
modelscope-funasr这是哪里的问题呢 ?fsmn-vad 8k的模型,对于测试样例仅切分为两段,自己本地的录音也只返回一个片段。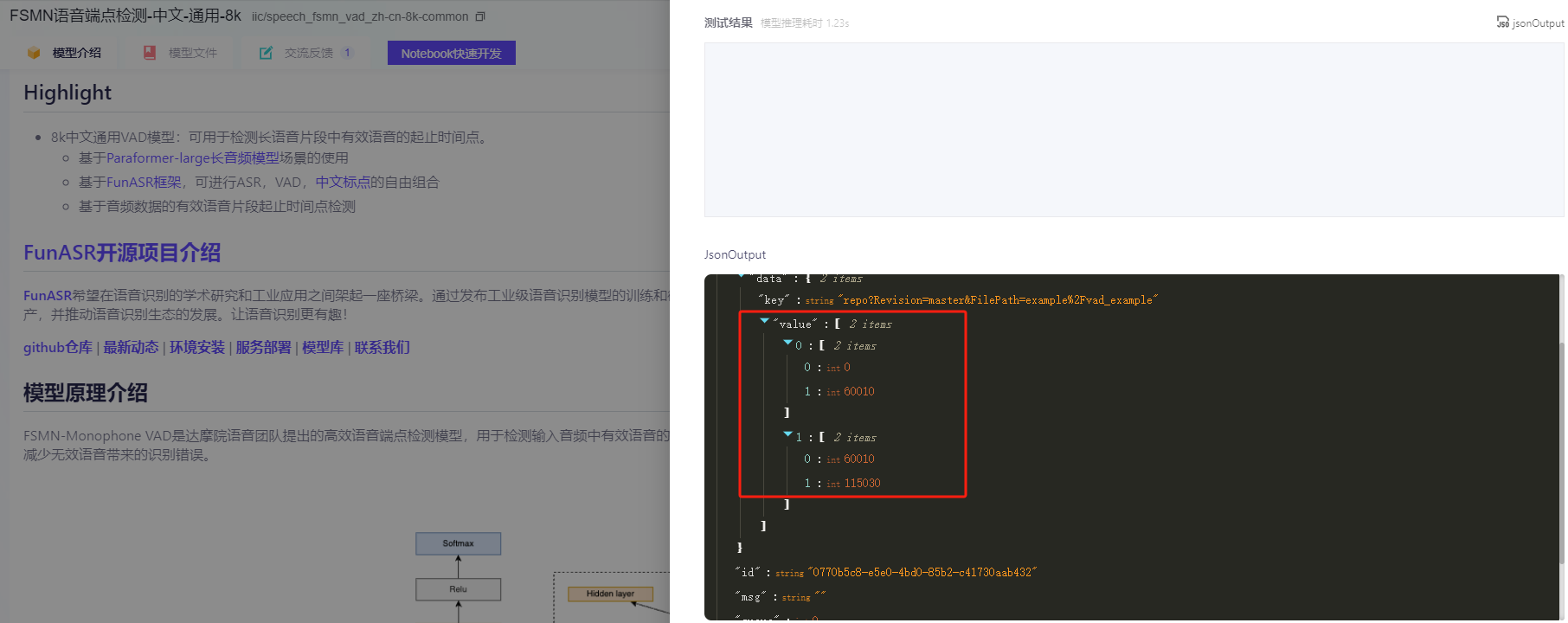
可以调整 vad.yaml 文件中的参数,如 max_end_silence_time(尾部连续检测到多长时间静音进行尾点判停)和 speech_noise_thres(speech 的得分减去 noise 的得分大于此值则判断为 speech)
可以考虑在 FunASR 的 GitHub 问题跟踪系统中提交一个详细的 issue,包括您的模型版本、代码示例、错误信息等,以便社区或者开发者能够更好地帮助您
。

