通过比喻理解-MapReduce的数据处理流程
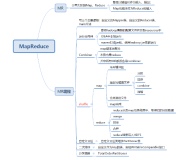
什么是MapReduce
我们把MapReduce比作一场大型的烹饪比赛。
假设你是一位厨师,你的任务是为一场大型的宴会准备食物。你有很多的食材,比如土豆、胡萝卜和鸡肉等。但是,你一个人无法处理这么多的食材,所以你决定招募一些助手来帮助你。
这就是MapReduce的"Map"阶段。在这个阶段,你(主节点)将大任务分解成许多小任务,然后分发给你的助手(工作节点)去完成。比如,你可以让一个助手负责切土豆,让另一个助手负责切胡萝卜,让第三个助手负责切鸡肉。
当所有的助手都完成了他们的任务后,你需要把所有的食材混合在一起,然后烹饪出美味的菜肴。这就是MapReduce的"Reduce"阶段。在这个阶段,你(主节点)会收集所有助手(工作节点)的结果,然后进行最后的处理。
所以,MapReduce的数据处理流程就像一场大型的烹饪比赛,它可以把大任务分解成许多小任务,并行地执行这些任务,然后再把所有的结果汇总。
在Hadoop中,MapReduce被广泛用于各种数据处理任务,比如数据排序、数据统计、机器学习等。它是Hadoop的核心组件,对Hadoop的性能和可扩展性起着关键的作用。
MapReduce的各个流程

MapReduce比作一场大型的图书整理工作。
首先,你有一大堆的图书需要整理,这就是"Input",也就是你需要处理的原始数据。
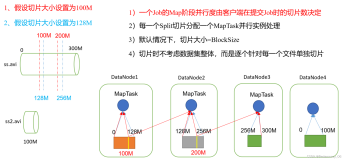
接下来,你需要把这些图书按照类别进行分类,比如科幻、历史、文学等。这就是"Splitting",也就是将原始数据分割成一些较小的数据块。
然后,你会把这些分类的任务分配给你的助手,让他们分别负责不同的类别。这就是"Mapping",也就是将数据块分配给不同的工作节点进行处理。
在所有的图书都被分类之后,你可能会发现一些图书被错误地分类了。比如,一本科幻小说可能被错误地分类到了历史类别。所以,你需要重新调整这些图书的类别,让它们都在正确的类别中。这就是"Shuffling",也就是重新组织数据,以便于后续的处理。
接下来,你会让你的助手对他们负责的类别进行进一步的整理,比如按照作者的姓名进行排序。这就是"Reducing",也就是对数据进行进一步的处理和汇总。
最后,你会得到一本本整齐地排列在书架上的图书,这就是"Final Result",也就是最终的输出结果。
所以,MapReduce的数据处理流程就像一场大型的图书整理工作,它可以把大任务分解成许多小任务,并行地执行这些任务,然后再把所有的结果汇总。