex> lock(mutex_);
if (empty_) return false;
value = std::move(buffer_[head_]);
head_ = (head_+1) % MAX_BUFFER_SIZE;
full_ = false;
if (tail_ == head_) empty_ = true;
return true;
}
private:
std::deque<T> buffer_;
std::mutex mutex_;
std::condition_variable cv_;
bool full_;
size_t head_;
size_t tail_;
bool empty_;
};
#endif //MC_THREAD_POOL_ATOMICRINGBUFFERQUEUE_H
Local Thread机制
线程在执行的时候,开销最大的是什么呢?对cpu影响最大的是什么呢?对线程池性能影响最大的是什么呢?答案显而易见,是创建和销毁线程。试想一下我在某个程序中应用该线程池,如果我的线程池的初始化状态就是一个线程都没有,都需要一个一个开始创建;而任务结束的时候就一个接一个的去销毁线程-------》》》那所造成的性能消耗无法想象的!!!
所以我们需要需要在线程池开始运行的时候,不论是否有任务,我们都要开启10个或者15个初始化线程,让他while(true)一直运行,知道线程池结束才关闭。
第一种情况:
- 当我们传入的任务数量超出了初始化线程数量的几倍的时候。这个时候我们需要根据当前系统的cpu核数和配置以及任务的数量,去增加一些线程辅助初始化线程池完成任务;
- 不同的是,这些辅助线程需要在任务结束时就立即销毁,系统持续运行过多的线程会导致内存泄漏的不可预见的状况。
第二种情况:
- 当我们突然传入非常多的任务时候(常见于批量传入任务),系统负荷大幅度增加,我们的初始化线程和第一种情况的辅助线程都无法第一时间在短时间内完成。这时候怎么办呢?
- 可以再加几个线程嘛~,我们可以设置几个线程的数量区间和两个函数A和B,A时刻监测任务的数量,B时刻监测线程的数量,将二者对比,时刻动态调整线程的数量以应对不同的状况。
代码如下(详细代码见github):
//
// Created by 34435 on 2024/10/8.
//
#ifndef MC_THREAD_POOL_RUNNINGTHREAD_H
#define MC_THREAD_POOL_RUNNINGTHREAD_H
#include <E:/Boost/boost_1_86_0/boost/core/noncopyable.hpp>
#include <chrono>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <atomic>
#include <future>
#include "ThreadDefine.h"
#include "D:\C++_PROJECT\MC_thread_pool\TaskFlow\UtilsCtrl\ThreadPool\Queue\WorkStealingQueue.h"
#include "D:\C++_PROJECT\MC_thread_pool\TaskFlow\UtilsCtrl\ThreadPool\Queue\AtomicPriorityQueue.hpp"
#include "D:\C++_PROJECT\MC_thread_pool\TaskFlow\UtilsCtrl\ThreadPool\Queue\AtomicRingBufferQueue.h"
#include "D:\C++_PROJECT\MC_thread_pool\TaskFlow\UtilsCtrl\ThreadPool\Queue\AtomicQueue.h"
#include "PrimaryThread.hpp"
#include "ThreadDefine.h"
#include "D:\C++_PROJECT\MC_thread_pool\TaskFlow\SBasic\TypeConver.hpp"
template<typename T>
class __attribute__((unused)) RunningThread : boost::noncopyable {
public:
RunningThread() = default;
~RunningThread() = default;
__attribute__((unused)) int monitorThread() {
const int& primaryThread_num = DWORD_INT(PRIMARYTHREAD::threads_.size());
const int& runningThread_num = DWORD_INT(RUNNINGTHREAD::threads_.size());
const int& ALLNUM = primaryThread_num + runningThread_num;
if (ALLNUM >= RUNNINGTHREAD::RUNNINGTHREAD_MAX) {
}
return ALLNUM;
}
__attribute__((unused)) bool monitorTask() {
const int& PRE_NUM = 0;
while (true) {
std::this_thread::sleep_for(std::chrono::milliseconds(500));
const int& CUR_NUM = ALLTHREAD::tasks_.size();
const int& THREAD_NUM = monitorThread();
if (CUR_NUM - PRE_NUM <= 0) {
continue;
}
if (CUR_NUM - PRE_NUM >= 0 && CUR_NUM - PRE_NUM <= 2*PRIMARYTHREAD::PRIMARYTHREAD_MAX) {
primary_thread_->startThread(PRIMARYTHREAD::PRIMARYTHREAD_MAX);
}
