阿里云开源 Spring AI Alibaba,旨在帮助 Java 开发者快速构建 AI 应用,共同构建物理新世界。

本文章旨在帮助读者了解并掌握大模型多模态技术的实际应用,特别是如何构建基于多模态的实用场景。文档通过几个具体的多模态应用场景,如拍立淘、探一下和诗歌相机,展示了这些技术在日常生活中的应用潜力。
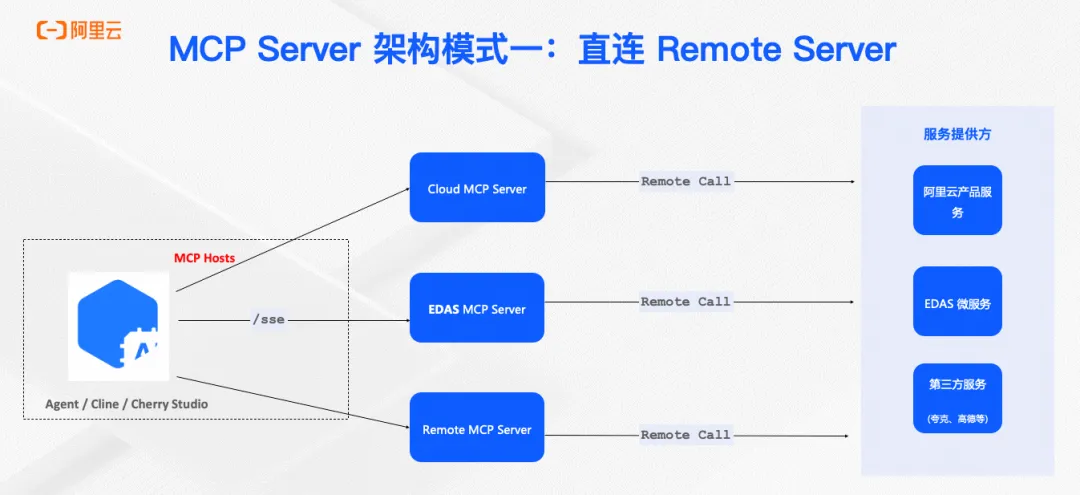
本文深入探讨了Model Context Protocol (MCP) 在企业级环境中的部署与管理挑战,详细解析了五种主流MCP架构模式(直连远程、代理连接远程、直连本地、本地代理连接本地、混合模式)的优缺点及适用场景,并结合Nacos服务治理框架,提供了实用的企业级MCP部署指南。通过Nacos MCP Router,实现MCP服务的统一管理和智能路由,助力金融、互联网、制造等行业根据数据安全、性能需求和扩展性要求选择合适架构。文章还展望了MCP在企业落地的关键方向,包括中心化注册、软件供应链控制和安全访问等完整解决方案。

文章探讨了AI Agent的发展趋势,并通过一个实际案例展示了如何基于MCP(Model Context Protocol)开发一个支持私有知识库的问答系统。

