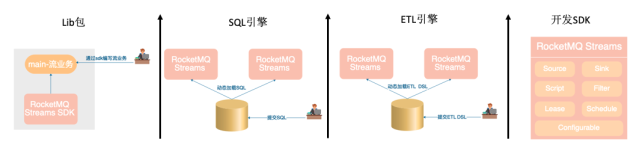
一、背景
流处理是数据集成领域一个重要话题,他能显著减少数据输入和结果输出之间延迟,在对时间延迟敏感的商业场景,例如安全、智能运维、实时推荐,有大量的需求。RocketMQ作为一款消息中间件,已经在业务集成领域展现出巨大价值,但是在数据集成领域还有较大拓展空间。通过支持流处理可以带动RocketMQ进入数据集成领域,拓展RocketMQ的使用范围。
RocketMQ Streams是一款基于RocketMQ为基础的轻量级流计算引擎,具有资源消耗少、部署简单、功能全面的特点,目前已经在社区开源。RocketMQ Streams在阿里云内部被使用在对资源比较敏感,同时又强烈需要流计算的场景,比如在自建机房的云安全场景下,对处理结果的实时性要求非常高,同时考虑到部署和运维成本,轻量级计算引擎就成为一种可行的新选择。
自RocketMQ Streams开源以来,吸引了大量用户调研和试用。但是也存在一些问题,在RocketMQ Streams 1.1.0中,主要针对以下问题做出了改进和优化。
-
面向用户API不够友好,不能使用泛型,不支持自定义序列化/反序列化;
-
代码冗余,在RocketMQ Streams中存在序列化反序列化流处理拓扑模块,RocketMQ Streams作为轻量级流处理SDK,构建好流处理节点之后应该可以直接处理数据,不存在本地保存和网络传输需求。
-
流处理过程不清晰,含有大量缓存逻辑;
-
存在大量支持SQL的逻辑,这部分和SDK方式运行流处理任务的逻辑无关;
在RocketMQ Streams 1.1.0中,对上述问题做出了改进,期望能带来更好的使用体验。同时,重新设计了流处理拓扑构建过程、去掉冗余代码,使得代码更容易被理解。
二、典型使用示例
本地运行下列示例步骤:
-
部署RocketMQ 5.0;
-
使用mqAdmin创建topic;
-
构建示例工程,添加依赖,启动示例。RocketMQ Streams 坐标:
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-streams</artifactId>
<version>1.1.0</version>
</dependency>-
向topic中写入相应数据,并观察结果。
更详细文档请参考:RocketMQ Streams quick start
WordCount
public class WordCount {
public static void main(String[] args) {
StreamBuilder builder = new StreamBuilder("wordCount");
builder.source("sourceTopic", total -> {
String value = new String(total, StandardCharsets.UTF_8);
return new Pair<>(null, value);
})
.flatMap((ValueMapperAction<String, List<String>>) value -> {
String[] splits = value.toLowerCase().split("\\W+");
return Arrays.asList(splits);
})
.keyBy(value -> value)
.count()
.toRStream()
.print();
TopologyBuilder topologyBuilder = builder.build();
Properties properties = new Properties();
properties.put(MixAll.NAMESRV_ADDR_PROPERTY, "127.0.0.1:9876");
RocketMQStream rocketMQStream = new RocketMQStream(topologyBuilder, properties);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("wordcount-shutdown-hook") {
@Override
public void run() {
rocketMQStream.stop();
latch.countDown();
}
});
try {
rocketMQStream.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
窗口聚合
public class WindowCount {
public static void main(String[] args) {
StreamBuilder builder = new StreamBuilder("windowCountUser");
AggregateAction<String, User, Num> aggregateAction = (key, value, accumulator) -> new Num(value.getName(), 100);
builder.source("user", source -> {