if (CUR_NUM - PRE_NUM > 2*PRIMARYTHREAD::PRIMARYTHREAD_MAX && CUR_NUM - PRE_NUM <= 2*RUNNINGTHREAD::RUNNINGTHREAD_MIN) {
primary_thread_->startThread(PRIMARYTHREAD::PRIMARYTHREAD_MAX - THREAD_NUM);
}
if (CUR_NUM - PRE_NUM > 2*RUNNINGTHREAD::RUNNINGTHREAD_MIN && CUR_NUM - PRE_NUM <= 2*RUNNINGTHREAD::RUNNINGTHREAD_MAX) {
primary_thread_->startThread(RUNNINGTHREAD::RUNNINGTHREAD_MIN - THREAD_NUM);
}
if (CUR_NUM - PRE_NUM > 2*RUNNINGTHREAD::RUNNINGTHREAD_MAX) {
primary_thread_->startThread(RUNNINGTHREAD::RUNNINGTHREAD_MAX - THREAD_NUM);
}
if (CUR_NUM - PRE_NUM >= 3*RUNNINGTHREAD::RUNNINGTHREAD_MAX) {
primary_thread_->startThread(ALLTHREAD::THREADPOOLMAX - THREAD_NUM);
}
PRE_NUM = CUR_NUM;
}
}
template<typename Q>
__attribute__((unused)) int monitorQueue(std::queue<Q> QUEUE) {
const int& QUEUESIZE = DWORD_INT(QUEUE.size());
return QUEUESIZE;
}
private:
WorkStealingQueue<T>* WS_primary_queue_; // 初始偷窃队列
WorkStealingQueue<T>* WS_secondary_queue_; // 第二辅助队列,加快速度
AtomicPriorityQueue<T>* AP_primary_queue_; // 初始优先队列
AtomicRingBufferQueue<T>* ARB_primary_queue_; // 初始环形缓冲队列
AtomicQueue<T>* A_primary_queue_; // 初始队列
const int& cur_TTL; // 当前线程的最大生存周期
PrimaryThread<T>* primary_thread_; // 初始线程
protected:
friend AtomicPriorityQueue<T>;
friend WorkStealingQueue<T>;
friend AtomicRingBufferQueue<T>;
friend AtomicQueue<T>;
friend PrimaryThread<T>;
};
#endif //MC_THREAD_POOL_RUNNINGTHREAD_H
Lock Free机制
容量动态调整机制
[^该机制就不详述了,简短说一下,该机制已经嵌入在Local Thread机制中的第二种情况中说明过了。]: 该机制就不详述了,简短说一下,该机制已经嵌入在Local Thread机制中的第二种情况中说明过了。
在任务繁忙的时候,pool中多加入几个thread;而在清闲的时候,对thread进行自动回收
如何判断pool是忙还是闲?可以使用running标记的方法 + TTL(time to live)计数的方法。除了PT和ST,pool中还开辟了一个monitor Thread(监控线程,简称MT)。MT每隔固定的时间,会去轮询监测所有的PT是否都在运行状态。如果是,就认定当前pool处于忙碌状态,则添加一个ST帮忙分担任务执行。同样的,MT还会去监测每个ST的状态。如果连续TTL次监测到ST没有在执行任务,则认为pool处于空闲状态,则会销毁当前ST
值得注意的是,有一些文章中给出了一些预估开辟线程的最佳数量:
- 计算密集型任务,开辟
n或n+1个(其中,n=cpu核数)线程数 - IO密集型任务,开辟2n +1个
甚至还有公式:
- 最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
但是,实践是检验真理的唯一标准,判断开辟多少个线程才是最佳数量,需要我们去实验,火焰图还是很好用的!
批量处理机制
其实,线程池优化的本质:就是增加扇入扇出。为了在这一点上做到更优,从队列中获取任务的时候,提供了批量获取tasks的功能。,PT和ST在从queue中获取/盗取task的时候,就不再是one by one的获取,而是batch by batch的获取。这样做的最大好处,是可以减少线程获取task时候,争抢锁的次数,从而提升性能。
需要说明的是,真实的多线程情况远比我们刚才讨论的复杂。现代计算机的调度理论何其深奥,我们无法穷尽其中奥秘。而多线程自身又有很多的不确定性。所以,具体采用哪种执行策略,还是尽可能的去模拟真实环境进行实测和压测
负载均衡机制
这点本人就不详细阐述了,最大的原因是本人对于负载均衡机制并不是很了解和使用,在本线程池中,也只是将一部分任务均匀的写入PT的queue中,另一部分统一放到pool的queue中。但是即使是这样写,线程池的性能也比其他的线程池性能提升了不少
避免等待
线程池中我们应用了yied(),不了解的可以去bing一下,yied()主要是用于当当前线程执行任务时,任务被mutex了,这时使用yied()可以让mutex释放,让当前线程取出任务后再进行原来的操作,让cpu让出执行权。如果不使用会导致阻塞,知道mutex被释放。
mutex被其他的线程占着。这个时候,是等着抢到锁之后再进行接下来的操作,还是直接让出当前线程的执行权,过n个时间片再来重新尝试一次?我想绝大部分情况下,应该选择后者。而yield()函数的用途,就是使得当前线程让出cpu执行权
预测优化
线程池在初始化的时候禁止线程池Work Steal!
