Sharding-JDBC是一个轻量级、无中心化、高性能的Java数据库分片框架。它通过在Java的JDBC层进行扩展,实现了SQL的分片功能,而无需对业务代码做任何更改。以下是V 哥整理的Sharding-JDBC分片的案例,主要通过以下几个步骤实现分片:
1. 引入Sharding-JDBC依赖
首先,需要在项目的pom.xml文件中添加Sharding-JDBC的依赖。
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.x.x</version> <!-- 使用最新版本 -->
</dependency>
2. 配置分片规则
分片规则是Sharding-JDBC的核心,它定义了如何将数据分片存储到不同的数据库中。分片规则包括数据源配置、分片策略、表规则和绑定表规则等。
示例配置
import io.shardingsphere.api.config.sharding.ShardingRuleConfiguration;
import io.shardingsphere.api.config.sharding.TableRuleConfiguration;
import io.shardingsphere.api.config.sharding.strategy.StandardShardingStrategyConfiguration;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
public class ShardingConfig {
public DataSource createDataSource() throws SQLException {
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds0", createDataSource("ds0"));
dataSourceMap.put("ds1", createDataSource("ds1"));
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
// 配置分片策略
shardingRuleConfig.getTableRuleConfigs().add(tableRuleConfiguration());
// 添加分片策略
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", "database_inline"));
// 绑定表,如果需要
shardingRuleConfig.setBindingTableGroupsList(Collections.singletonList(Arrays.asList("order", "order_item")));
// 创建ShardingDataSource
ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig);
}
private DataSource createDataSource(String dataSourceName) {
// 实际上这里需要根据实际情况创建数据源,这里只是示意
return null;
}
private TableRuleConfiguration tableRuleConfiguration() {
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration();
tableRuleConfig.setLogicTable("order");
tableRuleConfig.setActualDataNodes("ds${0..1}.order_${0..1}");
return tableRuleConfig;
}
}
3. 编写分片策略
分片策略定义了分片的逻辑,比如根据某个字段的值将数据分配到不同的数据库或表中。Sharding-JDBC支持多种分片策略,如固定分片、范围分片、哈希分片等。
示例:使用行表达式分片策略
// 假设我们根据user_id进行分片,分配到两个数据库ds0和ds1中
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(
new StandardShardingStrategyConfiguration("user_id", "database_inline")
);
// 行表达式分片策略,使用"ds${0..1}"表示两个数据源ds0和ds1
shardingRuleConfig.setDefaultTableShardingStrategyConfig(
new StandardShardingStrategyConfiguration("order_id", "table_inline")
);
4. 使用ShardingDataSource
在业务代码中,使用ShardingDataSource代替原生的DataSource。
DataSource dataSource = new ShardingConfig().createDataSource();
5. 执行分片操作
使用ShardingDataSource创建连接,执行SQL操作时,Sharding-JDBC会自动根据分片规则对SQL进行改写和路由。
String sql = "SELECT * FROM order WHERE user_id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, 123);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
// 处理结果集
}
}
}
6. 示例解释
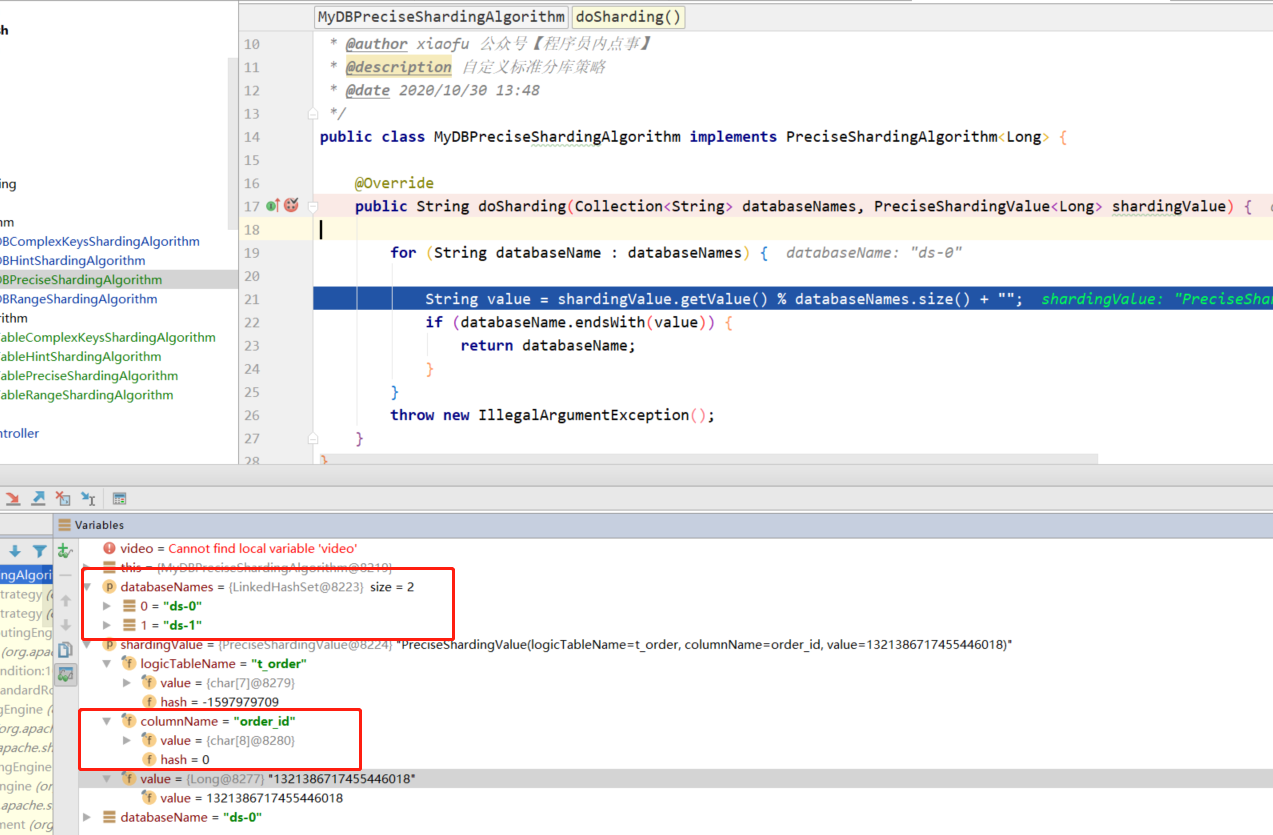
- 数据源配置:定义了两个真实的数据库连接池,分别命名为ds0和ds1。
- 分片规则:定义了order表的分片规则,数据将根据order_id字段的值分配到不同的表order_0或order_1中。
- 分片策略:使用行表达式分片策略,根据user_id的值决定数据存储到哪个数据库中。
- 绑定表:如果有多个表共享相同的分片策略,可以定义为绑定表,以优化性能。
以上是V 哥在教学过程中实现分片的示例步骤,Sharding-JDBC能够实现SQL的分片操作,将请求路由到正确的数据库和表中,从而实现数据的水平扩展,这是在使用例如 MySQL作为数据库的场景中经常会使用到的,但如果你的企业正在考虑分布式数据库迁移,V 哥建议可以考虑 TiDB 或 OceanBase 这样的分布式数据库,因为它们天然就支持分布式,而不需要考虑这些。