User user1 = JSON.parseObject(source, User.class);
return new Pair<>(null, user1);
})
.selectTimestamp(User::getTimestamp)
.filter(value -> value.getAge() > 0)
.keyBy(value -> "key")
.window(WindowBuilder.tumblingWindow(Time.seconds(15)))
.aggregate(aggregateAction)
.toRStream()
.print();
TopologyBuilder topologyBuilder = builder.build();
Properties properties = new Properties();
properties.putIfAbsent(MixAll.NAMESRV_ADDR_PROPERTY, "127.0.0.1:9876");
properties.put(Constant.TIME_TYPE, TimeType.EVENT_TIME);
properties.put(Constant.ALLOW_LATENESS_MILLISECOND, 2000);
RocketMQStream rocketMQStream = new RocketMQStream(topologyBuilder, properties);
rocketMQStream.start();
}
}双流JOIN
下例是窗口JOIN,也支持无窗口类型的双流JOIN。
public class JoinWindow {
public static void main(String[] args) {
StreamBuilder builder = new StreamBuilder("joinWindow");
//左流
RStream<User> user = builder.source("user", total -> {
User user1 = JSON.parseObject(total, User.class);
return new Pair<>(null, user1);
});
//右流
RStream<Num> num = builder.source("num", source -> {
Num user12 = JSON.parseObject(source, Num.class);
return new Pair<>(null, user12);
});
//自定义join后的运算
ValueJoinAction<User, Num, Union> action = new ValueJoinAction<User, Num, Union>() {
@Override
public Union apply(User value1, Num value2) {
...
}
};
user.join(num)
.where(User::getName)
.equalTo(Num::getName)
.window(WindowBuilder.tumblingWindow(Time.seconds(30)))
.apply(action)
.print();
TopologyBuilder topologyBuilder = builder.build();
Properties properties = new Properties();
properties.put(MixAll.NAMESRV_ADDR_PROPERTY, "127.0.0.1:9876");
RocketMQStream rocketMQStream = new RocketMQStream(topologyBuilder, properties);
rocketMQStream.start();
}
}
Java对象支持
public class Demo {
public static void main(String[] args) {
StreamBuilder builder = new StreamBuilder("demo");
builder.source("user", new KeyValueDeserializer<Void, User>() {
@Override
public Pair<Void, User> deserialize(byte[] total) throws Throwable {
//自定义反序列化
}
})
.keyBy(User::getAge)
.count(User::getName)
.toRStream()
.print();
TopologyBuilder topologyBuilder = builder.build();
Properties properties = new Properties();
properties.put(MixAll.NAMESRV_ADDR_PROPERTY, "127.0.0.1:9876");
RocketMQStream rocketMQStream = new RocketMQStream(topologyBuilder, properties);
rocketMQStream.start();
}
}三、方案设计