减少不必要的复制
大多数人都知道,在编程中,复制的消耗也是不小的,所有单独抽取出来进行优化,也很简单。我们可以使用完美转换来优化,利用std::move和std::forward来进行所有权的移交
此处的std::move和std::forward,可以看看这篇文章),讲的很好
拒绝机制
- 注意:该机制在本线程池中并未实现!!!!!!!!!!!!!!!!!!!!!!!!!!!
线程池面对大量的任务需求,也要学会拒绝啊~,不然会坏掉的QAQ
任务写入threadpool中,是瞬间的动作,但是有些任务执行起来就需要很长的时间,比如:sleep(100);。当线程池中源源不断的写入大量任务,却无法及时消费的时候,是可能引发各种意想不到的问题,甚至程序崩溃的。所以,一个优秀的线程池中还应该有拒绝策略。
拒绝策略又可以区分为严格的拒绝策略和宽松的拒绝策略。严格,主要体现在写入任务的瞬间,如果pool中的任务数量正好是1爽的时候,就拒绝;宽松,就可以是pool中的任务数量超过1爽之后的若干秒后,pool开始拒绝外部写入,直到其中任务被消费到小于1爽之后的若干秒后,又恢复正常。
cas机制
- 注意:该机制在本线程并未实现!!!!!!!!!!!!!!!!!!!!!!!!!!!!
cas机制是一种无锁编程技术
超时处理
遇到跑线程任务的时候,总有些不可预知的情况(比如,数据库慢查询),导致个别任务很慢,而上游一直在等待返回结果。甚至有可能,多个慢的任务,导致上游功能层的流程完全阻塞了。
为了避免这种情况,我们需要对单个线程的执行时间,做一个时间限定,比如:当前任务不能超过 3000ms,如果超过,就结束阻塞,并且返回错误信息,这有点像计算机网络中的超时机制。
但是需要注意一点:在上文中我们提到过一个初始化thread,该thread是在while(true)中的,不要再其中用超时机制,因为这是无效的,并且线程是正常运行的,资源是不会释放的
任务组
线程池一般都用来处理批量任务。在前面的内容中,我们也都是通过for循环的方式,将一堆任务放到线程池中执行。考虑下面几个问题:
- 我想等这一批任务执行结束,再执行其他的任务,怎么办?
- 我想给这一批任务,设定一个统一的等待时长,怎么办?
- 我想在多批任务执行结束的时候,固定执行某个回调逻辑,怎么办?
任务组的设计,主要就是为了方便对多任务的管理。使得多个任务,表现出一些统一的特性(比如,这一批任务最多执行 5秒),也方便后期的复用和移植。
任务组还可以设定结束时候的回调哦!
代码如下(完整代码见github):
//
// Created by 34435 on 2024/9/30.
