[seq2seq]论文实现:Effective Approaches to Attention-based Neural Machine Translation(上)https://developer.aliyun.com/article/1504074?spm=a2c6h.13148508.setting.41.36834f0eMJOehx
二、论文解读
2.1 RNN模型
介绍seq2seq之前我们需要介绍一下RNN模型,RNN模型表示循环神经网络,具有代表性的有SimpleRNN,GRU,LSTM;其基本实现原理如图:

用公式表达如下:

其中 W , U , V 三者权重是共享的,所有RNN的参数数量是与 Xt的最后一个维度有关的,维度变化公式如下:

























 O[outputdim∗1]=V[outputdim∗units]·S[units∗1]+B[outputdim∗1]S[units∗1]=U[units∗xdim]·X[xdim∗1]+W[units∗units]·S[units∗1]+B[units∗1])
O[outputdim∗1]=V[outputdim∗units]·S[units∗1]+B[outputdim∗1]S[units∗1]=U[units∗xdim]·X[xdim∗1]+W[units∗units]·S[units∗1]+B[units∗1])
所以,RNN需要的参数数量为(units+x_dim+1)*units + (units+1)*output_dim
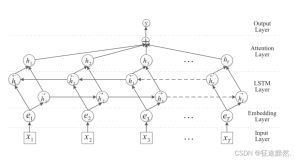
2.2 Attention-based Models
论文中提出了两种Attention-based Model,分别是全局注意力模型和局部注意力模型;其结构图如下:

从图中可以看到,其全局和局部的区别在于 a t a_t at 和 c t c_t ct 的不同,在分析之前,我们先定义一些变量: t t t 是时间步, a t a_t at 是模型对其权重向量,其主要是由于 h t h_t ht 和 h ‾ s \overline h_s hs计算得到, h s ‾ \overline{h_s} hs 是decoder中第s位置的state, c t c_t ct 被称作为内容向量,由 a t a_t at 和 h s ‾ \overline{h_s} hs计算得到;
接下来我们依次对全局注意力和局部注意力进行分析;
Global attentional model
如图,ct 是由 at 和 hs 计算得到,这里首先定义 at(s)的计算公式为:

















 at(s)=align(ht,hs¯)=exp(score(ht,hs¯))∑s′exp(score(ht,hs′¯))
at(s)=align(ht,hs¯)=exp(score(ht,hs¯))∑s′exp(score(ht,hs′¯))
论文中这里定义  有三种方式:
有三种方式:
KaTeX parse error: Undefined control sequence: \cases at position 32: …rline{h_s}) = \̲c̲a̲s̲e̲s̲{ h_t^T\overlin…
这里用query, key,value 来解释就相当于 ht 做 query ,  做 key 和 value;其流程为
做 key 和 value;其流程为 
Local attentional model
全局注意力机制有一个缺点,即它必须关注每个目标词的源端的所有单词,这是昂贵的,并可能使翻译更长的序列不切实际,例如段落或文档。这里使用局部注意力机制进行优化;
所谓局部注意力机制就是说我们不去计算所有位置,而是计算部分位置,那么这部分位置该怎么选择呢,在语言翻译模型中,某部分的target是由某部分的source构成的,在已知target的位置 t 时找到source的位置pt 论文中有两种方式取实现:
- Monotonic alignment : pt=t
- Predictive alignment :

这里的 vp,Wp都是参数;
在找到 pt 之后,我们对 [pt−D,pt+D]这些位置上的 hs 进行注意力机制计算 at,ct;
同时由于词距离pt 越远,则其影响越弱,这里论文中使用高斯分布的方式对 at取值:取值方式如下:

根据经验我们一般把 a σ 设置为  ,这就是局部注意力机制;
,这就是局部注意力机制;
2.3 Input-feeding Approach
在全局和局部注意力模型中,其注意力部分都是独立进行的,并没有对下一个时间步的过程产生影响,这并不合理,在标准的MT中,通常在翻译过程中会维护一个覆盖集,以跟踪哪些源词已经被翻译过。同样地,在注意nmt中,对齐决策应该共同考虑到过去的对齐信息。我们可以优化一下,把每次的输出作为下一个时间步的输入;如图所示:

2.4 模型效果
论文中模型效果如图所示:

三、过程实现
3.1 导包
这里要用到的包有:tensorflow, keras_nlp, matplotlib, numpy
import tensorflow as tf import keras_nlp import matplotlib.pyplot as plt import numpy as np plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False
3.2 数据准备
这里使用的是中英文翻译数据集,进行清洗和dataset构造
# 数据处理 def process_data(x): res = tf.strings.split(x, '\t') return res[1], res[3] # 导入数据 dataset = tf.data.TextLineDataset('./data/transformer_data.tsv') dataset = dataset.map(process_data) # 建立中英文wordpiece词表 vocab_chinese = keras_nlp.tokenizers.compute_word_piece_vocabulary( dataset.map(lambda x, y: x), vocabulary_size=20_000, lowercase=True, strip_accents=True, split_on_cjk=True, reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"], ) vocab_english = keras_nlp.tokenizers.compute_word_piece_vocabulary( dataset.map(lambda x, y: y), vocabulary_size=20_000, lowercase=True, strip_accents=True, split_on_cjk=True, reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"], ) # 构建分词器 chinese_tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(vocabulary=vocab_chinese, oov_token="[UNK]") english_tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(vocabulary=vocab_english, oov_token="[UNK]") # 再进行一次数据处理 def process_data_(ch, en, maxtoken=128): ch = chinese_tokenizer(ch)[:,:maxtoken] en = english_tokenizer(tf.strings.lower(en))[:,:maxtoken] ch = tf.concat([tf.ones(shape=(64,1), dtype='int32'), ch, tf.ones(shape=(64,1), dtype='int32')*2], axis=-1).to_tensor() en = tf.concat([tf.ones(shape=(64,1), dtype='int32'), en, tf.ones(shape=(64,1), dtype='int32')*2], axis=-1) en_inputs = en[:, :-1].to_tensor() # Drop the [END] tokens en_labels = en[:, 1:].to_tensor() # Drop the [START] tokens return (ch, en_inputs), en_labels dataset = dataset.batch(64).map(process_data_) train_dataset = dataset.take(1000) val_dataset = dataset.skip(500).take(300) # 数据准备完毕 查看数据 for (pt, en), en_labels in dataset.take(1): break print(pt.shape) print(en.shape) print(en_labels.shape)
3.3 构建相关类
encoder:
class Encoder(tf.keras.layers.Layer): def __init__(self, vocabulary_size, d_model, units): super().__init__() self.embedding = tf.keras.layers.Embedding(vocabulary_size, d_model) self.rnn = tf.keras.layers.Bidirectional( layer=tf.keras.layers.LSTM(units=units, return_sequences=True, return_state=False), merge_mode='sum' ) def call(self, inputs): x = inputs x = self.embedding(x) x = self.rnn(x) return x
crossattention:
class CrossAttention(tf.keras.layers.Layer): def __init__(self, units, **kwargs): super().__init__() self.mha = tf.keras.layers.MultiHeadAttention(key_dim=units, num_heads=1, **kwargs) self.add = tf.keras.layers.Add() self.norm = tf.keras.layers.LayerNormalization() def call(self, inputs): x, context = inputs attention_out, attention_score = self.mha(query=x, value=context, key=context, return_attention_scores=True) self.last_attention_score = attention_score x = self.add([x, attention_out]) x = self.norm(x) return x
decoder:
class Decoder(tf.keras.layers.Layer): def __init__(self, vocabulary_size, d_model, units, **kwargs): super().__init__() self.embedding = tf.keras.layers.Embedding(vocabulary_size, d_model) self.rnn = tf.keras.layers.LSTM(units, return_sequences=True) self.attention = CrossAttention(units, **kwargs) self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax') def call(self, inputs): x, context = inputs x = self.embedding(x) x = self.rnn(x) x = self.attention((x, context)) x = self.dense(x) return x
seq2seq:
class Seq2Seq(tf.keras.models.Model): def __init__(self, vocabulary_size_1, vocabulary_size_2, d_model, units, **kwargs): super().__init__() self.encoder = Encoder(vocabulary_size=vocabulary_size_1, d_model=d_model, units=units) self.decoder = Decoder(vocabulary_size=vocabulary_size_2, d_model=d_model, units=units) def call(self, inputs): pt, en = inputs context = self.encoder(pt) output = self.decoder((en, context)) return output
3.4 模型配置
构建模型如下:
seq2seq = Seq2Seq(chinese_tokenizer.vocabulary_size(), english_tokenizer.vocabulary_size(), 512, 30) # build model seq2seq((pt, en)) seq2seq.summary()
模型配置:
def masked_loss(y_true, y_pred): loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none') loss = loss_fn(y_true, y_pred) mask = tf.cast(y_true != 0, loss.dtype) loss *= mask return tf.reduce_sum(loss)/tf.reduce_sum(mask) def masked_acc(y_true, y_pred): y_pred = tf.argmax(y_pred, axis=-1) y_pred = tf.cast(y_pred, y_true.dtype) match = tf.cast(y_true == y_pred, tf.float32) mask = tf.cast(y_true != 0, tf.float32) return tf.reduce_sum(match)/tf.reduce_sum(mask) seq2seq.compile( optimizer='adam', loss=masked_loss, metrics=[masked_acc, masked_loss] ) seq2seq.fit(train_dataset, epochs=10, validation_data=val_dataset)
模型训练结果如下:

作图:
plt.plot(seq2seq.history.history['masked_loss'], label='loss') plt.plot(seq2seq.history.history['val_masked_loss'], label='val_loss') plt.plot(seq2seq.history.history['masked_acc'], label='accuracy') plt.plot(seq2seq.history.history['val_masked_acc'], label='val_accuracy')
3.5 模型推理
构建推理类:
class Inference(tf.Module): def __init__(self, model, tokenizer_1, tokenizer_2): self.model = model self.tokenizer_1 = tokenizer_1 self.tokenizer_2 = tokenizer_2 def __call__(self, sentence, MAX_TOKEN=128): assert isinstance(sentence, tf.Tensor) if len(sentence.shape) == 0: sentence = sentence[tf.newaxis] sentence = self.tokenizer_1(sentence) sentence = tf.concat([tf.ones(shape=[sentence.shape[0], 1], dtype='int32'), sentence, tf.ones(shape=[sentence.shape[0], 1], dtype='int32')*2], axis=-1).to_tensor() encoder_input = sentence start = tf.constant(1, dtype='int64')[tf.newaxis] end = tf.constant(2, dtype='int64')[tf.newaxis] # tf.TensorArray 类似于python中的列表 output_array = tf.TensorArray(dtype=tf.int64, size=0, dynamic_size=True) # 在index=0的位置写入start output_array = output_array.write(0, start) for i in tf.range(MAX_TOKEN): output = tf.transpose(output_array.stack()) predictions = self.model.predict((encoder_input, output), verbose=0) # Shape `(batch_size, seq_len, vocab_size)` # 从seq_len中的最后一个维度选择last token predictions = predictions[:, -1:, :] # Shape `(batch_size, 1, vocab_size)`. predicted_id = tf.argmax(predictions, axis=-1) # `predicted_id`加入到output_array中作为一个新的输入 output_array = output_array.write(i+1, predicted_id[0]) # 如果输出end就表明停止 if predicted_id == end: break output = tf.squeeze(output_array.stack()) output = self.tokenizer_2.detokenize(output) return output
开始推理:
inference = Inference(seq2seq, chinese_tokenizer, english_tokenizer) sentence = '你好呀' sentence = tf.constant(sentence) inference(sentence) # 输出 # <tf.Tensor: shape=(), dtype=string, numpy=b"[START] hello ! [END]">
四、整体总结
效果还不错!训练一定时长后能够正确的翻译,好像相较于Transformer逊色了一点,但是毕竟这个模型结构比Transformer早两年;