ES ElasticSearch
ES是一款开源的海量数据搜索引擎
mysql5.7采用的是innodb数据结构是b+树,mysql架构是为了存海量数据的,在他执行查询操作时,因为采用的是b+树结构,采取的是正向索引,在进行查询时,会将每行数据查询进行对比,直到找到需要的数据,效率很低,还有再进行模糊查询时,可能会导致索引失效,触发全表扫描,导致查询效率太低
正向索引:查询每一条数据进行对比条件,依次查出自己需要的满足条件的数据id
所以我们引入Es ElasticSearch进行海量数据的查询,底层使用的lucene,
采用倒排索引,将词条列出查询分类,将文档(mysql中的一行数据)进行归纳, 在查询时,直接找到我们的词条,将词条中的文档id返回,查询效率大大提高
Es中的关键字:
文档doc==行数据row
字段filed==列数据column
映射mapping==约束schema
DSL==SQL语句
索引index=table表
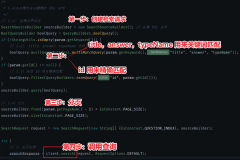
ES中使用restful风格进行数据操作
get一般用于查询doc文档,查询index索引表
put 添加 修改doc文档或者index索引
delete 删除doc文档或者index索引
post 添加doc文档 或者新增index索引字段
ES中不能修改index索引中已经存在的字段,只能新增
创建mapping映射:
type类型:text,long,double,integer,short,keyword,char,byte,float,boolean,data,obj
index关键字:是否在该字段创建索引,默认true
analyzer:使用哪个分词器
properties:子字段
#1.创建员工索引库
PUT /employee
{
"mappings": {
"_doc":{
"properties":{
"age":{
"type":"integer"
},
"weight":{
"type":"double",
"index":false
},
"isMarried":{
"type":"boolean"
},
"info":{
"type":"text",
"analyzer": "ik_smart"
},
"email":{
"type":"keyword",
"index":false
},
"score":{
"type":"double"
},
"name":{
"properties":{
"firstname":{
"type":"text",
"analyzer": "ik_smart"
},
"lastname":{
"type":"text",
"analyzer": "ik_smart"
}
}
}
}
}
}
}
#2.查找索引库
GET /employee
#3.新增索引库字段mapping (不可修改mapping)
PUT /employee/_doc/_mapping
{
"properties":{
"gender":{
"type":"keyword"
}
}
}
#4.删库跑路
DELETE /employee
#文档操作
#1.新增单个文档
PUT /employee/_doc/1
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "我真滴棒棒哒",
"email": "cabcs@163.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "肥",
"lastName": "小"
}
}
#2.查询单个文档
GET /employee/_doc/1
#3.查询所有文档
GET /employee/_doc/_search
#4.更新分为全量更新和增量修改
#4.1全量修改 没有id就是新增 有id底层就是先删除原有的 在新增修改后的数据
PUT /employee/_doc/1
{
"age": 22,
"weight": 52.1,
"isMarried": false,
"info": "我真滴棒棒哒",
"email": "cabcs@163.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "肥",
"lastName": "小"
}
}
#4.2增量修改,只修改单个数据
POST /employee/_doc/1/_update
{
"doc":{
"age":25
}
}
#5删除文档
DELETE /employee/_doc/1
#6.高级查询
#查询所有满足条件的文档
#query:条件
#bool 组合查询
#must 匹配搜索条件 类似and
#match 分词匹配查询
#filter 过滤条件
#range 过滤区间
#trem 匹配字段
#from:第几条数据开始
#size:需要查询出来的几条数据
#_sources:指定查询的字段
#sort:排序
GET /employee/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"info":"java"
}
}
],
"filter": [
{
"term": {
"isMarried":false
}
},
{
"range": {
"age": {
"gte": 20,
"lte": 60
}
}
}
]
}
},
"from": 0,
"size": 2,
"sort": [
{
"age": "desc"
}
]
}
#7.高阶用法
#复杂查询
GET /employee/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"info": "java"
}
},{
"match":{
"name.lastName":"张"
}
}
],
"filter": [
{
"term": {
"isMarried": false
}
},
{
"range": {
"age": {
"gte": 20,
"lte": 60
}
}
}
]
}
},
"from": 0,
"size": 2,
"sort": [
{
"age": "desc"
}
]
}