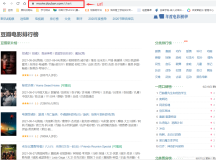
查看网页
歌名

表演者

特点
都是在<span class="pl">里面,可以使用正则表达式提取出来
正则提取
对html的节点进行提取
#正则提取风格、时间、出版人 findStyle=re.compile(r'<span class="pl">流派:</span> (.*?)<br />',re.S)# re.S忽略换行 findTime=re.compile(r'<span class="pl">发行时间:</span> (.*?)<br />',re.S) findPublish=re.compile(r'<span class="pl">出版者:</span> (.*?)<br />',re.S)
实现
import requests,time,urllib.request,urllib from bs4 import BeautifulSoup #需要安装xlml库 import csv,re #正则提取风格、时间、出版人 findStyle=re.compile(r'<span class="pl">流派:</span> (.*?)<br />',re.S)# re.S忽略换行 findTime=re.compile(r'<span class="pl">发行时间:</span> (.*?)<br />',re.S) findPublish=re.compile(r'<span class="pl">出版者:</span> (.*?)<br />',re.S) headers={ "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36" } def get_url_music(filename,url):#访问url,提取出链接 html=requests.get(url,headers=headers) soup=BeautifulSoup(html.text,'lxml') # aTags=soup.find_all('a',attrs={'class':'nbg'})#链接 for aTag in aTags: new=aTag['href'] get_music_info(filename,new)#调用 return True def get_music_info(filename,url):#进入链接 html=requests.get(url,headers=headers) htmlText=html.text print(htmlText) soup=BeautifulSoup(htmlText,'lxml') # name=soup.find(attrs={'id':'wrapper'}).h1.span.text#歌名 author=soup.find(attrs={'id':'info'}).find('a').text#发行者 styles=re.findall(findStyle,htmlText)[0]#风格 styles=re.sub('<br(\s+)?/>(\s+)?','',styles) styles = re.sub('/', ' ', styles) styles = "".join(styles.split())#前后空格 # styles = re.findall('<span class="pl">流派:</span> (.*?)<br/>',htmlText) # 风格 style = '未知' if len(styles)==0 else styles#处理前后空格 time=re.findall(findTime,htmlText)[0]#时间 time="".join(time.split()) publishers=re.findall(findPublish,htmlText) publisher='未知' if len(publishers)==0 else publishers[0].strip() info={ 'name':name, 'author':author, 'style':style, 'time':time, 'publisher':publisher }#结果字典数据 print(info) save_csv(filename,info)#保存数据 return info def save_csv(filename,info):#写入每一列的数据 with open(filename,'a',encoding='utf-8') as f: fieldnames=['name','author','style','time','publisher'] writer=csv.DictWriter(f,fieldnames=fieldnames)#列数据 writer.writerow(info) if __name__=='__main__': urls=['https://music.douban.com/top250?start={}'.format(str(i)) for i in range(0,1,25)] print(urls) filename='douban_music.csv' with open(filename,'w',encoding='utf-8')as f: fieldnames=['name','author','style','time','publisher'] writer=csv.DictWriter(f,fieldnames=fieldnames) # 表头 writer.writeheader() for url in urls: get_url_music(filename,url)#调用 time.sleep(1)#延迟1
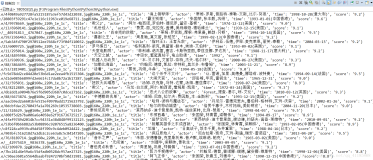
结果


处理换行
添加newlinew
加上newline=''
def save_csv(filename,info):#写入每一列的数据 with open(filename,'a',encoding='utf-8',newline='') as f:# newline解决换行 fieldnames=['name','author','style','time','publisher'] writer=csv.DictWriter(f,fieldnames=fieldnames)#列数据 writer.writerow(info)


代码:我的仓库