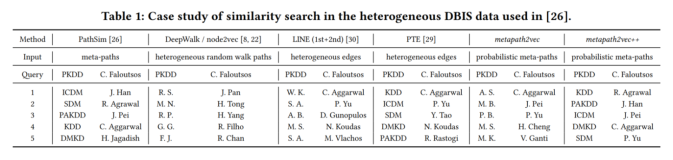
1. 模型构造思路
本文提出了一个新的MP系GNN模型PGE,结合了拓扑结构和图在节点和边上的属性信息,在聚合邻居信息时是有偏的、根据邻居节点和边对中心节点的相似程度来进行聚合的。
感觉就是一个常见的那个年代(喂GNN的发展已经快到2019年的论文算是古董了)的GNN模型。
标题中所谓property graph就是有属性的图,属性可以在节点或边上。
2. Notation与模型介绍
2.1 Notation
略,待续。
2.2 节点相似性和节点嵌入

2.3 PGE模型步骤
大致流程为:
①property-based node clustering
仅基于属性对节点进行聚类,将节点聚成k类。(可以使用K均值、DBSCAN之类的标准聚类方法)
这样对每个节点来说,都能得到与之在属性上相似与不相似的邻居节点(拓扑上的相似性用邻居信息衡量)。
②biased neighborhood sampling
biased是本文相比于GraphSAGE方法的创新部分。
对每个节点,我们对其相似节点(即在①中属于同一类)的节点置bias b s(1),对不相似节点置bias b d(这个bias的有效性在section4部分解释,具体的取值好像是做实验调出来的),将所有邻居的bias归一化后从中抽样出固定数量的邻居,得到sampled graph G S
③neighborhood aggregation
2层GNN:

p v 是原始特征向量,A ( ⋅ ) 是concatenate operation
2.4 PGE模型对有向边关系的支持

具体见论文3.3部分,略待补。
2.5 PGE模型算法

就按着步骤走,还挺清晰的。
2.6 bias部分的有效性证明
没看,待补。
3. 详细的数学推导和证明
没看,待补。
4. 实验结果
4.1 baseline
本文将baseline分成三类:
random walk based on skipgram – DeepWalk and node2vec
graph convolutional networks – GCN
neighbor aggregation based on weight matrices – GraphSAGE
4.2 数据集
略,待补。
4.3 实验设置
略,待补。
4.4 实验结果
4.4.1 节点分类任务

具体略,待补。
4.4.2 链接预测任务

没看到有说表示向量多少维?
损失函数应该是 cross entropy loss with negative sampling(在论文3.2.3部分提及)。
具体略,待补。
4.4.3 参数敏感性检验
4.4.3.1 epoch

具体略,待补。
4.3.3.2 Biases and Cluster Number
固定 b s ,调整 b d ;用K均值聚类以方便调整cluster number

最终结论是选择较小的K(接近平均度数)和较大的 b d 对实验比较合适。
具体略,待补。
5. 代码实现和复现
5.1 论文官方实现
TensorFlow……
yue!
就浏览了一下,还没看,待补。我看这意思是很多代码是参考GraphSAGE的,那篇的代码我也没看。而且我看了一下issue没人回答,作者不知是转行了还是咋,感觉不维护了,提问可能也没人回。所以大概就不看了。如果有需要再说。
5.2 PyG官方实现
没有。
5.3 我自己写的复现
没写。