论文阅读:
Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images
作者声明
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:凤⭐尘 》》https://www.cnblogs.com/phoenixash/p/15474915.html
基本信息
**\1.标题:**Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images
**\2.作者:**Ruigang Niu, Student Member, IEEE, Xian Sun, Senior Member, IEEE, Yu Tian, Wenhui Diao, Kaiqiang Chen, and Kun Fu
**\3.作者单位:**UCAS
**\4.发表期刊/会议:**TGRS
**\5.发表时间:**2020
**\6.原文链接:**https://arxiv.org/abs/2001.02870
Abstract
1.Introduction
2.Related Works
3.METHODOLOGY

A. Overview
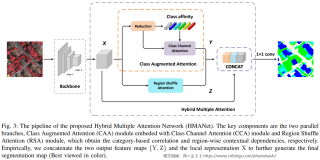
如图3所示,网络架构主要由三个注意力模块组成:Class Augmented attention (CAA)模块、Class Channel attention (CCA)模块和Region Shuffle attention (RSA)模块,其中CAA模块和CCA模块作为网络的上分支嵌入在一起。本文提出的CAA模块旨在提取类级信息,而CCA模块通过类通道加权改进特征重构过程,以更好地进行上下文表示。因此,网络的下分支是RSA模块,与计算远程依赖的原始非本地块相比,大大减少了计算消耗和内存占用。
具体来说,给定一幅输入图像,我们首先将其输入到卷积神经网络(CNN)中,自适应提取特征以更好地表示,该网络采用完全卷积的方式设计[7]。我们以ImageNet数据集上预先训练的ResNet-101作为骨干。特别是在stage-3和stage-4中,我们去掉了最后两个降采样操作,并使用了扩张卷积,对于stage-3和stage-4也称为多网格策略,从而保留了更多的空间信息,在不增加额外参数的情况下,将输出feature map X扩大到输入图像的1/8。然后,主干第四阶段的特征X将被输入两个平行的注意分支。
上分支是嵌入CCA模块的CAA模块。CAA模块用于建模降维后特定类别与对应特征之间的依赖关系,即通过矩阵运算提取输入特征的每个通道与每个类别之间的相似关系。它有助于获得对对象类别信息更敏感的细粒度特征表示,增强网络的识别能力。CCA模块可以定义为类信道信息的自适应特征重构(见Eq.(4)),可以有效改善类信息的特征表示。值得一提的是,CCA模块以CAA模块生成的类亲和矩阵(见Eq.(1))和类注意图作为输入特征,得到自适应加权类亲和矩阵。理想情况下,给定的输入特性映射X ∈ R C × H × W X \in \mathbb{R}^{C\times H\times W}X∈RC×H×W其中C、H和W分别表示特征映射的通道数,高度和宽度。嵌入CCA模块的CAA可以有效地提取类通道相关性,并自适应地从类别视图聚合长期上下文信息,最后按照自注意力机制[11]的模式输出同样大小的特征映射Y∈RC×H×W。
E. Hybrid Multiple Attention Network
Integration of Attention Module. 为了充分利用提出的三个注意力模块,我们进一步以一种串行和并行的方式集成了嵌入CCA模块的CAA模块(见图3上分支)和RSA模块(较低的分支),这两种都与本地特征进行连接。最后,将拼接后的特征输入到最后的卷积,生成最终的分割图。
Loss Function. 除了传统的多类交叉熵损失L c e L_{ce}Lce外,我们在第三阶段后使用辅助监督L a u x L_{aux}Laux来提高性能,按照PSPNet[9]使其更容易进行优化。辅助损失可以表示为:

其中B是最小 batch size;N是每个batch的像素数;K为类别数;p j , k i p^i_{j,k}pj,ki为第i个patch中的第j个像素经过resnet -3阶段后对第k类的预测;I ( g j i = k ) \mathbb{I}\left(g_{j}^{i}=k\right)I(gji=k) 是指示函数如式9所示,当第1个patch(即g j i g^i_jgji)中第j个位置的ground truth属于第k类时取1,其他情况取0。
CAA模块的类别注意力损失L c l s L_{cls}Lcls也作为额外的辅助监督。同样,类别注意力损失可以表述为:

式中a j , k i a^i_{j,k}aj,ki为第k类在第i个patch中的第j个像素的类注意图的响应值;其他定义同上。
最后,我们使用如下三个参数来平衡这些损失:

其中λ1、λ2、λ3分别设为1、0.5、0.4,以平衡损失。注意,对三个损失函数的消融研究以及模型对权重值选择的敏感性将在第四节- d1中详细阐述。
4.Experiments
为了验证我们提出的方法的有效性,我们在两个最先进的航空图像语义分割基准上进行了大量的实验,即ISPRS 2D semantic Labeling Challenging for Vaihingen[41]和Potsdam [42],由高分辨率真正射影片(TOP)和由密集图像匹配技术得到的相应数字表面模型(dsm)组成。在本节中,我们首先介绍数据集和实现细节,然后我们在ISPRS Vaihingen数据集上进行广泛的消融实验。最后,我们在两个数据集上报告我们的结果。
A. Datatsets
Vaihingen. Vaihingen数据集包含33个具有三个光谱波段(红色、绿色、近红外)的正射线形图像块(TOP)拼接,外加一个相同分辨率的归一化数字表面模型(DSM)。数据集的地面采样距离(GSD)为9 cm,平均大小为2494 2064像素,包括5个前景对象类和1个背景类。我们使用基准组织者定义的16幅图像进行训练,17幅图像测试我们的模型[3,30,43,44,45]。注意,我们在实验中不使用DSM。
Potsdam. Potsdam二维语义标注数据集由38幅6000 x 6000像素的高分辨率图像组成,地面采样距离(GSD)为5 cm。数据集提供NIR-R-G-B通道、DSM和标准化的DSM。训练集有24幅图像,测试集有16幅图像,对应Vaihingen基准该数据集中有6个前景类。
B. Evaluation Metrics
为了评估该网络的性能,我们用以下公式计算前景对象类的F1score:

式中,β \betaβ为查准率和查全率的等效因子,设为1。交并比(IoU)和总体精度(OA)定义
其中T P、T N、F P、F N分别为真阳性数、真阴性数、假阳性数和假阴性数。N是像素的总数。
值得注意的是,计算了包括背景在内的所有类别的总体精度,以便与不同模型进行综合比较。此外,评估是使用先前研究提供的数据集中的侵蚀边界的地面真实值进行的。
C. Implementation Details
我们使用在ImageNet[21]上预先训练的ResNet-101[19]作为我们的主干,并采用poly学习率策略,其中遵循前面的工作[13,14,17]在每次迭代后,初始学习率乘以1 − ( i t e r m a x _ i t e r ) 0.9 , p o w e r = 0.9 1-(\frac{iter}{max\_iter})^{0.9},power= 0.91−(max_iteriter)0.9,power=0.9。采用初始学习率为0.01的随机梯度下降(SGD)优化器进行训练。我们采用初始学习率为0.01的随机梯度下降(SGD)优化器进行训练。冲量系数和权重衰减系数分别设为0.9和0.0005。我们用InPlace-ABNSync[46]替换标准BatchNorm,以便在多个gpu上同步BatchNorm的平均值和标准偏差。对于数据增强,我们在所有训练图像上应用随机水平翻转、随机缩放(从0.5到2.0)和随机裁剪。所有数据集的输入大小设置为512x512。我们使用4xNVIDIA Tesla K80 GPU进行80k迭代,batch size大小为4。对于语义分割,我们选择ImageNet上预先训练的FCN (VGG-16)[7]作为我们的基线,并使用ResNet-101[19]基线进行进一步的对比实验。
D. Experiments on Vaihingen Dataset
1) Ablation Study for weight parameters and multiple loss functions: 该模型利用多个损失函数优化学习过程。我们首先进行实验,分析模型对权重参数λ 2 \lambda_2λ2和λ 3 \lambda_3λ3选择的敏感性。具体地,我们将主交叉熵损失(即λ1)的权重参数设为1,只保留其中一个辅助损失函数,以进一步研究λ2和λ3的最优值。λ2和λ3的实验结果见Tab Ⅰ和Ⅱ。结果表明,选取λ2 = 0.5和λ3 = 0.4时,效果最佳。此外,值得一提的是,模型对参数选择并不是特别敏感。因此,为了避免每次实验的训练误差的影响,我们对每个参数值进行了5次实验,并取平均值作为最终结果。
我们进一步研究三个损失函数在Tab Ⅰ和Ⅱ中优化设置后的性能。如Tab Ⅲ所示。两种辅助损失函数对模型训练优化都有一定的改善作用。当我们利用所有的损失函数时,得到了90.98%的总体准确率和82.87%的平均IoU。
2) Ablation Study for Attention Modules: 在提出的HMANet中,在扩张网络的顶部使用三个注意模块,从空间、渠道和类别的角度探索全局语义表征。为了进一步验证注意力模块的性能,我们在TabⅣ中进行了广泛的实验。值得注意的是,为了与基线模型FCN (VGG-16)进行公平比较,我们在本实验中也使用了VGG-16作为HMANet的主干。
如TabIV所示,与基线FCN (VGG-16)相比,提出的注意模块带来显著改善。我们可以看到,仅使用类增强注意模块,总体准确率为89.15%,平均IoU为79.56%,OA和mIoU分别提高了2.64%和6.87%。同时,单独使用区域转移注意力在OA和mIoU中分别比基线高出2.72%和6.96%。此外,当我们将两个相应的注意模块集成在一起时,我们的网络性能进一步提高。最后,当我们整合三个注意模块时,它比其他方法表现得更好,在OA和mIoU中分别比基线提高了3.44%和7.99%。综上所述,我们的方法从不同的角度利用全局上下文,为目标分割带来了很大的好处。
我们进一步研究了三个注意模块的不同聚合方法的效果。如Tab Ⅴ所示,对应于图3的原理图,ResNet101 +Parallel-C-R的性能最好,总体精度为90.98%,平均IoU为82.27%。+Cascade-C-R和+Cascade-R-C两种级联集成模式的总体精度分别为90.88%和90.76%。结果表明,级联集成模式导致实验结果下降。这可能是由于仅在直接串行连接的情况下,区域注意表示不利于类别信息的提取。
3) Ablation Study for Sub-parameters:Ascending ratio. Eq.(4)中引入的ascending ratio α是一个超参数,它允许我们控制特征变换的规模。由于ascending ratio的选择对计算代价没有太大的影响,我们只研究了不同α值范围内的性能。如Tab(VI)所示,我们可以得出结论,在不同超参数选择下,我们的方法始终优于基线,其中α = 150的选择比略好于其他方法。定性地说,α比值是类别信息的比例因子,在控制计算成本的同时可以取一个适中的值。
Effect of the Partition numbers. 我们进一步研究了所提出的区域混合注意模块G和P的不同分区数的影响。我们对G和P的不同选择进行了广泛的实验,并将实验结果列于表Ⅶ中。注意到G和P是相互约束的,即我们只需要确定Gh和Gw的值。我们可以看到,在一定的分区数范围内,性能是稳健的,其中选择Gh = Gw = 8,总体精度达到了最好的90.79%,平均IoU达到了82.49%。根据经验,backbone的输出步幅设置为8,即我们实验中输入特征的高度和宽度为64像素,因此分组的折中选择更有利于每个区域的自注意加权表示。在实践中,使用一个相同的分区号可能不是最优的(由于不同的角色由不同的基础网络和不同的训练设置,例如,输入输出步和大小),所以可以实现优化,进一步改进了分区号满足给定的需求基础架构。
