阿里云OpenSearch LLM版推出DeepSearch技术,实现从RAG 1.0到RAG 2.0的升级。基于多智能体协同架构,支持复杂推理、多源检索与深度搜索,显著提升问答准确率,助力企业智能化升级。
本文章旨在帮助读者了解并掌握大模型多模态技术的实际应用,特别是如何构建基于多模态的实用场景。文档通过几个具体的多模态应用场景,如拍立淘、探一下和诗歌相机,展示了这些技术在日常生活中的应用潜力。
本文围绕某线上客户部署DeepSeek-R1满血版模型时进行多次压测后,发现显存占用一直上升,从未下降的现象,记录了排查过程。

ComfyUI 是一款基于节点工作流稳定扩散算法的全新 WebUI,相对于传统的 WebUI,ComfyUI 的部署和学习曲线较陡峭,函数计算基于 Serverless 应用中心开发“ComfyUI 应用模版”,简化开发者的部署流程,帮助简单、快捷实现全新而精致的绘画体验,点击本文查看一键部署 ComfyUI 的方法。
文章探讨了AI Agent的发展趋势,并通过一个实际案例展示了如何基于MCP(Model Context Protocol)开发一个支持私有知识库的问答系统。

本文介绍了通过MCP(Model Context Protocol)结合通义千问大模型实现跨平台、跨服务的自动化任务处理方案。使用Qwen3-235B-A22B模型,配合ComfyUI生成图像,并通过小红书等社交媒体发布内容,展示了如何打破AI云服务的数据孤岛。具体实践包括接入FileSystem、ComfyUI和第三方媒体Server,完成从本地文件读取到生成图像再到发布的全流程。 方案优势在于高可扩展性和易用性,但也存在大模型智能化不足、MCP Server开发难度较大及安全风险等问题。未来需进一步提升模型能力、丰富应用场景并解决安全挑战,推动MCP在更多领域落地。


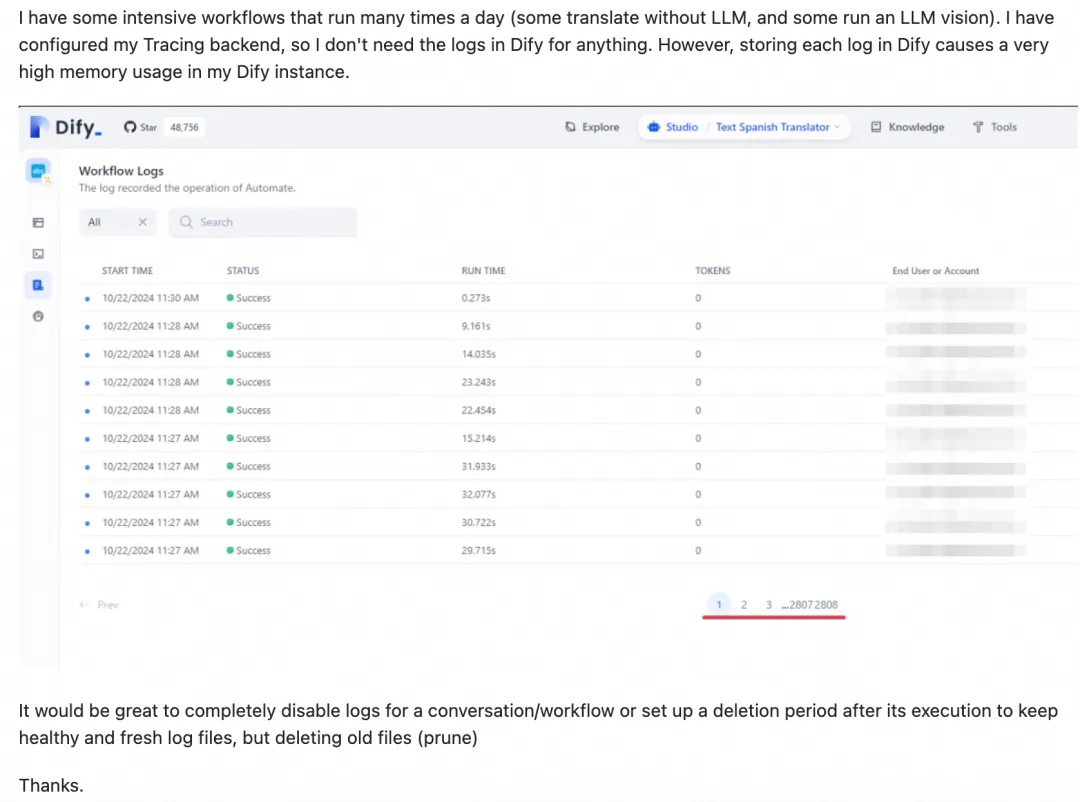
Dify是一款开源的大模型应用开发平台,支持通过可视化界面快速构建AI Agent和工作流。然而,Dify本身缺乏定时调度与监控报警功能,且执行记录过多可能影响性能。为解决这些问题,可采用Dify Schedule或XXL-JOB集成Dify工作流。Dify Schedule基于GitHub Actions实现定时调度,但仅支持公网部署、调度延时较大且配置复杂。相比之下,XXL-JOB提供秒级调度、内网安全防护、限流控制及企业级报警等优势,更适合大规模、高精度的调度需求。两者对比显示,XXL-JOB在功能性和易用性上更具竞争力。