RocketMQ Streams作为客户端SDK直接被使用方依赖,从而获得流处理能力。他从RocketMQ的source topic中读取数据,经过处理后将结果写回到RocketMQ的sink topic中。这种架构的好处是业务无需添加任务第三方依赖,直接从数据源读取数据即可获得流处理能力。
流处理拓扑构建过程
在使用者书写上述及连表达式时,发生第一次构建,即逻辑节点的添加,前后算子具有父子关系,构建后形成逻辑节点,多个逻辑节点形成链表。
逻辑构建结束后,调用StreamBuilder#build()方法进行第二次构建,将逻辑节点中可能包含的多个真实节点添加拓扑,形成处理拓扑图。
经过两次两次构建后,处理拓扑已经完整。但是为了区分不同topic使用不同拓扑处理,需要在数据来临前的重平衡阶段,创建真实数据处理节点,这是第三次构建。
逻辑节点构建(第一次构建)

逻辑节点本身不包括实际操作,但是可由逻辑节点继续构建出实际节点,一个逻辑节点可能包含一实际节点,也可能包含多个实际节点,例如count逻辑算子不仅仅包含累加这个实际操作,累加前需要对相同key的数据路由到同一计算实例上,因此还需要包含sink、source两个实际节点,但是这些只会在构建实际节点时体现出来,不会在添加逻辑节点阶段体现。
每个逻辑节点都是GraphNode的子类,构建时,将子节点算子加入父节点child集合中,将父节点加入子节点parent集合中。这个构建过程中使用Pipeline均为同一个实例。随着构建过程,将逻辑节点加入到pipeline中,父子节点形成以root节点为根节点的链表。
添加逻辑节点逻辑:
@Override
public <OUT> GroupedStream<K, OUT> map(ValueMapperAction<V, OUT> mapperAction) {
//1、确定节点名称
//2、实现Supplier类,实现数据处理逻辑
//3、实例化逻辑节点类GraphNode
//4、将逻辑节点GraphNode添加到pipeline中形成链表
}可以看到逻辑节点的添加非常通用,实现不同功能的算子,只需要实现算子对应的数据实际处理逻辑即可,如果将新增算子形成拓扑图等等后续工作完全不用关心,降低了新算子开发的门槛。
在逻辑节点的构建过程中,有两类比较特殊的算子,一个是实现数据分组的shuffle算子,一个是实现双流聚合的Join算子。
shuffle逻辑算子的功能是将含有相同key的数据发送到同一个队列中,方便后续算子对相同key的数据进行统计。他通常是keyBy后面紧跟的算子,例如keyBy("年纪").count(),那么count就是一个shuffle算子类型。shuffle逻辑算子包含三个实际处理过程:
-
将数据按照Key的hash%queueNum发送到对应队列;
-
从RocketMQ中拉取上述数据到本地;
-
按照shuffle节点中定义的逻辑进行处理,例如累加。
Join算子的功能是实现双流聚合,将两个数据流聚合成一个。

Join拓扑图
在左流和右流上添加KeyBy算子,对左流和右流进行分别过滤;之后在左流和右流上分别添加标签节点,在数据中添加此数据是左流还是有流,之后将两个标签节点,指向一个共同的Join节点,数据在此完成汇聚,按照使用者给定的ValueJoinAction节点处理。
Join使用方式:
StreamBuilder builder = new StreamBuilder(jobId);
RStream<T> leftStream = builder.source(...);
RStream<V> rightStream = builder.source(...);
ValueJoinAction<T, V, R> action = new ValueJoinAction<T, V, R>(){...};
leftStream.join(rightStream)
.where(左流字段)
.equalTo(右流字段)
.apply(action)
.print();Join实现伪代码:
//左右流按照各自字段分组,含有相同key的字段会被回写到同一个队列里面;
GroupedStream<K, V1> leftGroupedStream = leftStream.keyBy(左流字段);
//因为后面左右流数据会在一起处理,为了区分数据来源,在数据中添加标记是左流还是右流
leftGroupedStream.addGraphNode(addTag);
//获取leftGroupedStream最后的逻辑节点
GraphNode leftLast = leftGroupedStream.getLast();
GroupedStream<K, V1> rightGroupedStream = leftStream.keyBy(右流字段);
rightGroupedStream.addGraphNode(addTag);
GraphNode rightLast = rightGroupedStream.getLast();
//数据汇聚节点
ProcessorNode<OUT> commChild = new ProcessorNode(name, temp, “聚合数据实际操作”);
commChild.addParent(leftLast);
commChild.addParent(rightLast);
//统一数据流
RStreamImpl commRStream = new RStreamImpl<>(Pipeline, commChild);
//继续在统一数据流上操作
commRStream...物理构建(第二次构建)
构建逻辑节点完毕后,从ROOT节点开始遍历,调用GraphNode逻辑节点addRealNode方法,构建真实节点构建工厂类

