针对问题咨询场景中出现大量相关领域的问题,PAI提供了智能客服对话系统解决方案,以降低客户等待时间和人工客服成本。本文以汽车售前咨询业务领域为例,介绍如何基于人工智能算法,快速构建智能客服对话系统。

本文首先讲述了什么是单元测试、单元测试的价值、一个好的单元测试所具备的原则,进而引入如何去编写一个好的单元测试,通义灵码是如何快速生成单元测试的。
Nacos社区推出MCP Router与MCP Registry开源解决方案,助力AI Agent高效调用外部工具。Router可智能筛选匹配的MCP Server,减少Token消耗,提升安全性与部署效率。结合Nacos Registry实现服务自动发现与管理,简化AI Agent集成复杂度。支持协议转换与容器化部署,保障服务隔离与数据安全。提供智能路由与代理模式,优化工具调用性能,助力MCP生态普及。
本期文章,我们将向大家展示如何使用AgentScope中构建和使用具有RAG功能的智能体,创造AgentScope助手群,为大家解答和AgentScope相关的问题。
写这篇文章的初衷:作为一个AI小白,把我自己学习大模型的学习路径还原出来,包括理解的逻辑、看到的比较好的学习材料,通过一篇文章给串起来,对大模型建立起一个相对体系化的认知,才能够在扑面而来的大模型时代,看出点门道。
本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。

探讨了 SLS 中增强数据安全的几种方式:权限精细化管控有效减少了潜在安全风险;接入层脱敏技术阻止敏感数据落库,提升了隐私保护;StoreView 字段集控制通过限制查询数据范围,降低数据泄露损害。智能监控系统提供实时监测,快速识别并阻断异常拖库行为,为企业提供了迅速响应和抵御威胁的能力。

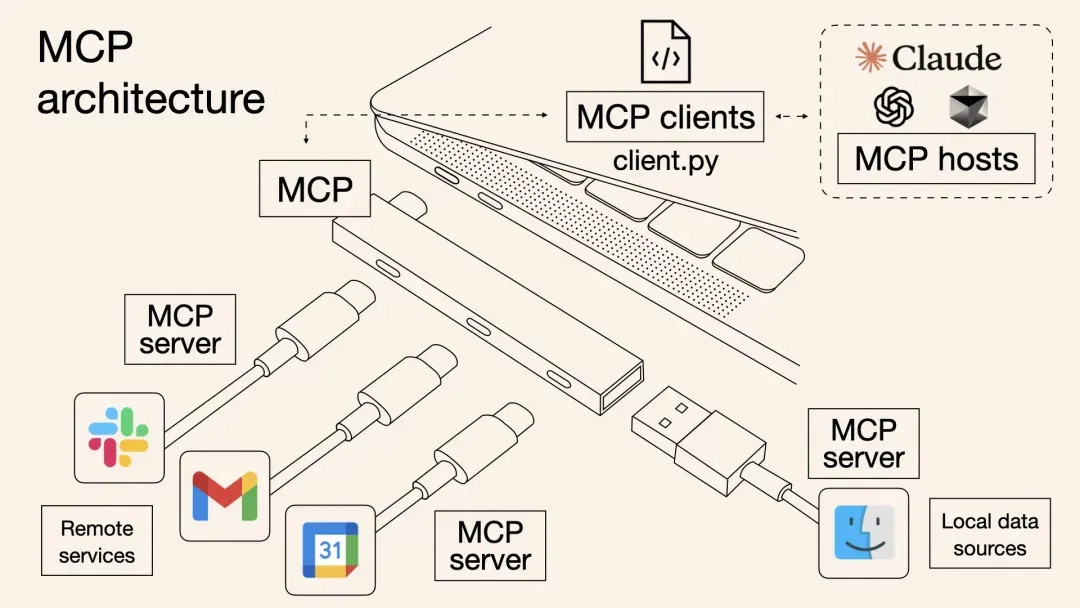
本文介绍了一种基于阿里云计算巢的一站式MCP工具解决方案,解决了传统MCP工具集成中的效率低下、调用方式割裂和动态管理困难等问题。方案通过标准化协议实现多MCP工具批量部署,提高云资源利用率,并支持OpenAPI与MCP双通道调用,使主流AI助手如Dify、Cherry Studio等无缝接入。内容涵盖背景、原理剖析、部署使用实战及问题排查,最后强调MCP协议作为“通用语言”连接数字与物理世界的重要性。