//
/*
* @Description: 安全队列
* */
#ifndef MC_THREAD_POOL_ATOMICQUEUE_H
#define MC_THREAD_POOL_ATOMICQUEUE_H
#include <E:/Boost/boost_1_86_0/boost/core/noncopyable.hpp>
#include <queue>
#include <mutex>
#include <condition_variable>
template<typename T>
class __attribute__((unused)) AtomicQueue : boost::noncopyable {
AtomicQueue() = default;
public:
__attribute__((unused)) bool empty() {
std::lock_guard<std::mutex> lock(mutex_);
return queue_.empty();
}
__attribute__((unused)) bool push(std::unique_ptr<T>& ptr) {
{
std::unique_lock<std::mutex> lock(mutex_);
queue_.push(std::move(ptr));
}
cv_.notify_one();
}
/*
* @param: 尝试弹出一个任务
* */
__attribute__((unused)) bool tryPop(T& value) {
std::unique_lock<std::mutex> lock(mutex_);
if (queue_.empty()) {
return false;
}
value = std::move(queue_.front());
queue_.pop();
return true;
}
/*
* @param: 尝试弹出一组任务
* */
__attribute__((unused)) bool tryPop(std::vector<T>& values, int maxPoolBatchSize) {
std::unique_lock<std::mutex> lock(mutex_);
if (queue_.empty()) {
return false;
}
while (!queue_.empty() && maxPoolBatchSize-- > 0) {
values.emplace_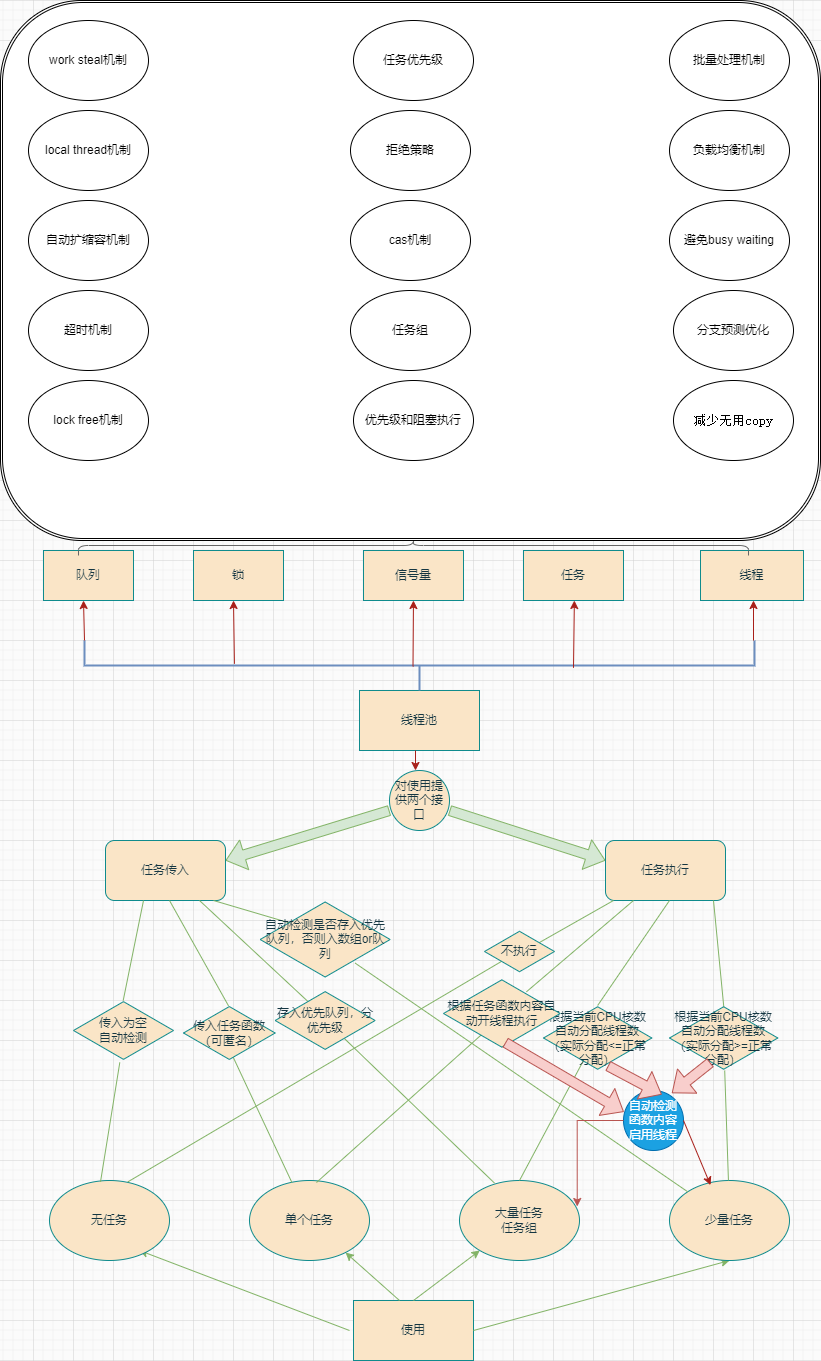
back(std::move(queue_.front()));
queue_.pop();
}
return true;
}
private:
std::mutex mutex_;
std::queue<std::unique_ptr<T>> queue_;
std::condition_variable cv_;
};
#endif //MC_THREAD_POOL_ATOMICQUEUE_H
项目图解