在第二次构建实际节点过程中,会对逻辑节点进行拆解,对于大多数逻辑节点,只需要构建一个实际节点,但是对于某些特殊的逻辑节点需要构建多个实际节点才能与之对应,例如shuffle类型逻辑节点,他需要包含三个实际节点:发送数据节点、消费数据节点、处理数据节点。shuffle类型逻辑节点父节点必须是GroupBy,例如上图所示的count是shuffle节点,Window节点也可以是逻辑节点。 第二次构建并不会直接生成处理数据的Processor,而是产生ProcessorFactory对象。为什么不生成直接能处理数据的Processor对象呢?因为一个RocketMQ Streams实例需要同时拉取不同队列进行流计算,为了能将不同队列的流计算过程区别开,针对每个队列会由独立的Processor实例进行处理,因此第二次构建仅仅构建出ProcessorFactory,在重平衡确定流处理实例要拉去哪些队列后,在由ProcessorFactory实例化Processor。
第三次构建
客户程序依赖RocketMQ Streams获得流计算能力,因此客户程序本质上是就是一个RocketMQ Client(见6.1.16方案架构图)。在RocketMQ Client发生重平衡时,会将RocketMQ Server所包含的队列在客户端中重新分配,第三次构建,也就是右ProcessorFactory实例化Processor,就发生在重平衡发生后,拉取数据前。第三次真实的构建出了处理数据的Processor,并将子节点Processor添加进入父节点Processor中。
数据处理过程
状态恢复

流处理过程中产生的计算状态保存、恢复涉及到流处理过程的正确性。在流处理实例宕机的情况下,该流处理实例上消费的队列会被重平衡到其他流处理实例上。如果对该队列进行了有状态计算,那么产生的状态也需要在新的流计算实例上恢复。如上图中,Instance1宕机,他消费的MQ2和MQ3被分别迁移到Instance2和Instance3上,MQ2和MQ3对应的状态(紫色和蓝色)也需要在Instance2和Instance3上恢复出来。
-
存储介质
使用本地RocksDB,远程RocketMQ的组合,作为状态存储介质。流计算在计算状态时,RocksDB在使用有限内存情况作为状态的临时本地存储于算子交互,在计算结束后提交消费位点时将本次计算产生的状态一并写入RocketMQ中。消费位点提交、计算结果写出、状态保存需要保持原子状态,这一内容在后面流计算正确性中讨论。
-
状态持久化存储
RocketMQ作为消息临时存储,存在数据最大过期时间,一旦过期后,数据会被删除。但是状态存储介质本质上是以KV方式存储数据,不希望KV数据随着时间过期而被删除。因此,使用Compact topic作为状态存储,他会对同一队列的数据按照Key对数据进行压缩,相同Key的数据只保留offset最大的一条。
//key如果决定数据被发送到某个Broker的哪个队列
int queueId = hash(key) % queueNum但是在RocketMQ中队列数会随着Broker扩缩容而增加或者减少,扩缩Broker数量前后,相同的Key可能被发送到不同的队列,那么按照上述规则进行Compact后得到的最新值就是错误的,使用Compact topic作为KV存储就失去了意义。
因此在状态topic是Compact topic的基础上,再将状态topic创建为Static topic(Logic Queue),即状态topic即是Compact topic也是Static topic。这样才能解耦队列数量与Broker数量,使队列数量在扩缩Broker情况下仍然不变,保证含有相同Key的数据能被发送到同一队列中。
-
状态重放
从被迁移状态队列拉取数据到本地进行重放,需要从队列头开始消费,相同Key的数据只保留offset最大的数据,形成K-V状态对,放入本地临时存储RocksDB中;
-
状态topic与source topic对应关系
因为状态topic中的队列会随着source topic队列迁移而迁移,保证对source topic队列中数据进行有状态处理得到正确的结果,因此在队列层面,状态topic与source topic应该是一一对应的关系。即状态topic名称与source topic名称一一对应,状态topic的队列数量等于source topic队列数量,source topic队列的流计算状态保存在相同queueId序号状态topic队列中。
数据处理

