本文主要介绍如何基于阿里云百炼平台快速在10分钟为您的网站添加一个 AI 助手。我们基于阿里云百炼平台的能力,以官方帮助文档为参考,搭建了一个以便全天候(7x24)回应客户咨询的AI助手,介绍了相关技术方案和主要代码,供开发者参考。

本文介绍了阿里云百炼的CosyVoice语音合成大模型及其高并发调用优化方案。CosyVoice支持文本到语音的实时流式合成,适用于智能设备播报、音视频创作等多种场景。为了高效稳定地调用服务,文章详细讲解了WebSocket连接复用、连接池和对象池等优化技术,并通过对比实验展示了优化效果。优化后,机器负载降低,任务耗时减少,网络负载更优。同时,文章还提供了异常处理方法及常见问题解决方案,帮助开发者更好地集成和使用SDK。
在数字化时代,线上购物已成为消费者生活中不可或缺的消费方式,而消费者的购物习惯和需求逐渐呈现多样化的趋势,为了帮助商家全天候、自动化地满足顾客的购物需求,本方案将详细介绍如何基于商品内容构建一个智能商品导购助手。
聚焦于企业部署 DeepSeek 的应用需求,本文介绍了模型权重下载及多种部署方案,还阐述了大模型应用落地的常见需求,帮助用户逐步提升模型应用效果。
通义灵码新上的外挂 Project Rules 获得了开发者的一致好评:最小成本适配我的开发风格、相当把团队经验沉淀下来,是个很好功能……
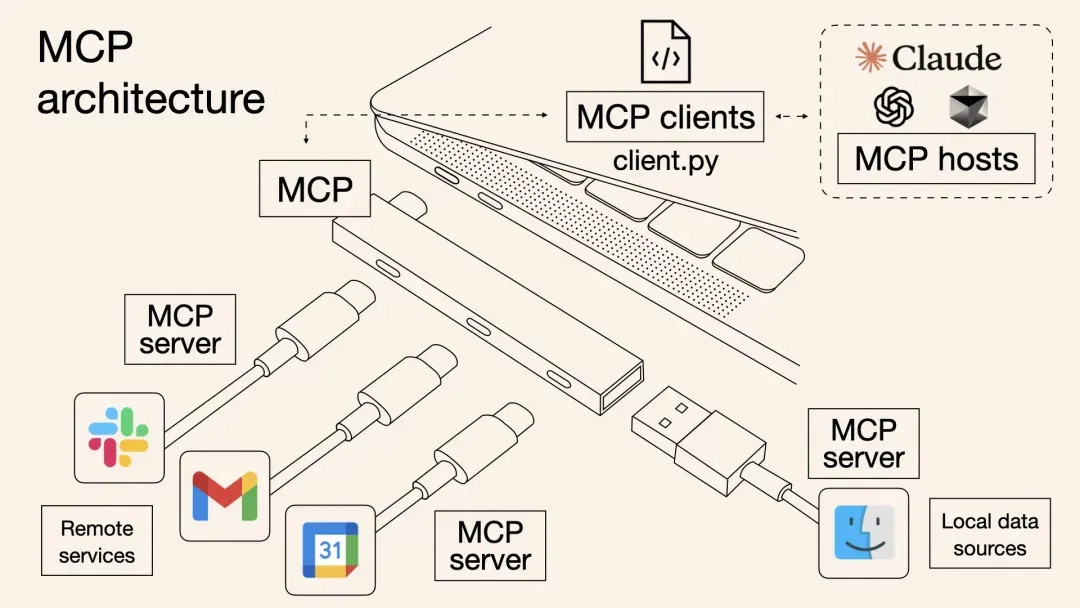
本文介绍了一种基于阿里云计算巢的一站式MCP工具解决方案,解决了传统MCP工具集成中的效率低下、调用方式割裂和动态管理困难等问题。方案通过标准化协议实现多MCP工具批量部署,提高云资源利用率,并支持OpenAPI与MCP双通道调用,使主流AI助手如Dify、Cherry Studio等无缝接入。内容涵盖背景、原理剖析、部署使用实战及问题排查,最后强调MCP协议作为“通用语言”连接数字与物理世界的重要性。
XTuner和魔搭社区(SWIFT)合作引入了一项长序列文本训练技术,该技术能够在多GPU环境中将长序列文本数据分割并分配给不同GPU,从而减少每个GPU上的显存占用。通过这种方式,训练超大规模模型时可以处理更长的序列,提高训练效率。魔搭社区的SWIFT框架已经集成了这一技术,支持多种大模型和数据集的训练。此外,SWIFT还提供了一个用户友好的界面,方便用户进行训练和部署,并且支持评估功能。
本文首先讲述了什么是单元测试、单元测试的价值、一个好的单元测试所具备的原则,进而引入如何去编写一个好的单元测试,通义灵码是如何快速生成单元测试的。
通义灵码2.0引入了DeepSeek V3与R1模型,新增Qwen2.5-Max和QWQ模型,支持个性化服务切换。阿里云发布开源推理模型QwQ-32B,在数学、代码及通用能力上表现卓越,性能媲美DeepSeek-R1,且部署成本低。AI程序员功能涵盖表结构设计、前后端代码生成、单元测试与错误排查,大幅提升开发效率。跨语言编程示例中,成功集成DeepSeek-R1生成公告内容。相比1.0版本,2.0支持多款模型,丰富上下文类型,具备多文件修改能力。总结显示,AI程序员生成代码准确度高,但需参考现有工程风格以确保一致性,错误排查功能强大,适合明确问题描述场景。相关链接提供下载与原文参考。

