Hive 是一个建立在 Hadoop 之上的数据仓库工具,可以将结构化数据映射到 Hadoop 的分布式文件系统上,并提供类似于 SQL 的查询语言(HiveQL)来查询和分析数据。它的主要特点包括分布式存储、扩展性、容错性以及与 Hadoop 生态系统的紧密集成等。在接下来的内容中,我将详细分析 Hive 的特点,并比较其与传统关系型数据库管理系统(RDBMS)的异同之处。
Hive 的特点
1. 分布式存储
Hive 使用 Hadoop 分布式文件系统(HDFS)来存储数据,充分利用了 Hadoop 的分布式存储能力。这使得 Hive 可以处理 PB 级别甚至更大规模的数据,适用于大数据场景。
2. 扩展性
由于 Hive 是建立在 Hadoop 生态系统之上的,因此可以通过简单地增加节点来扩展集群的容量和性能。这种水平扩展的能力使得 Hive 能够应对不断增长的数据量和查询负载。
3. 容错性
Hive 借助 Hadoop 的容错机制,能够在节点故障或其他异常情况下保持系统的稳定性和可靠性。即使在节点发生故障时,Hive 也可以继续工作,并且能够自动重新调度任务。
4. 支持结构化查询语言(HiveQL)
Hive 提供了类似于 SQL 的查询语言(HiveQL),使得用户可以使用熟悉的 SQL 语法来查询和分析数据。这种语言的设计让更多的用户能够轻松地上手并使用 Hive 进行数据处理。
5. 优化查询执行计划
Hive 通过优化查询执行计划来提高查询性能,包括选择合适的执行引擎、使用统计信息进行优化以及支持查询重写等技术。这些优化技术可以有效地提高查询的执行效率和性能。
6. 支持用户自定义函数(UDF)
Hive 允许用户编写自定义函数(UDF),以扩展 HiveQL 的功能。通过编写自定义函数,用户可以在查询中调用自定义的逻辑,从而实现更灵活和复杂的数据处理操作。
7. 紧密集成 Hadoop 生态系统
Hive 与 Hadoop 生态系统中的其他工具和组件紧密集成,包括 HDFS、YARN、HBase、Spark 等,可以方便地与其他工具进行数据交换和集成,实现更加复杂的数据处理和分析任务。
Hive 与 RDBMS 的异同
1. 数据模型
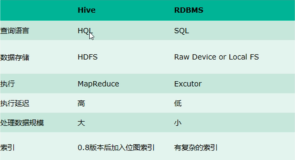
- Hive:Hive 基于 Hadoop 的分布式文件系统,支持非结构化、半结构化和结构化数据,适用于大数据场景。
- RDBMS:RDBMS 使用表格化的数据模型,支持关系型数据和事务处理,适用于小到中型数据的存储和管理。
2. 查询语言
- Hive:Hive 使用类似于 SQL 的查询语言 HiveQL,支持常见的 SQL 操作,但不支持事务、索引等高级特性。
- RDBMS:RDBMS 使用 SQL 作为查询语言,支持事务、索引、外键等高级特性,适用于在线事务处理(OLTP)和在线分析处理(OLAP)。
3. 存储和计算模型
- Hive:Hive 使用分布式存储和计算模型,数据存储在 HDFS 上,计算通过 MapReduce 或 Tez 等引擎进行。
- RDBMS:RDBMS 使用集中式存储和计算模型,数据存储在磁盘上,计算通过数据库管理系统进行。
4. 性能
- Hive:Hive 适用于大规模数据的批量处理和分析,性能通常比较低,适合高延迟、低频率的数据处理任务。
- RDBMS:RDBMS 适用于小规模数据的实时处理和查询,性能通常较高,适合低延迟、高频率的数据处理任务。
5. 数据类型和约束
- Hive:Hive 支持有限的数据类型和约束,包括基本数据类型、复杂数据类型和简单约束。
- RDBMS:RDBMS 支持丰富的数据类型和约束,包括基本数据类型、自定义数据类型和复杂约束。
示例代码片段
以下是一个简单的 HiveQL 查询示例,演示了如何在 Hive 中查询数据:
-- 创建表
CREATE TABLE users (
id INT,
name STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- 插入数据
LOAD DATA LOCAL INPATH '/path/to/data/users.csv' INTO TABLE users;
-- 查询数据
SELECT * FROM users WHERE age > 30;
以上代码片段创建了一个名为 users 的表,插入了一些数据,并执行了一个简单的查询操作。通过这个示例,读者可以了解到如何在 Hive 中创建表、插入数据和执行查询操作。