-
图中黑色线表示控制流,黄色线表示数据流;rebalance部分先于litePull部分进行
-
重平衡部分:
-
根据分配到的队列,到相应状态topic的相同QueueId中从头拉取数据,到本地重放,获得KV状态对,放入到本地RocksDB中。
-
根据数据源topic,构建对应的数据处理器processor(即第三次构建过程),保存起来;
-
数据处理部分:
-
使用litePull模式拉取数据,可以独立控制消费位点提交;
-
数据反序列化;
-
使用topic查找processor;
-
将processor的子节点保存起来(子节点在第三次构建过程中添加);
-
数据向上下文StreamContext中传递,由他将数据路由到下游节点;
-
数据处理前,现将下游节点的子节点保存起来供后续查找;
-
数据处理,如果有状态算子则与RocksDB交互,如果还有下游节点则继续进入StreamContext,如果没有下游节点则结束处理。
数据每次到下游节点前,先进入StreamContext中,由它统一向下游节点传递数据。StreamContext中包含了处理数据所需要的所有信息,包括数据来源、状态存储、下游子节点等等;
StreamContext不断递归迭代source的子节点,最终数据会被拓扑图上所有节点处理,知道最后节点将结果数据写出。
正确性实现

计算正确性由数据完整性和引擎一致性共同保证。如果将流计算过程视为一个函数映射:output = f(input),上述模型中,数据完整性是对于无界、无序数据集的约束,即明确了输入input,引擎数据一致性则明确了数据处理过程f,因此输出就是确定的。
一致性

使用生产者事务,将数据处理、state/sink数据写出、位点提交放到一个事务中。
tx.begin();
try{
process();
sendOffset();
sendState();
sendSink();
}catch{
tx.rollback();
}
tx.end();目前因为RocketMQ缺少生产者事务支持,这块功能还未实现。但是具备实现基础:
-
source到sink这一过程被拆解成两个过程,source -> shuffle和shuffle -> sink,将shuffle和sink操作等同起来。整个过程可简化成一个不含shuffle的source -> sink过程;
-
stateStore和sink使用同一个producer;保证提交消费位点、保存状态数据、写出结果数据是一个事务,保证了端到端的一致性;
具体实现需要RocketMQ支持生产者事务以后再讨论。
完整性
完整性是指对于流处理这种无界数据流来说,如何定义输入数据是完整的,何时能触发计算。RocketMQ Streams中使用限宽时间方案来实现数据完整性。
流元素的时间减去一个固定长度的时间来量化,比如流元素本身的事件时间是5,宽限设定是2,当算子接收到该数据时,表示事件时间小于3的数据已经全部达到。由此得到事件时间小于3的数据是完整的,可以触发计算。这种方案优点是实现简单,不用在流中嵌入额外元信息;缺点是可能因为数据被过滤导致后续算子无法接收到时间信息;

上图所示,限宽为2,四条数据时间分别是t=5,5=7,t=3经过Operator2时,表达含义为:
RocketMQ Stream中,在source处产生数据时间和watermark,EVENT_TIME/PROCESSING_TIME决定数据时间,数据时间减去限宽时间决定watermark,且watermark只会增加不会减少,watermark随着数据一起下向下游传递。对于有状态算子,需要触发小于watermark的所有状态。如果即将处理数据的时间小于watermark,则认为是迟到数据。
四、后续规划
RocketMQ Streams目前仍然处于发展之中,他基于RocketMQ 5.0提供的数据集成特性,在后续一段时间中他也会随着5.0特性发展而发展,目前来看还需要强化的特性包括:
-
结合RocketMQ 生产者事务,完整的实现流处理端到端一致性;
-
结合RocketMQ Batch Producer功能,提升流处理拉取数据效率;
-
新增其他必要算子支持;
目前RocketMQ Streams 已经在github开源,1.1.0版本已经发布,真诚要求大家调研、试用,并提出反馈。同时,社区仓库中也发布了一些good first issues,欢迎对开源有兴趣的同学尝试提交PR解决。