4) Comparison with Context Aggregation Approaches: 我们比较了几种经过验证的上下文聚合方法的性能,即DeepLabv3[8]中的Atrous空间金字塔池(ASPP)、PSPNet[9]中的金字塔池模块(PPM)、CCNet[13]中的RCCA和非本地网络[11]中的Self-Attention。以上实验均在相同的训练/测试设置下进行,以保证公平性。我们在Tab(八)中报告相关结果。具体来说,+PPM比+ASPP在拓展局部接受域方面有更好的表现。+Self-Attention和+RCCA都从特征地图的所有空间位置生成上下文信息,导致有限的对象上下文。相比之下,我们的HMANet从空间、渠道和类别的角度计算全球相关性。结果表明,HMANet方法优于其他上下文聚合方法,证明了从不同角度捕获全局上下文信息的有效性。
5) Efficiency Comparison: 与Self-attention进行比较。如图7所示。首先,我们将RSA模块与标准的自注意机制在GFLOPs计算成本方面进行比较。随着输入特征图的增大,自注意机制的GFLOPs逐渐呈指数增长,而RSA模块的GFLOPs几乎呈线性增长。可以看出,RSA模块在处理高分辨率特征图时比self-attention机制效率更高。
Comparison with Context Aggregation modules and Attention modules. 我们进一步将我们提出的类增强注意模块和区域转移注意模块与ASPP[8,17]、PPM[9]、SA[11]、RCCA[13]、OCR[38]和ISA[15]在效率(包括参数、GPU内存和计算成本(GFLOPs))方面进行了比较。我们在表Ⅸ中报告了结果。值得注意的是,我们在不考虑主干代价的情况下对上述所有方法的代价进行了评估,并包含了3x3卷积降维的代价,以确保比较的公平性。如Tab(IX)所示,与标准的Self-Attention (SA)机制相比,我们的RSA模块减少了20x GPU内存的使用,并在少量参数的情况下显著减少了约77%的FLOPs,这证明了区域表示在捕获远程上下文信息方面的效率。
6) Comparison with State-of-the-art: 我们首先采用一些常见的策略来提高绩效[12,14 47]。(1) DA:随机缩放(0.5 - 2.0)和随机左右翻转的数据扩充。(2)多重网格:我们在ResNet-101的stage-4中使用不同大小(1,2,4)的层次网格。(3) MS + Flip:在推理过程中,对5个图像尺度{0.5,0.75,1.0,1.25,1.5}和左右翻转对应的分割分值图进行平均。
实验结果如表所示(X)。我们依次采用上述策略获得更好的对象表示,总体准确率分别提高了0.19%、0.11%和0.16%。
在Vaihingen测试集中,我们进一步将我们的方法与现有方法进行了比较。值得注意的是,大多数方法采用ResNet101作为主干。结果显示在Tab ⅩⅠ中。可以看出,我们的HMANet (ResNet-101)大大优于其他的上下文聚合方法和基于注意力的方法。此外,我们的HMANet在参数、内存和GFLOPs方面效率更高。特别是,我们的Car的F1得分远高于其他方法,提高了第二好的CCNet 0.93%,证明了捕获基于类别的信息和全球区域相关性的有效性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lz5XCGMf-1635393790977)(https://images.cnblogs.com/cnblogs_com/phoenixash/1649456/o_211027161708_12.png)]
- Visualization Results: 我们在图8中提供了HMANet和基线网络之间的定性比较,包括512x512和1024x1024的pathces。特别是,我们利用红色虚线框来标记那些容易被错误分类的具有挑战性的区域。可以看出,我们的方法在很大程度上优于基线。HMANet可以预测更精确的分割地图,即可以获得更精细的边界信息,并保持目标的一致性,这证明了基于类别的相关性建模和基于区域的表示的有效性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HecE02fG-1635393790981)(https://images.cnblogs.com/cnblogs_com/phoenixash/1649456/o_211027161945_13.png)]
E. Experiments on Potsdam Dataset
为了进一步评估HMANet的有效性,我们在ISPRS Potsdam基准上进行了实验。经验上,我们在Potsdam数据集上采用相同的训练和测试设置。与最先进的方法的数值比较显示在表格(十二)中。值得注意的是,HMANet (ResNet-101)的总体准确率为92.21%,平均IoU的准确率为87.28%。值得注意的是,我们比较了两种可用的输入图像,即RGB和IRRG颜色模式。结果表明,前者可以获得较好的分割图。

定性结果如图9所示。可以看出,HMANet生成的分割图比基线更好。我们用红色虚线框标记改进的区域(颜色最佳查看)。

AIEarth是一个由众多领域内专家博主共同打造的学术平台,旨在建设一个拥抱智慧未来的学术殿堂!【平台地址:https://devpress.csdn.net/aiearth】 很高兴认识你!加入我们共同进步!